
pandas.DataFrame.drop_duplicates 用法介绍
如下所示:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据
keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除;last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有两行数据重复,把两行数据都删除,而不是保留其中一行。默认参数是first。
补充知识:python3删除数据重复值,只保留第一项。drop_duplicates()函数使用介绍
原始数据如下:

f 列的前3个数据都有重复项,现在要将重复值删去,只保留第一项或最后一项。
使用drop_duplicates()
drop_duplicates(self, subset=None, keep='first', inplace=False)
subset :如['a']代表a列中的重复值全部被删除
keep:保留第一个值,参数为first,last
inplace:是否替换原来的df,默认为False
import pandas as pd
data = pd.read_table("C:/Users/xujinhua/Desktop/aa/a.txt",header=None, names=['a','b','c','d','e','f','g'])
#读取文件数据,并将列命名为abcdef
data.drop_duplicates(subset='f', keep='first', inplace=True)
print(data)
结果:
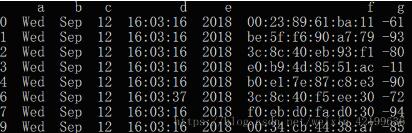
可以看到 f 列中的重复值都被删除,且保留了第一项
以上这篇pandas.DataFrame.drop_duplicates 用法介绍就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了Django零基础入门之自定义过滤器及模板中的使用,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-09-09
这篇文章主要介绍了Django零基础入门之自定义过滤器及模板中的使用,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-09-09
我对PyTorch dataloader里的shuffle=True的理解
这篇文章主要介绍了我对PyTorch dataloader里的shuffle=True的理解,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05
python pymysql链接数据库查询结果转为Dataframe实例
这篇文章主要介绍了python pymysql链接数据库查询结果转为Dataframe实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 这篇文章主要介绍了Python基于locals返回作用域字典,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10
这篇文章主要介绍了Python基于locals返回作用域字典,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10 这篇文章主要介绍了Python环境的安装与卸载流程,本文分步骤通过图文并茂的形式给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了Python环境的安装与卸载流程,本文分步骤通过图文并茂的形式给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了tensorflow中的数据类型dtype用法说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05
这篇文章主要介绍了tensorflow中的数据类型dtype用法说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05
苹果Macbook Pro13 M1芯片安装Pillow的方法步骤
Pillow作为python的第三方图像处理库,提供了广泛的文件格式支持,本文主要介绍了苹果Macbook Pro13 M1芯片安装Pillow,具有一定的参考价值,感兴趣的可以了解一下2021-11-11 这篇文章主要介绍了Pytorch框架之one_hot编码函数解读,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
这篇文章主要介绍了Pytorch框架之one_hot编码函数解读,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 这篇文章主要介绍了python处理二进制数据的方法,涉及Python针对二进制数据的相关操作技巧,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了python处理二进制数据的方法,涉及Python针对二进制数据的相关操作技巧,需要的朋友可以参考下2015-06-06
Django项目定期自动清除过期session的2种方法实例
如果用户主动退出,session会自动清除,如果没有退出就一直保留,记录数越来越大,要定时清理没用的session,下面这篇文章主要给大家介绍了关于Django项目定期自动清除过期session的2种方法,需要的朋友可以参考下2022-08-08










最新评论