
JAVA对象分析之偏向锁、轻量级锁、重量级锁升级过程
在HotSpot虚拟机里,对象在堆内存中的存储布局可以划分为三个部分:
对象头(Header)
实例数据(Instance Data)
对齐填充(Padding)。
对象头
HotSpot虚拟机(后面没有说明的话默认是这个虚拟机)对象头包括三部分:
- Mark Word
- 指向类的指针
- 数组长度(只有数组对象才有)
对象头之Mark Word
Mark Word记录了对象和锁有关的信息,当这个对象被synchronized关键字当成同步锁时,围绕这个锁的一系列操作都和Mark Word有关。
Mark Word在32位JVM中的长度是32bit,在64位JVM中长度是64bit。
Mark Word在不同的锁状态下存储的内容不同,在32位JVM中是这么存的:
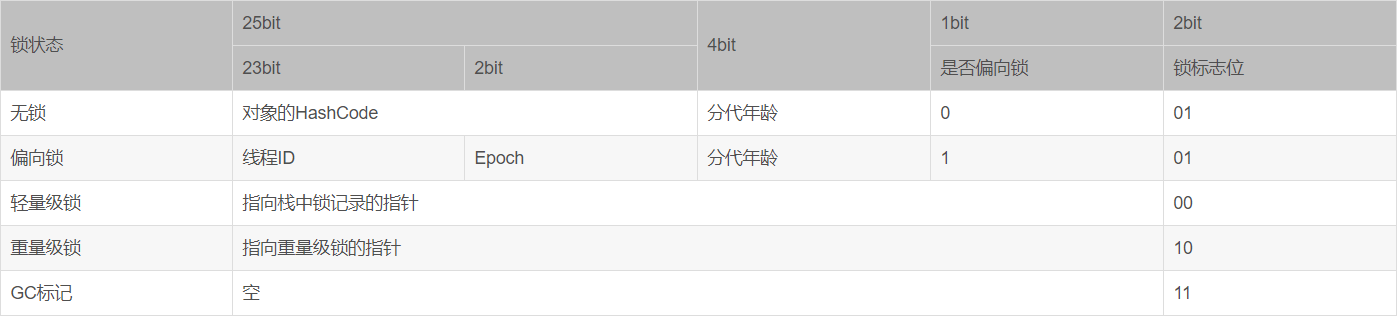
一共32位,两位用来记录锁的信息,1位用来记录是否是偏向锁,如果偏向锁是1的话,那么会分配23位来记录偏向的线程id,当计算过Hash后,意味着会分配25bit来记录HashCode,那么久没有空间用来记录偏向锁的线程ID了,所以计算过HashCode后就没法再进入偏向锁。如果进入轻量级锁或者重量级锁,意味着会用30bit指向指针,那么此时对象头中就只有两种信息,锁标志、指向锁的指针。
其中无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。
JDK1.6以后的版本在处理同步锁时存在锁升级的概念,JVM对于同步锁的处理是从偏向锁开始的,随着竞争越来越激烈,处理方式从偏向锁升级到轻量级锁,最终升级到重量级锁。
结合Mark Word分析锁升级的流程:
1,当没有被当成锁时,这就是一个普通的对象,Mark Word记录对象的HashCode,锁标志位是01,是否偏向锁那一位是0(0则false , 1 则true)。
2,当对象被当做同步锁并有一个线程A抢到了锁时,锁标志位还是01,但是否偏向锁那一位改成1,前23bit记录抢到锁的线程id,表示进入偏向锁状态。
3,当线程A再次试图来获得锁时,JVM发现同步锁对象的标志位是01,是否偏向锁是1,也就是偏向状态,Mark Word中记录的线程id就是线程A自己的id,表示线程A已经获得了这个偏向锁,可以执行同步锁的代码。
4,当线程B试图获得这个锁时,JVM发现同步锁处于偏向状态,但是Mark Word中的线程id记录的不是B,那么线程B会先用CAS操作试图获得锁,这里的获得锁操作是有可能成功的,因为线程A一般不会自动释放偏向锁。如果抢锁成功,就把Mark Word里的线程id改为线程B的id,代表线程B获得了这个偏向锁,可以执行同步锁代码。如果抢锁失败,则继续执行步骤5。
5,偏向锁状态抢锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。JVM会在当前线程的线程栈中开辟一块单独的空间,里面保存指向对象锁Mark Word的副本,同时在对象锁Mark Word中保存指向这片空间的指针。上述两个保存操作都是CAS操作,如果保存成功,代表线程抢到了同步锁,就把Mark Word中的锁标志位改成00,可以执行同步锁代码。如果保存失败,表示抢锁失败,竞争太激烈,继续执行步骤6。
6,轻量级锁抢锁失败,JVM会使用自旋锁,自旋锁不是一个锁状态,只是代表不断的重试,尝试抢锁。从JDK1.7开始,自旋锁默认启用,自旋次数由JVM决定。如果抢锁成功则执行同步锁代码,如果失败则继续执行步骤7。
7,自旋锁重试之后如果抢锁依然失败,同步锁会升级至重量级锁,锁标志位改为10。在这个状态下,未抢到锁的线程都会被阻塞。
对象头之指向类的指针
该指针在32位JVM中的长度是32bit,在64位JVM中长度是64bit。
Java对象的类数据保存在方法区。 并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话说,查找对象的元数据信息并不一定要经过对象本身。
对象头之数组长度
如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是如果数组的长度是不确定的,将无法通过元数据中的信息推断出数组的大小。
只有数组对象保存了这部分数据, 该数据在32位和64位JVM中长度都是32bit。
实例数据
实例数据部分是对象真正存储的有效信息,即我们在程序代码里面所定义的各种类型的字段内容,无论是从父类继承下来的,还是在子类中定义的字段都必须记录起来。这部分的存储顺序会受到虚拟机分配策略参数(-XX:FieldsAllocationStyle参数)和字段在Java源码中定义顺序的影响。HotSpot虚拟机默认的分配顺序为longs/doubles、ints、shorts/chars、bytes/booleans、oops(OrdinaryObject Pointers,OOPs),从以上默认的分配策略中可以看到,相同宽度的字段总是被分配到一起存放,在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。如果HotSpot虚拟机的+XX:CompactFields参数值为true(默认就为true),那子类之中较窄的变量也允许插入父类变量的空隙之中,以节省出一点点空间。
对齐填充
这并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot虚拟机的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是任何对象的大小都必须是8字节的整数倍。对象头部分已经被精心设计成正好是8字节的倍数(1倍或者2倍),因此,如果对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。
到此这篇关于JAVA对象分析之偏向锁、轻量级锁、重量级锁升级过程的文章就介绍到这了,更多相关偏向锁、轻量级锁、重量级锁升级过程内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了通过jenkins发布java项目到目标主机上的详细步骤,发布java项目的步骤很简单,通过拉取代码并打包,备份目标服务器上已有的要发布项目,具体内容详情跟随小编一起看看吧2021-10-10
这篇文章主要介绍了通过jenkins发布java项目到目标主机上的详细步骤,发布java项目的步骤很简单,通过拉取代码并打包,备份目标服务器上已有的要发布项目,具体内容详情跟随小编一起看看吧2021-10-10 这篇文章主要介绍了Java实现上传和下载功能,支持多个文件同时上传,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-12-12
这篇文章主要介绍了Java实现上传和下载功能,支持多个文件同时上传,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-12-12 这篇文章主要介绍了Java基本数据类型和运算符,结合实例形式详细分析了java基本数据类型、数据类型转换、算术运算符、逻辑运算符等相关原理与操作技巧,需要的朋友可以参考下2021-07-07
这篇文章主要介绍了Java基本数据类型和运算符,结合实例形式详细分析了java基本数据类型、数据类型转换、算术运算符、逻辑运算符等相关原理与操作技巧,需要的朋友可以参考下2021-07-07 这篇文章主要介绍了Java生成由时间组成的订单号方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-04-04
这篇文章主要介绍了Java生成由时间组成的订单号方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-04-04 在调整java代码过程中会遇到需要改jar包中的class文件的情况,改了如何替换呢?下面小编给大家分享java替换jar中的class文件的操作方法,感兴趣的朋友跟随小编一起看看吧2024-02-02
在调整java代码过程中会遇到需要改jar包中的class文件的情况,改了如何替换呢?下面小编给大家分享java替换jar中的class文件的操作方法,感兴趣的朋友跟随小编一起看看吧2024-02-02 本文主要介绍了maven安装配置的实现步骤,包括下载和安装Maven,配置Maven的环境变量,以及创建Maven项目,具有一定的参考价值,感兴趣的可以了解一下2023-09-09
本文主要介绍了maven安装配置的实现步骤,包括下载和安装Maven,配置Maven的环境变量,以及创建Maven项目,具有一定的参考价值,感兴趣的可以了解一下2023-09-09 这篇文章主要介绍了详解Java 中程序内存的分析的相关资料,需要的朋友可以参考下2017-04-04
这篇文章主要介绍了详解Java 中程序内存的分析的相关资料,需要的朋友可以参考下2017-04-04
Java编程中使用XFire框架调用WebService程序接口
这篇文章主要介绍了Java编程中使用XFire调用WebService程序接口的方法,WebService是一种跨编程语言和跨操作系统平台的远程调用技术,需要的朋友可以参考下2015-12-12 这篇文章主要介绍了java如何实现post请求webservice服务端,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-03-03
这篇文章主要介绍了java如何实现post请求webservice服务端,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-03-03 这篇文章主要介绍了 java中的final关键字详解及实例的相关资料,需要的朋友可以参考下2017-03-03
这篇文章主要介绍了 java中的final关键字详解及实例的相关资料,需要的朋友可以参考下2017-03-03










最新评论