
RocketMQ消息丢失场景以及解决方法
既然使用在项目中使用了MQ,那么就不可避免的需要考虑消息丢失问题。在一些涉及到了金钱交易的场景下,消息丢失还是很致命的。那么在RocketMQ中存在哪几种消息丢失的场景呢?
先来一张最简单的消费流程图:
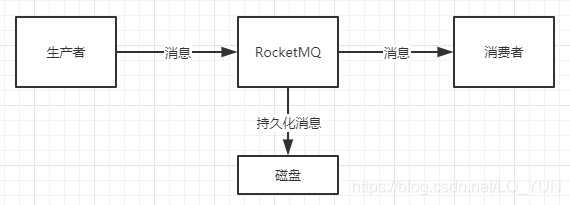
上图中大致包含了这么几种场景:
生产者产生消息发送给RocketMQRocketMQ接收到了消息之后,必然需要存到磁盘中,否则断电或宕机之后会造成数据的丢失消费者从RocketMQ中获取消息消费,消费成功之后,整个流程结束
这三种场景都可能会产生消息的丢失,如下图所示:
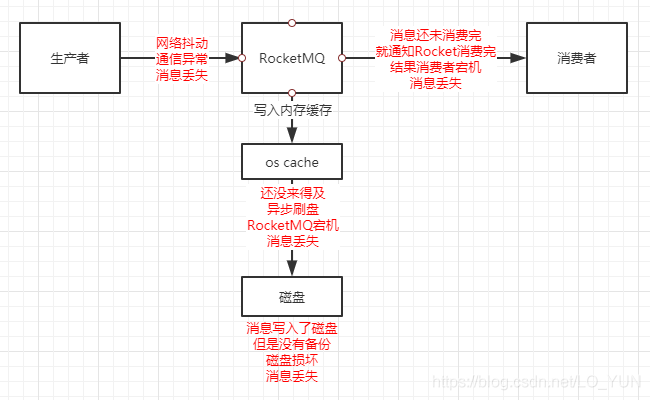
场景1中生产者将消息发送给Rocket MQ的时候,如果出现了网络抖动或者通信异常等问题,消息就有可能会丢失场景2中消息需要持久化到磁盘中,这时会有两种情况导致消息丢失
①RocketMQ为了减少磁盘的IO,会先将消息写入到os cache中,而不是直接写入到磁盘中,消费者从os cache中获取消息类似于直接从内存中获取消息,速度更快,过一段时间会由os线程异步的将消息刷入磁盘中,此时才算真正完成了消息的持久化。在这个过程中,如果消息还没有完成异步刷盘,RocketMQ中的Broker宕机的话,就会导致消息丢失
②如果消息已经被刷入了磁盘中,但是数据没有做任何备份,一旦磁盘损坏,那么消息也会丢失消费者成功从RocketMQ中获取到了消息,还没有将消息完全消费完的时候,就通知RocketMQ我已经将消息消费了,然后消费者宕机,但是RocketMQ认为消费者已经成功消费了数据,所以数据依旧丢失了
那么如何保证消息的零丢失呢?
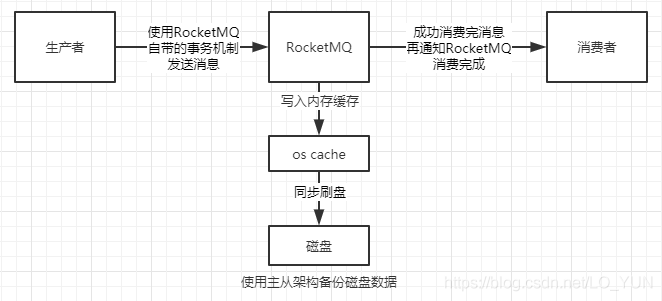
1、场景1中保证消息不丢失的方案是使用RocketMQ自带的事务机制来发送消息,大致流程为
①首先生产者发送half消息到RocketMQ中,此时消费者是无法消费half消息的,若half消息就发送失败了,则执行相应的回滚逻辑
②half消息发送成功之后,且RocketMQ返回成功响应,则执行生产者的核心链路
③如果生产者自己的核心链路执行失败,则回滚,并通知RocketMQ删除half消息
④如果生产者的核心链路执行成功,则通知RocketMQ commit half消息,让消费者可以消费这条数据
其中还有一些RocketMQ长时间没有收到生产者是要commit/rollback操作的响应,回调生产者接口的细节,感兴趣的可以参考文末的 RocketMQ分布式事务原理
在使用了RocketMQ事务将生产者的消息成功发送给RocketMQ,就可以保证在这个阶段消息不会丢失在场景2中要保证消息不丢失,首先需要将os cache的异步刷盘策略改为同步刷盘,这一步需要修改Broker的配置文件,将flushDiskType改为SYNC_FLUSH同步刷盘策略,默认的是ASYNC_FLUSH异步刷盘。一旦同步刷盘返回成功,那么就一定保证消息已经持久化到磁盘中了;为了保证磁盘损坏不会丢失数据,我们需要对RocketMQ采用主从机构,集群部署,Leader中的数据在多个Follower中都存有备份,防止单点故障。在场景3中,消息到达了消费者,RocketMQ在代码中就能保证消息不会丢失
//注册消息监听器处理消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context){
//对消息进行处理
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
上面这段代码中,RocketMQ在消费者中注册了一个监听器,当消费者获取到了消息,就会去回调这个监听器函数,去处理里面的消息
当你的消息处理完毕之后,才会返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS
只有返回了CONSUME_SUCCESS,消费者才会告诉RocketMQ我已经消费完了,此时如果消费者宕机,消息已经处理完了,也就不会丢失消息了
如果消费者还没有返回CONSUME_SUCCESS时就宕机了,那么RocketMQ就会认为你这个消费者节点挂掉了,会自动故障转移,将消息交给消费者组的其他消费者去消费这个消息,保证消息不会丢失
为了保证消息不会丢失,在consumeMessage方法中就直接写消息消费的业务逻辑就可以了,如果非要搞一些骚操作,比如下面的代码
//注册消息监听器处理消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context){
//开启子线程异步处理消息
new Thread() {
public void run() {
//对消息进行处理
}
}.start();
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
如果新开子线程异步处理消息的话,就有可能出现消息还没有被消费完,消费者告诉RocketMQ消息已经被消费了,结果宕机丢失消息的情况。
使用上面一整套的方案就可以在使用RocketMQ时保证消息零丢失,但是性能和吞吐量也将大幅下降
使用事务机制传输消息,会比普通的消息传输多出很多步骤,耗费性能同步刷盘相比异步刷盘,一个是存储在磁盘中,一个存储在内存中,速度完全不是一个数量级主从架构的话,需要Leader将数据同步给Follower消费时无法异步消费,只能等待消费完成再通知RocketMQ消费完成
消息零丢失是一把双刃剑,要想用好,还是要视具体的业务场景而定,选择合适的方案才是最好的
RocketMQ分布式事务原理
分布式事务常见的方案有TCC(Try-Confirm-Cancel),XA两阶段提交方案,可靠消息最终一致性方案,最大努力通知方案等等。其中可靠消息最终一致性方案主要就可以依靠RocketMQ来做,因为RocketMQ支持消息事务。先上一张图:

RocketMQ 事务消息的实现步骤如下:
- Producer发送half message给RocketMQ
- RocketMQ返回half message success(half message发送成功之后RocketMQ的消费者并不能消费这条消息,因为消息存储在Topic为 RMQ_SYS_TRANS_HALF_TOPIC 的消息消费队列中,而不是原先的Topic)
- 执行核心交易链路
- 返回执行交易链路的结果,如果失败则回滚
- 如果执行成功,则Producer返回一个COMMIT状态给RocketMQ
- 如果RocketMQ迟迟收不到Producer的返回结果,即这条消息的状态为UNKNOWN,则会回调服务接口,查询这条消息到底是commit还是rollback
- RocketMQ确认消息为commit,则Consumer可以消费到这条消息
- Consumer操作数据库,执行自己的事务
- Consumer成功消费之后返回一个ACK消息给RocketMQ,如果成功消费则显示消费成功,否则RocketMQ会重发消息给Consumer继续消费
RocketMQ 事务消息的实现原理基于两阶段提交和定时事务状态回查来决定消息最终是提交还是回滚,RocketMQ 先执行第一部分的事务,如果失败则回滚,如果成功则定时任务会去回查到事务执行成功,这个时候通知消费者执行第二阶段的事务,如果失败则不断重发消息给消费者消费,如果成功则整个流程走完,保证了事务的原子性。
总结
到此这篇关于RocketMQ消息丢失场景以及解决方法的文章就介绍到这了,更多相关RocketMQ消息丢失场景内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 《飞机大战-II》是一款融合了街机、竞技等多种元素的经典射击手游。游戏是用java语言实现,采用了swing技术进行了界面化处理,感兴趣的可以了解一下2022-02-02
《飞机大战-II》是一款融合了街机、竞技等多种元素的经典射击手游。游戏是用java语言实现,采用了swing技术进行了界面化处理,感兴趣的可以了解一下2022-02-02
Java并发编程必备之Synchronized关键字深入解析
本文我们深入探索了Java中的Synchronized关键字,包括其互斥性和可重入性的特性,文章详细介绍了Synchronized的三种使用方式:修饰代码块、修饰普通方法和修饰静态方法,感兴趣的朋友一起看看吧2025-04-04 SnowFlake算法,是Twitter开源的分布式id生成算法,在2014年开源,开源的版本由scala编写。其核心思想就是-使用一个64bit的long型的数字作为全局唯一id2022-12-12
SnowFlake算法,是Twitter开源的分布式id生成算法,在2014年开源,开源的版本由scala编写。其核心思想就是-使用一个64bit的long型的数字作为全局唯一id2022-12-12 这篇文章主要介绍了SpringBoot中的main方法注入service操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
这篇文章主要介绍了SpringBoot中的main方法注入service操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
解决@PostConstruct注解导致的程序无法启动(@PostConstruct的执行)
这篇文章主要介绍了解决@PostConstruct注解导致的程序无法启动(@PostConstruct的执行)问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-01-01 这篇文章主要为大家详细介绍了servlet下载文件的实现代码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-09-09
这篇文章主要为大家详细介绍了servlet下载文件的实现代码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-09-09 对于Java开发者来说,将DeepSeek集成到项目中,可以极大地提升数据处理和分析的效率,下面小编就来为大家介绍一下具体的调用方法吧2025-03-03
对于Java开发者来说,将DeepSeek集成到项目中,可以极大地提升数据处理和分析的效率,下面小编就来为大家介绍一下具体的调用方法吧2025-03-03 这篇文章主要介绍了IntelliJ Idea2017如何修改缓存文件的路径,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10
这篇文章主要介绍了IntelliJ Idea2017如何修改缓存文件的路径,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10 这篇文章主要介绍了在Spring中如何注入动态代理Bean问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-03-03
这篇文章主要介绍了在Spring中如何注入动态代理Bean问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-03-03 这篇文章主要介绍了java 动态加载的实现代码的相关资料,Java动态加载类主要是为了不改变主程序代码,通过修改配置文件就可以操作不同的对象执行不同的功能,需要的朋友可以参考下2017-07-07
这篇文章主要介绍了java 动态加载的实现代码的相关资料,Java动态加载类主要是为了不改变主程序代码,通过修改配置文件就可以操作不同的对象执行不同的功能,需要的朋友可以参考下2017-07-07










最新评论