
Hadoop中namenode和secondarynamenode工作机制讲解
更新时间:2019年01月11日 10:11:20 作者:qq_43193797
今天小编就为大家分享一篇关于Hadoop中namenode和secondarynamenode工作机制讲解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧
1)流程
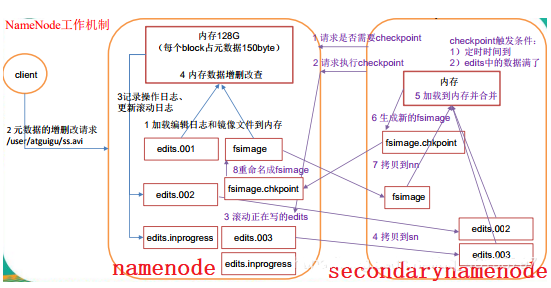
2)FSImage和Edits
nodenode是HDFS的大脑,它维护着整个文件系统的目录树,以及目录树里所有的文件和目录,这些信息以俩种文件存储在文件系统:一种是命名空间镜像(也称为文件系统镜像,File System Image,FSImage),即HDFS元数据的完整快照,每次NameNode启动的时候,默认会加载最新的命名空间镜像,另一种是命令空间镜像的编辑日志(Edit log)。
FSImage文件其实是文件系统元数据的一个永久性检查点,但并非每一个写操作都会更新这个文件,因为FSImage是一个大型文件,如果频繁地执行写操作,会使系统运行极为缓慢。解决方案是NameNode只将改动内容预写日志,即写入命名空间镜像的编辑日志.随着时间的推移,编辑日志会变得越来越大,那么一旦发生故障,将会话费非常多的时间来回滚操作,所以就像传统的关系数据库一样,需要定期地合并FSImage和编辑日志。如果由NameNode来做合并操作,那么NameNode在为集群提供服务时可能无法提供足够的资源,为了彻底解决这一问题,SecondaryNameNode应允而生。
3)第一阶段:namenode 启动
- (1)第一次启动 namenode 格式化后,创建 fsimage 和 edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
- (2)客户端对元数据进行增删改的请求。
- (3)namenode 记录操作日志,更新滚动日志。
- (4)namenode 在内存中对数据进行增删改查。
4)第二阶段:Secondary NameNode 工作
- (1)Secondary NameNode 询问 namenode 是否需要 checkpoint。直接带回 namenode 是否检查结果。
- (2)Secondary NameNode 请求执行 checkpoint。
- (3)Secondary NameNode引导namenode 滚动更新编辑正在写的 edits 日志。
- (4) Secondary NameNode载入FSImage文件,回放编辑日志,将其合并到FSImage,将新的FSImage文件压缩后写入磁盘。
- (5)拷贝 fsimage到 namenode。
- (6)namenode 将 fsimage重新命名成 fsimage。
默认情况下,该过程每小时发生一次,或者当NameNode的编辑日志文件到达默认的64MB也会触发。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对脚本之家的支持。如果你想了解更多相关内容请查看下面相关链接
相关文章
 这篇文章主要为大家介绍了Http状态码及含义详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-11-11
这篇文章主要为大家介绍了Http状态码及含义详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-11-11 这篇文章主要为大家介绍了Flink 侧流输出源码示例解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-09-09
这篇文章主要为大家介绍了Flink 侧流输出源码示例解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-09-09 这篇文章主要介绍了rsync指定ssh端口进行文件同步的方法,需要的朋友可以参考下2018-02-02
这篇文章主要介绍了rsync指定ssh端口进行文件同步的方法,需要的朋友可以参考下2018-02-02 本文主要介绍 github pull最新代码的资料,这里对 github pull最新代码做了详细流程介绍,有需要的小伙伴可以参考下2016-09-09
本文主要介绍 github pull最新代码的资料,这里对 github pull最新代码做了详细流程介绍,有需要的小伙伴可以参考下2016-09-09 这篇文章主要为大家介绍了微服务架构之服务注册与发现的功能详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪2022-01-01
这篇文章主要为大家介绍了微服务架构之服务注册与发现的功能详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪2022-01-01 nmap(Network Mapper)是一款开源免费的针对大型网络的端口扫描工具,nmap可以检测目标主机是否在线、主机端口开放情况、检测主机运行的服务类型及版本信息、检测操作系统与设备类型等信息,本文主要介绍nmap工具安装和基本使用方法,2024-08-08
nmap(Network Mapper)是一款开源免费的针对大型网络的端口扫描工具,nmap可以检测目标主机是否在线、主机端口开放情况、检测主机运行的服务类型及版本信息、检测操作系统与设备类型等信息,本文主要介绍nmap工具安装和基本使用方法,2024-08-08 这篇文章主要介绍了weblogic的集群与配置图文方法,需要的朋友可以参考下2017-04-04
这篇文章主要介绍了weblogic的集群与配置图文方法,需要的朋友可以参考下2017-04-04 这篇文章主要介绍了构建基于虚拟用户的vsftpd服务器应用,需要的朋友可以参考下2017-05-05
这篇文章主要介绍了构建基于虚拟用户的vsftpd服务器应用,需要的朋友可以参考下2017-05-05 hMailServer是一个邮件服务器,通过它我们可以搭建自己的邮件服务,本文主要介绍了搭建hMailServer服务实现远程发送邮件的图文教程,具有一定的参考价值,感兴趣的可以了解一下2023-08-08
hMailServer是一个邮件服务器,通过它我们可以搭建自己的邮件服务,本文主要介绍了搭建hMailServer服务实现远程发送邮件的图文教程,具有一定的参考价值,感兴趣的可以了解一下2023-08-08 这篇文章主要介绍了rsync备份海量文件时占用大量内存的解决办法,需要的朋友可以参考下2016-07-07
这篇文章主要介绍了rsync备份海量文件时占用大量内存的解决办法,需要的朋友可以参考下2016-07-07










最新评论