
Hadoop的安装与环境搭建教程图解
一、Hadoop的安装
1. 下载地址:https://archive.apache.org/dist/hadoop/common/我下载的是hadoop-2.7.3.tar.gz版本。
2. 在/usr/local/ 创建文件夹zookeeper
mkdir hadoop
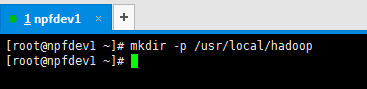
3.上传文件到Linux上的/usr/local/source目录下

3.解压缩
运行如下命令:
tar -zxvf hadoop-2.7.3.tar.gz-C /usr/local/hadoop

4. 修改配置文件
进入到cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/ , 修改hadoop-env.sh
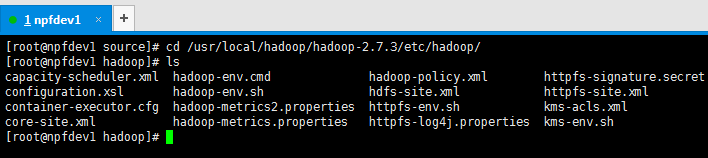
运行 vimhadoop-env.sh,修改JAVA_HOME

5.将Hadoop的执行命令加入到我们的环境变量里
在/etc/profile文件中加入:
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin
执行/etc/profile文件:
source /etc/profile
6. 将npfdev1机器上的hadoop复制到npfdev2和npfdev3和npfdev4机器上。使用下面的命令:
首先分别在npfdev2和npfdev3和npfdev4机器上,建立/usr/local/hadoop目录,然后在npfdev1上分别执行下面命令:
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev2:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev3:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev4:/usr/local/hadoop/
记住:需要各自修改npfdev2和npfdev3和npfdev4的/etc/profile文件:
在/etc/profile文件中加入:
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin
执行/etc/profile文件:
source /etc/profile
然后分别在npfdev1和npfdev2和npfdev3和npfdev4机器上,执行hadoop命令,看是否安装成功。并且关闭防火墙。

7. 确定所有机器之间可以相互ping通,使用下面的命令:
(1). ping npfdev1
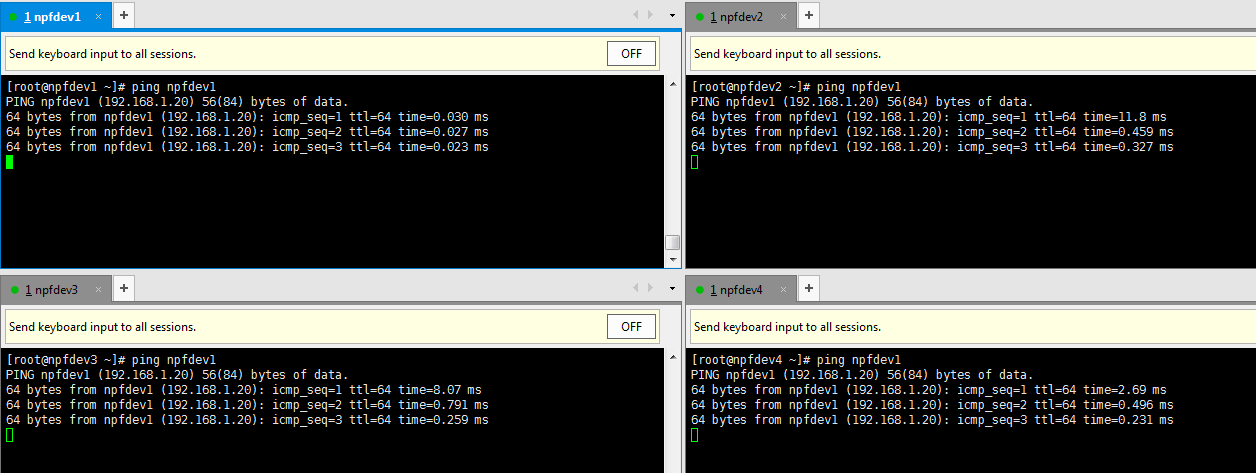
(2). ping npfdev2

(3). ping npfdev3

(4). ping npfdev4
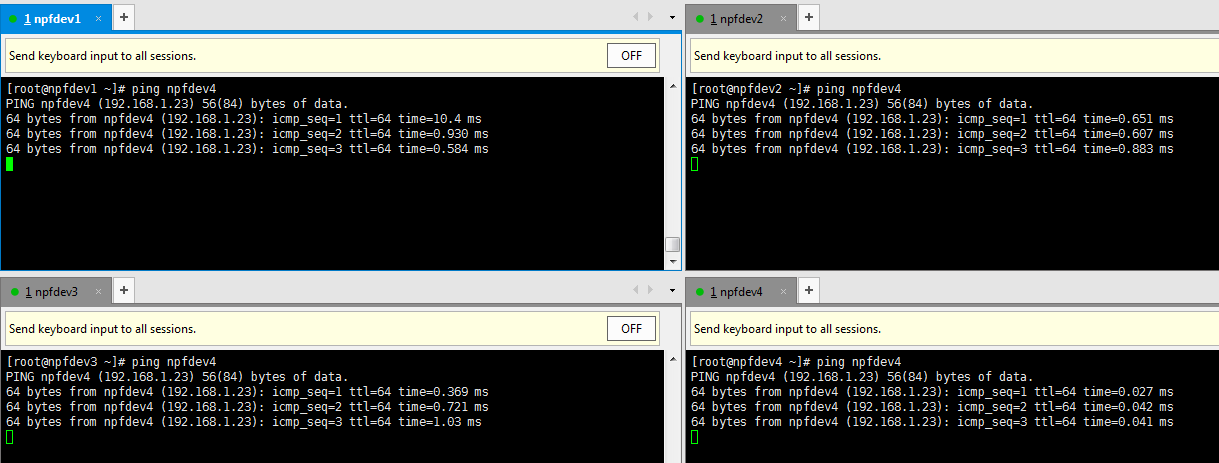
8. 启动hadoop:
我们这里将npfdev1作为master,npfdev2和npfdev3和npfdev4分别作为三台slave。
(1).修改配置文件core-site.xml
进入 cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop

具体配置如下:

(2).在master机器npfdev1上启动namenode
首先需要格式化namenode,第一次使用需要格式化,后来就不需要了。
hdfs namenode -format
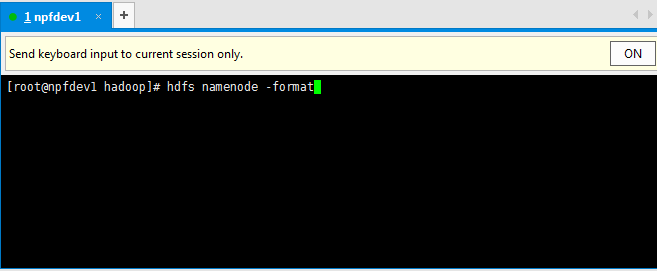
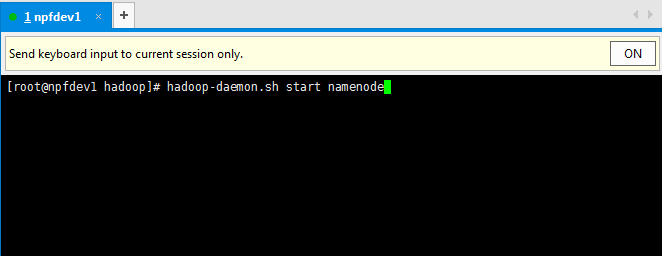
然后启动namenode:
hadoop-daemon.sh start namenode
通过jps命令查看,如果有namenode的java进程,就说明我们启动namenode成功。

(3).在slave机器npfdev2,npfdev3,npfdev4上启动datanode

总结
以上所述是小编给大家介绍的Hadoop的安装与环境搭建教程图解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关文章
 这篇文章主要介绍了关于@Component注解的含义说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-11-11
这篇文章主要介绍了关于@Component注解的含义说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-11-11
MyBatis Generator生成的$ sql是否存在注入风险详解
这篇文章主要介绍了MyBatis Generator生成的$ sql是否存在注入风险详解,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-12-12 这篇文章主要为大家详细介绍了java文件处理工具类的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-04-04
这篇文章主要为大家详细介绍了java文件处理工具类的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-04-04 Java技术体系中所提倡的自动内存管理最终可以归结为自动化地解决了两个问题:给对象分配内存以及回收分配给对象的内存,本文让我们来详细了解2021-11-11
Java技术体系中所提倡的自动内存管理最终可以归结为自动化地解决了两个问题:给对象分配内存以及回收分配给对象的内存,本文让我们来详细了解2021-11-11 在Java并发编程中,Executor是一个核心接口,提供了任务执行的抽象方法,而Executors是一个工具类,提供了创建各种线程池的工厂方法,Executor关注任务的执行,而Executors关注如何创建适合的执行器,感兴趣的可以了解一下2024-10-10
在Java并发编程中,Executor是一个核心接口,提供了任务执行的抽象方法,而Executors是一个工具类,提供了创建各种线程池的工厂方法,Executor关注任务的执行,而Executors关注如何创建适合的执行器,感兴趣的可以了解一下2024-10-10 这篇文章主要介绍了SpringBoot实现发送电子邮件,电子邮件是—种用电子手段提供信息交换的通信方式,是互联网应用最广的服务。通过网络的电子邮件系统,用户可以非常快速的方式,与世界上任何一个角落的网络用户联系,下面就来看看SpringBoot如何实现发送电子邮件吧2022-01-01
这篇文章主要介绍了SpringBoot实现发送电子邮件,电子邮件是—种用电子手段提供信息交换的通信方式,是互联网应用最广的服务。通过网络的电子邮件系统,用户可以非常快速的方式,与世界上任何一个角落的网络用户联系,下面就来看看SpringBoot如何实现发送电子邮件吧2022-01-01 这篇文章主要详细介绍了SpringBoot如何优雅的实现重试功能的步骤详解,文中有详细的代码示例,具有一定的参考价值,感兴趣的同学可以借鉴阅读2023-06-06
这篇文章主要详细介绍了SpringBoot如何优雅的实现重试功能的步骤详解,文中有详细的代码示例,具有一定的参考价值,感兴趣的同学可以借鉴阅读2023-06-06 我们在开发应用时,在某些应用场景下查询有时需要排除某些字段,本文主要介绍了两种方法,具有一定的参考价值,感兴趣的可以了解一下2023-09-09
我们在开发应用时,在某些应用场景下查询有时需要排除某些字段,本文主要介绍了两种方法,具有一定的参考价值,感兴趣的可以了解一下2023-09-09 这篇文章主要介绍了Spring Security单项目权限设计过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了Spring Security单项目权限设计过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11
IDEA 中创建Spring Data Jpa 项目的示例代码
这篇文章主要介绍了IDEA 中创建Spring Data Jpa 项目的示例代码,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-04-04










最新评论