
浅谈hashmap为什么查询时间复杂度为O(1)
hashmap为什么查询时间复杂度为O(1)
Hashmap是java里面一种类字典式数据结构类,能达到O(1)级别的查询复杂度,那么到底是什么保证了这一特性呢,这个就要从hashmap的底层存储结构说起
下来看一张图:
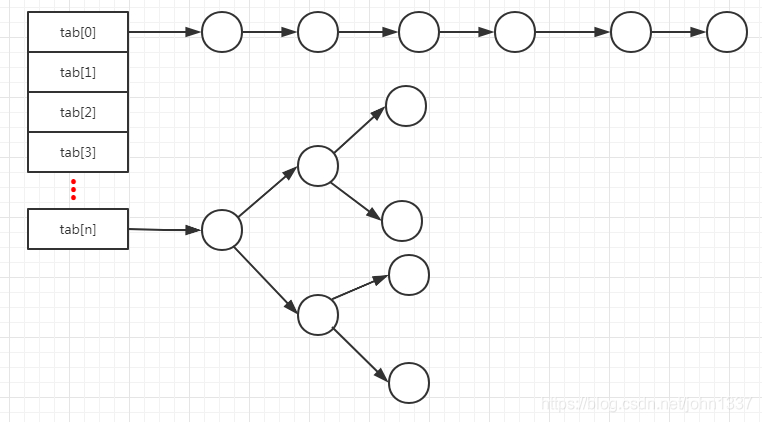
上面就是hashmap的底层存储示意图,要想查看一个键值对应的值,首先根据该键值的hash值找到该键的hash桶位置,即是tab[2]还是tab[1]等,计算某个键对应的哈希桶位置很简单,就是
int pos = (n - 1) & hash,也就是hash%n,因为位运算效率高所以在hashmap实现时使用的是位运算这种方式,需要注意的是哈希桶的数量必须是2^n,所以hashmap一旦扩容必定是哈希桶数量翻番。
通过上面的描述,我们可以知道,根据键值找到哈希桶的位置时间复杂度为O(1),使用的就是数组的高效查询。但是仅仅有这个是无法满足整个hashmap查询时间复杂度为O(1)的。hashmap在处理哈希冲突的方式如上图所示的拉链法,在冲突数据没有达到8个以前该哈希桶内部存储使用的是链表的方式,当某个哈希桶的数据超过8个的情况下,
有下面两种处理方式:
1、哈希桶的数量是没有超过64个,那么此时哈希桶数量double,然后数据迁移
2、哈希桶的数量超过了64个,将该哈希桶内部数据进行红黑树化处理
所以我们可以看到如果所有哈希桶内部数据都是链表存储的,那么每个哈希桶的数据量不会超过8个,这样当定位到某个哈希桶时,在该哈希桶继续查找也可以在O(1)时间内完成,下面看一种极端情况,所有的数据都在同一个桶里面(这种情况只在所有键值hash值相同的情况下,这种情况下查询的时间复杂度为O(lgn),比如下面给出的一个类,所有我们在设置hashmap的键值时需要特别注意),在hashmap的文档里面有这么一段描述,每个哈希桶中元素数量是成泊松分布的,
listSize = (exp(-0.5) * pow(0.5, k) / * factorial(k)),
不同数量出现的概率如下:
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
大于8: <千万分之1
通过上面的统计来看,hashmap的键值正常(不同对象的hash值不同的情况),哈希桶数量超过8个概率低于千万分之一,所以我们通常认为hashmap的查询时间复杂度为O(1)
PS:
1、哈希冲突百分百的类
/**
测试哈希冲突的类,所有的对象都返回同样的hash值
**/
public static class Student{
private String name;
Student(String name){
this.name = name;
}
@Override
public int hashCode(){
return 1;
}
@Override
public boolean equals(Object obj){
if(this == obj){
return true;
}
if(obj == null){
return false;
}
return this.name.equals(((Student)obj).name);
}
}
2、我们在实际使用hashmap时需要确保实现hashcode方法以及equals方法,否则不能作为hashmap的键值
3、在设置hashmap的键值hashcode方法时尽量保证较好的离散型
4、hashmap的键值需保证equals方法返回true时,hashcode必须相同,所以在实际中经常使用的键值类string,重写了equals以及hashcode方法
HashMap时间复杂度问题
HashMap底层采用了hash算法
根据 key 获得 hashCode 值
HashMap 初始有很多个类似于“桶”的数据结构,比如说预设了 10 个桶,通过 hashCode 经过一定的算法(这个算法必须是快速的)
得到这个 hashCode 应存在哪个桶中,然后内部生成 Map.Entry 对象将 key 和 value 存到桶中去。
所以一般情况下HashMap的插入和查找的时间复杂度都是O(1);
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了springboot整合GuavaCache缓存过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了springboot整合GuavaCache缓存过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
Java中ArrayList和LinkedList之间的区别_动力节点Java学院整理
这篇文章主要为大家详细介绍了Java中ArrayList和LinkedList之间的区别,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-05-05 这篇文章主要介绍了Spring条件注解用法,结合具体实例形式分析了Spring条件注解相关原理、使用方法及操作注意事项,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了Spring条件注解用法,结合具体实例形式分析了Spring条件注解相关原理、使用方法及操作注意事项,需要的朋友可以参考下2019-11-11 本文介绍了springboot配置flyway,主要介绍基于SpringBoot集成flyway来管理数据库的变更,具有一定的参考价值,感兴趣的可以了解一下2023-09-09
本文介绍了springboot配置flyway,主要介绍基于SpringBoot集成flyway来管理数据库的变更,具有一定的参考价值,感兴趣的可以了解一下2023-09-09 今天给大家带来的是关于Java的相关知识,文章围绕着Java中关于文件路径读取问题展开,文中有非常详细的介绍及代码示例,需要的朋友可以参考下2021-06-06
今天给大家带来的是关于Java的相关知识,文章围绕着Java中关于文件路径读取问题展开,文中有非常详细的介绍及代码示例,需要的朋友可以参考下2021-06-06 这篇文章主要为大家详细介绍了MyBatisPlus中代码生成器的原理及实现,文中的示例代码讲解详细,对我们学习MyBatisPlus有一定帮助,需要的可以参考一下2022-08-08
这篇文章主要为大家详细介绍了MyBatisPlus中代码生成器的原理及实现,文中的示例代码讲解详细,对我们学习MyBatisPlus有一定帮助,需要的可以参考一下2022-08-08
Springboot @Transactional使用时需注意的几个问题记录
本文详细介绍了Spring Boot中使用`@Transactional`注解进行事务管理的多个方面,包括事务的隔离级别(如REPEATABLE_READ)和传播行为(如REQUIRES_NEW),并指出了在同一个类中调用事务方法时可能遇到的问题以及解决方案,感兴趣的朋友跟随小编一起看看吧2025-01-01 在项目中遇到需要批量更新的功能,原本想的是在Java中用循环访问数据库去更新,但是心里总觉得这样做会不会太频繁了,太耗费资源了,效率也很低,查了下mybatis的批量操作,原来确实有<foreach>标签可以做到,下面通过本文给大家介绍下2017-01-01
在项目中遇到需要批量更新的功能,原本想的是在Java中用循环访问数据库去更新,但是心里总觉得这样做会不会太频繁了,太耗费资源了,效率也很低,查了下mybatis的批量操作,原来确实有<foreach>标签可以做到,下面通过本文给大家介绍下2017-01-01
JAVA加密算法- 非对称加密算法(DH,RSA)的详细介绍
这篇文章主要介绍了JAVA加密算法- 非对称加密算法(DH,RSA),详细介绍了DH,RSA的用法和示例,需要的朋友可以了解一下。2016-11-11 这篇文章主要为大家介绍了java数据结构图论霍夫曼树及其编码示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪2021-11-11
这篇文章主要为大家介绍了java数据结构图论霍夫曼树及其编码示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪2021-11-11










最新评论