
Lucene fnm索引文件格式源码解析
更新时间:2023年03月14日 11:17:17 作者:沧叔解码
这篇文章主要为大家介绍了Lucene fnm索引文件格式源码解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪
简介
后缀为fnm文件是存储索引的字段的元信息,包含字段名称,字段类型,字段属性等信息。
版本
lucene 9.1.0
涉及的主要类
fnm索引文件的生成源码比较简单,不贴了,主要逻辑在:
org.apache.lucene.codecs.lucene90.Lucene90FieldInfosFormat
代码示例
FieldType fieldType = new FieldType();
fieldType.setStored(true);
fieldType.setStoreTermVectors(true);
fieldType.setStoreTermVectorOffsets(true);
fieldType.setStoreTermVectorPositions(true);
fieldType.setStoreTermVectorPayloads(true);
fieldType.setTokenized(true);
fieldType.setOmitNorms(true);
fieldType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
Document doc = new Document();
doc.add(new Field("name", "maria", fieldType));
doc.add(new SortedDocValuesField("name", new BytesRef("maria")));
doc.add(new IntPoint("id", 1, 2, 3));
doc.add(new KnnVectorField("vector", new float[]{1.1f, 2.2f, 3.3f}, VectorSimilarityFunction.COSINE));
文件结构全局示意图

字段描述
Header
文件头部信息,主要是包括:
- 文件头魔数(同一lucene版本所有文件相同)
- 该文件使用的codec名称:Lucene90FieldInfos(codec可以理解成文件的布局格式,不同版本lucene相同后缀文件有不一样的版本格式)
- codec版本
- segment后缀名(一般为空)
- segment id(也是Segment_N文件中的N)
FieldCount
该索引的field总数
Field
记录字段的元信息
FieldName
字段名称,比如示例代码中的name,id,vector都是字段名称
FieldNumber
字段的编号
FieldBits
部分属性的位图信息,是一个组合值,描述字段是否具有以下属性:
- 是否存储词向量(termVector):0x1
- 是否要忽略norm值:0x2
- 是否带有payload:0x4
- 该字段是否是软删除字段(soft delete):0x8
示例代码中的name字段的FieldBits的值为:0x1 | 0x2 | 0x4 = 0x7
IndexOptions
字段的索引选项,表示在索引该字段的时候存储的倒排信息有哪些,所有的类型:
- 0:NONE
- 1:DOCS
- 2:DOCS_AND_FREQS
- 3:DOCS_AND_FREQS_AND_POSITIONS
- 4:DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS
DocValuesBits
官方文档描述的是由norm和docValue类型的组合值,但是从源码看只存储了docValue类型。
- 0:NONE
- 1:NUMERIC
- 2:BINARY
- 3:SORTED
- 4:SORTED_SET
- 5:SORTED_NUMERIC
DocValuesGen
可以理解为字段DocValues的版本号,通过IndexWriter.updateDocValues(...)会更新该版本号
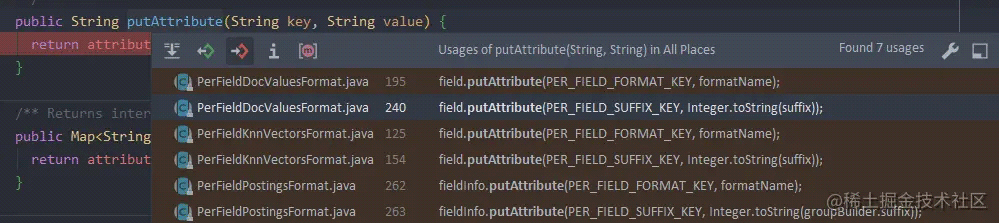
Attributes
可能的值有:
PointDimensionCount
如果字段是IntPoint,LongPoint等类型,则记录维数。
PointNumBytes
如果字段是IntPoint,LongPoint等类型,则记录每一维数据存储需要的字节个数。
VectorDimension
向量字段记录向量的维数
VectorSimilarityFunction
向量相似度衡量函数:
- EUCLIDEAN:欧式距离
- DOT_PRODUCT:点积
- COSINE:consine距离
Footer
文件尾,主要包括
- 文件尾魔数(同一个lucene版本所有文件一样)
- 0
- 校验码
以上就是Lucene fnm索引文件格式源码解析的详细内容,更多关于Lucene fnm索引文件格式的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要介绍了MybatisPlus开启二级缓存的方法详解,二级缓存是基于mapper文件的namespace级别,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,需要的朋友可以参考下2023-11-11
这篇文章主要介绍了MybatisPlus开启二级缓存的方法详解,二级缓存是基于mapper文件的namespace级别,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,需要的朋友可以参考下2023-11-11 垃圾回收(GC)是 Java 中的一个重要机制,它可以管理内存并回收不再使用的对象所占用的资源,在本文中,我们将探讨一些技巧,帮助您避免这一错误,确保您的 Java 应用程序顺利运行,需要的朋友可以参考下2023-11-11
垃圾回收(GC)是 Java 中的一个重要机制,它可以管理内存并回收不再使用的对象所占用的资源,在本文中,我们将探讨一些技巧,帮助您避免这一错误,确保您的 Java 应用程序顺利运行,需要的朋友可以参考下2023-11-11 这篇文章主要介绍了SpringBoot通过yml和xml文件配置日志输出方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-04-04
这篇文章主要介绍了SpringBoot通过yml和xml文件配置日志输出方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-04-04 这篇文章主要介绍了springboot获取profile的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-09-09
这篇文章主要介绍了springboot获取profile的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-09-09 这篇文章主要介绍了使用RequestHeaders添加自定义参数方式,具有很好的参考价值,希望对大家有所帮助。2022-02-02
这篇文章主要介绍了使用RequestHeaders添加自定义参数方式,具有很好的参考价值,希望对大家有所帮助。2022-02-02 今天小编就为大家分享一篇Java实现从Html文本中提取纯文本的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
今天小编就为大家分享一篇Java实现从Html文本中提取纯文本的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05 这篇文章主要介绍了Java实现双保险线程的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-12-12
这篇文章主要介绍了Java实现双保险线程的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-12-12 内存溢出分为两大类:OutOfMemoryError和StackOverflowError,以下举出10个内存溢出的情况,并通过实例代码的方式讲解了是如何出现内存溢出的,感兴趣的可以了解一下2024-01-01
内存溢出分为两大类:OutOfMemoryError和StackOverflowError,以下举出10个内存溢出的情况,并通过实例代码的方式讲解了是如何出现内存溢出的,感兴趣的可以了解一下2024-01-01 本文主要介绍了SpringBoot+Druid开启监控页面的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2024-06-06
本文主要介绍了SpringBoot+Druid开启监控页面的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2024-06-06 冒泡排序法:关键字较小的记录好比气泡逐趟上浮,关键字较大的记录好比石块下沉,每趟有一块最大的石块沉底。算法本质:(最大值是关键点,肯定放到最后了,如此循环)每次都从第一位向后滚动比较,使最大值沉底,最小值上升一次,最后一位向前推进2016-02-02
冒泡排序法:关键字较小的记录好比气泡逐趟上浮,关键字较大的记录好比石块下沉,每趟有一块最大的石块沉底。算法本质:(最大值是关键点,肯定放到最后了,如此循环)每次都从第一位向后滚动比较,使最大值沉底,最小值上升一次,最后一位向前推进2016-02-02










最新评论