
解析四则表达式的编译过程及生成汇编代码
更新时间:2013年06月26日 15:05:28 作者:
本篇文章是对四则表达式的编译过程及生成汇编代码进行了详细的分析介绍,需要的朋友参考下
1、前序
这是编译原理的实验,自认为是上大学以来做过的最难的一个实验。
实验用到的基础知识:C语言、数据结构、汇编(只需简单的了解)。
开发工具:VC
2、问题描述
编译整数四则运算表达式,将整数四则运算表达式翻译为汇编语言代码。
消除左递归后的文法:
E→TE'
E'→+TE' |ε
T→FT'
T'→*FT' |ε
F→(E) | i
消除左递归后的翻译模式:
E ::= T {E'.i:=T.nptr}
E' {E.nptr:=E'.s}
E'::= + T {E'1.i:=mknode(‘+',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= - T {E'1.i:=mknode(‘-',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= ε {E'.s:= E'.i}
T ::= F {T'.i:=F.nptr}
T' {T.nptr:=T'.s}
T'::= * F {T'1.i:=mknode(‘*',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T'::= / F {T'1.i:=mknode(‘/',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T' ::= ε {T'.s:= T'.i}
F ::= (E) {F.nptr:=E.nptr}
F ::= num {F.nptr:=mkleaf(num,num.val)}
3、全局定义
test.c文件
#ifndef TEST_C
#define TEST_C
/**
* 全局变量和全局函数文件
**/
#include<stdio.h>
#include<ctype.h>
#include<string.h>
#include<stdlib.h>
/************************* 以下是全局变量(函数)的定义 *******************/
//输入的表达式最大长度,可以看做是缓冲区的长度
#define MAX_EXPRESSION_LENGTH 50
//存放输入的表达式
char expression[MAX_EXPRESSION_LENGTH];
//表达式字符数组的下标
int expression_index=0;
//存放一个单词符号
char strToken[MAX_EXPRESSION_LENGTH/2];
//判断是否是数字
int isNum(char * strToken)
{
int i=0;
while(strToken[i]){
if(!isdigit(strToken[i]))
break;
i++;
}
return strToken[i]==0;
}
//错误处理程序
void error(char* errerMessage)
{
printf("\nERROR:%s\n",errerMessage);
exit(0);
}
/************************* 以上是全局变量(函数)的定义 ******************/
#endif
4、词法分析
词法分析的要求是:接受一个表达式,输出该表达式中的各类单词符号
一般有两种方法来进行词法分析,一种是用状态图来实现,一种是用状态转换表。下面采用状态图实现
首先定义单词符号的种类和所属类型
typedef enum Symbol { ERR = -1, END, NUM, PLUS, MINUS, TIMES, SLASH, LPAREN, RPAREN } Symbol;
然后转态转换图如下所示:
#ifndef TEST1_C
#define TEST1_C
/**
* 采用状态图进行词法分析以及测试词法分析
*
**/
#include"test.c"
//枚举类型
typedef enum Symbol { ERR = -1, END, NUM, PLUS, MINUS, TIMES,
SLASH, LPAREN, RPAREN } Symbol;
//获取一个单词符号,该单词符号存放在strToken中。返回该单词符号的枚举类型
Symbol getToken();
//根据传入的枚举类型输出对应的单词符号
void printToken(Symbol i);
//测试词法分析
void testLexAnalyse();
//获取一个单词符号,该单词符号存放在strToken中。返回该单词符号的枚举类型
Symbol getToken()
{
char ch;
int state=0;//每次都是从状态0开始
int j=0;
//表达式遍历完成,单词符号为'#'
if(expression[expression_index]=='\0'){
strToken[0]='#';
strToken[1]='\0';
return END;
}
while(1){
switch(state){
case 0:
//读取一个字符
ch=strToken[j++]=expression[expression_index++];
if(isspace(ch)){
j--;//注意退格
state=0;
}
else if(isdigit(ch))
state=1;
else if(ch=='+')
state=2;
else if(ch=='-')
state=3;
else if(ch=='*')
state=4;
else if(ch=='/')
state=5;
else if(ch=='(')
state=6;
else if(ch==')')
state=7;
else
return ERR;
break;
case 1:
ch=strToken[j++]=expression[expression_index++];
if(isdigit(ch))
state=1;
else{
expression_index--;
strToken[--j]=0;
return NUM;
}
break;
case 2:
strToken[j]=0;
return PLUS;
case 3:
strToken[j]=0;
return MINUS;
case 4:
strToken[j]=0;
return TIMES;
case 5:
strToken[j]=0;
return SLASH;
case 6:
strToken[j]=0;
return LPAREN;
case 7:
strToken[j]=0;
return RPAREN;
}
}
}
//根据传入的枚举类型输出对应的单词符号
void printToken(Symbol i){
switch(i){
case -1:printf("ERR\n");break;
case 0:printf("END\n");break;
case 1:printf("NUM %s\n",strToken);break;
case 2:printf("PLUS %s\n",strToken);break;
case 3:printf("MINUS %s\n",strToken);break;
case 4:printf("TIMES %s\n",strToken);break;
case 5:printf("SLASH %s\n",strToken);break;
case 6:printf("LPAREN %s\n",strToken);break;
case 7:printf("RPAREN %s\n",strToken);break;
}
}
//测试词法分析
void testLexAnalyse()
{
Symbol tokenStyle;//单词符号类型
expression_index=0;
puts("\n词法分析结果如下:");
while(1){
tokenStyle=getToken();
printToken(tokenStyle);
if(tokenStyle == ERR){
error("词法分析错误!");
}
if(tokenStyle == END){
break;
}
}
}
//主函数
int main()
{
gets(expression);
testLexAnalyse();
return 0;
}
#endif
运行结果
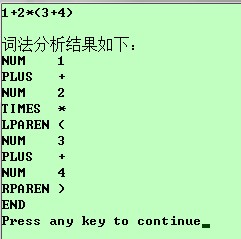
5、语法分析
要求:接受一个表达式,分析该表达式,并根据输入正确与否给出相应信息
主要是根据无左递归文法写出对应的各个子程序
test2.c
#ifndef TEST_2
#define TEST_2
/**
* 语法分析以及测试语法分析
**/
#include"test1.c"
/*
消除左递归后的文法:
E→TE'
E'→+TE' |ε
T→FT'
T'→*FT' |ε
F→(E) | i
*/
//每个非终结符有对应的子程序函数声明
void E();
void E1();
void T();
void T1();
void F();
//测试语法分析
void testSyntaxAnalyse();
//每个非终结符有对应的子程序
void E()
{
T();
E1();
}
void E1()
{
if(strcmp(strToken,"+")==0 || strcmp(strToken,"-")==0){
getToken();
T();
E1();
}
//Follow(E1)={#,)}
else if(strcmp(strToken,"#")!=0 && strcmp(strToken,")")!=0){
error("语法分析错误!");
}
}
void T()
{
F();
T1();
}
void T1()
{
if(strcmp(strToken,"*")==0 || strcmp(strToken,"/")==0){
getToken();
F();
T1();
}
//Follow(T1)={+,#,)},如果考虑-号的话要加上-号
else if(strcmp(strToken,"-")!=0 &&strcmp(strToken,"+")!=0 && strcmp(strToken,"#")!=0 && strcmp(strToken,")")!=0){
error("语法分析错误!");
}
}
void F()
{
if(isNum(strToken)){
getToken();
}
else{
if(strcmp(strToken,"(")==0){
getToken();
E();
if(strcmp(strToken,")")==0)
getToken();
else
error("语法分析错误!");
}
else
error("语法分析错误!");
}
}
//测试语法分析
void testSyntaxAnalyse()
{
expression_index=0;
getToken();
E();
puts("\n语法分析结果如下:");
if(strcmp(strToken,"#")!=0)
error("语法分析错误!");
else{
puts("语法分析正确!");
}
}
//主函数
int main()
{
gets(expression);
testLexAnalyse();
testSyntaxAnalyse();
return 0;
}
#endif
运行时要删掉test1.c中的主函数,运行结果

6、语义分析
要求:需要实现的语义分析程序的功能是,接受一个表达式,分析该表达式,并在分析的过程中建立该表达式的抽象语法树。由于四则运算表达式的抽象语法树可基本上看作是二叉树,因此中序遍历序列应该和输入的表达式一样——除了没有括号之外。可输出中序遍历序列检测程序功能是否正确。如果每个分支节点用一个临时变量标记,则对四则运算表达式的抽象语法树进行后序遍历,可以得到输入表达式所对应的四元式序列
test3.c文件
#ifndef TEST3_C
#define TEST3_C
/**
* 语义分析以及测试语义分析
* 其实这个实验是在test2的代码上进行修改
**/
#include"test1.c"
/*
消除左递归的翻译模式:
E ::= T {E'.i:=T.nptr}
E' {E.nptr:=E'.s}
E'::= + T {E'1.i:=mknode('+',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= - T {E'1.i:=mknode('-',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= ε {E'.s:= E'.i}
T ::= F {T'.i:=F.nptr}
T' {T.nptr:=T'.s}
T'::= * F {T'1.i:=mknode('*',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T'::= / F {T'1.i:=mknode('/',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T' ::= ε {T'.s:= T'.i}
F ::= (E) {F.nptr:=E.nptr}
F ::= num {F.nptr:=mkleaf(num,num.val)}
*/
#define MAX_LENGTH 20 //四元式中操作数的最大长度
typedef int ValType;
//结点类型
typedef struct ASTNode {
Symbol sym;//类型
ValType val;//值
struct ASTNode * left, *right;//左、右孩子
}ASTNode, *AST;
//四元式类型定义如下
typedef struct Quaternion{
char op;
char arg1[MAX_LENGTH];
char arg2[MAX_LENGTH];
char result[MAX_LENGTH];
}Quaternion;
//四元式数组,存放产生的四元式
Quaternion quaternion[MAX_LENGTH*2];
//统计四元式的个数
int count=0;
//后序遍历抽象语法树时存放操作数和临时变量,这里当作一个栈来使用
char stack[MAX_LENGTH*2][MAX_LENGTH];
//stack栈的下标
int index=0;
//内存中临时数据存储地址的偏移量
int t=-4;
//函数声明
ASTNode* E();
ASTNode* E1(ASTNode* E1_i);
ASTNode* T();
ASTNode* T1(ASTNode* T1_i);
ASTNode* F();
void error(char* errerMessage);
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right);
ASTNode *mkleaf(Symbol sym, ValType val);
void yuyi_analyse();
void print_node(ASTNode *root);
void middle_list(ASTNode *root);
void last_list(ASTNode *root);
//测试语义分析
void testYuyiAnalyse();
//创建运算符结点
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right);
//创建操作数结点
ASTNode *mkleaf(Symbol sym, ValType val);
//输出结点
void printNode(ASTNode *root);
//中序遍历二叉树
void middle_list(ASTNode *root);
//后序遍历二叉树
void last_list(ASTNode *root);
/*
E ::= T {E'.i:=T.nptr}
E' {E.nptr:=E'.s}
*/
//为右边的每个非终结符定义一个属性,返回E的综合属性
ASTNode* E()
{
ASTNode * E_nptr;
ASTNode * E1_i;
E1_i=T();
E_nptr=E1(E1_i);
return E_nptr;
}
/*
E'::= + T {E'1.i:=mknode('+',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= - T {E'1.i:=mknode('-',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= ε {E'.s:= E'.i}
*/
//返回的是综合属性,传递的是继承属性
ASTNode * E1(ASTNode *E1_i)
{
ASTNode * E11_i;
ASTNode * E1_s;
ASTNode * T_nptr;
char oper;
if(strcmp(strToken,"+")==0 || strcmp(strToken,"-")==0){
oper=strToken[0];
getToken();
T_nptr=T();
if(oper=='+')
E11_i=mknode(PLUS,E1_i,T_nptr);
else
E11_i=mknode(MINUS,E1_i,T_nptr);
E1_s=E1(E11_i);
}
//Follow(E1)={#,)},可以匹配空串
else if(strcmp(strToken,"#")==0 || strcmp(strToken,")")==0){
E1_s=E1_i;
}else{
error("语法分析错误!");
}
return E1_s;
}
/*
T ::= F {T'.i:=F.nptr}
T' {T.nptr:=T'.s}
*/
ASTNode* T()
{
ASTNode * T_nptr;
ASTNode * T1_i;
T1_i=F();
T_nptr=T1(T1_i);
return T_nptr;
}
/*
T'::= * F {T'1.i:=mknode('*',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T'::= / F {T'1.i:=mknode('/',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T' ::= ε {T'.s:= T'.i}
*/
ASTNode* T1(ASTNode* T1_i)
{
ASTNode* F_nptr;
ASTNode* T11_i;
ASTNode* T1_s;
char oper;
if(strcmp(strToken,"*")==0 || strcmp(strToken,"/")==0){
oper=strToken[0];
getToken();
F_nptr=F();
if(oper=='*')
T11_i=mknode(TIMES,T1_i,F_nptr);
else
T11_i=mknode(SLASH,T1_i,F_nptr);
T1_s=T1(T11_i);
}
//Follow(T1)={+,#,)},如果考虑-号的话要加上-号
else if(strcmp(strToken,"-")==0 || strcmp(strToken,"+")==0 || strcmp(strToken,"#")==0 || strcmp(strToken,")")==0){
T1_s=T1_i;
}else{
error("语法分析错误!");
}
return T1_s;
}
/*
F ::= (E) {F.nptr:=E.nptr}
F ::= num {F.nptr:=mkleaf(num,num.val)}
*/
ASTNode* F()
{
ASTNode* F_nptr;
ASTNode* E_nptr;
if(isNum(strToken)){
F_nptr=mkleaf(NUM,atoi(strToken));
getToken();
}
else{
if(strcmp(strToken,"(")==0){
getToken();
E_nptr=E();
if(strcmp(strToken,")")==0)
getToken();
else
error("语法分析错误!");
F_nptr=E_nptr;
}
else {
error("语法分析错误!");
}
}
return F_nptr;
}
//创建运算符结点
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right)
{
ASTNode* p=(ASTNode*)malloc(sizeof(ASTNode));
p->left=left;
p->right=right;
p->sym=op;
p->val=0;
return p;
}
//创建操作数结点
ASTNode *mkleaf(Symbol sym, ValType val)
{
ASTNode* p=(ASTNode*)malloc(sizeof(ASTNode));
p->sym=sym;
p->val=val;
p->left=NULL;
p->right=NULL;
return p;
}
//输出结点
void printNode(ASTNode *root)
{
if(root->sym==NUM)
printf("%d ",root->val);
else if(root->sym==PLUS)
printf("+ ");
else if(root->sym==MINUS)
printf("- ");
else if(root->sym==TIMES)
printf("* ");
else if(root->sym==SLASH)
printf("/ ");
}
//中序遍历二叉树
void middle_list(ASTNode *root)
{
if(root==NULL)
return ;
middle_list(root->left);
printNode(root);
middle_list(root->right);
}
//后序遍历二叉树
void last_list(ASTNode *root)
{
char temp[MAX_LENGTH];
if(root==NULL)
return ;
last_list(root->left);
last_list(root->right);
if(root->sym == NUM){//如果是数字,则直接存入栈中
sprintf(temp,"%d\0",root->val);
strcpy(stack[index++],temp);
}
else if(root->sym == PLUS){//如果是+号,产生一个四元式
//给四元式赋值
quaternion[count].op='+';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
//输出该四元式
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == MINUS){//如果是+号,产生一个四元式
quaternion[count].op='-';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == TIMES){//如果是*号,产生一个四元式
quaternion[count].op='*';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == SLASH){
quaternion[count].op='/';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}
}
//测试语义分析
void testYuyiAnalyse()
{
ASTNode *root;
expression_index=0;
getToken();
root=E();
puts("\n语义分析结果如下:");
printf("中序遍历:");
middle_list(root);
putchar('\n');
printf("后序遍历得到的四元式:\n");
last_list(root);
putchar('\n');
}
//主函数
int main()
{
gets(expression);
testYuyiAnalyse();
return 0;
}
#endif
运行结果
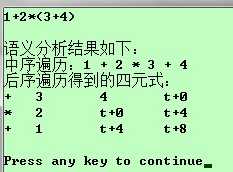
7、代码生成
要求:以实验3的语义分析程序的四元式输出作为输入,输出汇编语言程序。
test4.c
#ifndef TEST4_C
#define TEST4_C
/**
* 生产汇编代码
**/
#include"test3.c"
//传人一个四元式,输出对应的汇编代码
void print_code(Quaternion qua)
{
putchar('\n');
/*
mov eax, 3
add eax, 4
mov t+0, eax
*/
if(qua.op == '+'){
printf(" mov eax,%s\n",qua.arg1);
printf(" add eax,%s\n",qua.arg2);
printf(" mov %s,eax\n",qua.result);
}else if(qua.op == '-'){
printf(" mov eax,%s\n",qua.arg1);
printf(" sub eax,%s\n",qua.arg2);
printf(" mov %s,eax\n",qua.result);
}
/*
mov eax, 2
mov ebx, t+0
mul ebx
mov t+4, eax
*/
else if(qua.op == '*'){
printf(" mov eax,%s\n",qua.arg1);
printf(" mov ebx,%s\n",qua.arg2);
printf(" mul ebx\n");
printf(" mov %s,eax\n",qua.result);
}else if(qua.op == '/'){//除法的时候不考虑余数
printf(" mov eax,%s\n",qua.arg1);
printf(" mov ebx,%s\n",qua.arg2);
printf(" div ebx\n");
printf(" mov %s,eax\n",qua.result);
}
}
//输出全部汇编代码
void testCode()
{
int i=0;
puts("生成的汇编代码如下:\n");
puts(".386");
puts(".MODEL FLAT");
puts("ExitProcess PROTO NEAR32 stdcall, dwExitCode:DWORD");
puts("INCLUDE io.h ; header file for input/output");
puts("cr EQU 0dh ; carriage return character");
puts("Lf EQU 0ah ; line feed");
puts(".STACK 4096 ; reserve 4096-byte stack");
puts(".DATA ; reserve storage for data");
puts("t DWORD 40 DUP (?)");
puts("label1 BYTE cr, Lf, \"The result is \"");
puts("result BYTE 11 DUP (?)");
puts(" BYTE cr, Lf, 0");
puts(".CODE ; start of main program code");
puts("_start:");
//遍历实验3中的四元式,输出对应的汇编代码
for(;i<count;i++)
print_code(quaternion[i]);
puts(" dtoa result, eax ; convert to ASCII characters");
puts(" output label1 ; output label and sum");
puts(" INVOKE ExitProcess, 0 ; exit with return code 0");
puts("PUBLIC _start ; make entry point public");
puts("END ; end of source code");
}
//主函数
int main()
{
gets(expression);
testLexAnalyse();
testYuyiAnalyse();
testCode();
return 0;
}
#endif
运行结果

8、点击下载源代码
这是编译原理的实验,自认为是上大学以来做过的最难的一个实验。
实验用到的基础知识:C语言、数据结构、汇编(只需简单的了解)。
开发工具:VC
2、问题描述
编译整数四则运算表达式,将整数四则运算表达式翻译为汇编语言代码。
消除左递归后的文法:
E→TE'
E'→+TE' |ε
T→FT'
T'→*FT' |ε
F→(E) | i
消除左递归后的翻译模式:
E ::= T {E'.i:=T.nptr}
E' {E.nptr:=E'.s}
E'::= + T {E'1.i:=mknode(‘+',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= - T {E'1.i:=mknode(‘-',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= ε {E'.s:= E'.i}
T ::= F {T'.i:=F.nptr}
T' {T.nptr:=T'.s}
T'::= * F {T'1.i:=mknode(‘*',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T'::= / F {T'1.i:=mknode(‘/',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T' ::= ε {T'.s:= T'.i}
F ::= (E) {F.nptr:=E.nptr}
F ::= num {F.nptr:=mkleaf(num,num.val)}
3、全局定义
test.c文件
复制代码 代码如下:
#ifndef TEST_C
#define TEST_C
/**
* 全局变量和全局函数文件
**/
#include<stdio.h>
#include<ctype.h>
#include<string.h>
#include<stdlib.h>
/************************* 以下是全局变量(函数)的定义 *******************/
//输入的表达式最大长度,可以看做是缓冲区的长度
#define MAX_EXPRESSION_LENGTH 50
//存放输入的表达式
char expression[MAX_EXPRESSION_LENGTH];
//表达式字符数组的下标
int expression_index=0;
//存放一个单词符号
char strToken[MAX_EXPRESSION_LENGTH/2];
//判断是否是数字
int isNum(char * strToken)
{
int i=0;
while(strToken[i]){
if(!isdigit(strToken[i]))
break;
i++;
}
return strToken[i]==0;
}
//错误处理程序
void error(char* errerMessage)
{
printf("\nERROR:%s\n",errerMessage);
exit(0);
}
/************************* 以上是全局变量(函数)的定义 ******************/
#endif
4、词法分析
词法分析的要求是:接受一个表达式,输出该表达式中的各类单词符号
一般有两种方法来进行词法分析,一种是用状态图来实现,一种是用状态转换表。下面采用状态图实现
首先定义单词符号的种类和所属类型
typedef enum Symbol { ERR = -1, END, NUM, PLUS, MINUS, TIMES, SLASH, LPAREN, RPAREN } Symbol;
然后转态转换图如下所示:

test1.c文件用代码表示如下:
复制代码 代码如下:
#ifndef TEST1_C
#define TEST1_C
/**
* 采用状态图进行词法分析以及测试词法分析
*
**/
#include"test.c"
//枚举类型
typedef enum Symbol { ERR = -1, END, NUM, PLUS, MINUS, TIMES,
SLASH, LPAREN, RPAREN } Symbol;
//获取一个单词符号,该单词符号存放在strToken中。返回该单词符号的枚举类型
Symbol getToken();
//根据传入的枚举类型输出对应的单词符号
void printToken(Symbol i);
//测试词法分析
void testLexAnalyse();
//获取一个单词符号,该单词符号存放在strToken中。返回该单词符号的枚举类型
Symbol getToken()
{
char ch;
int state=0;//每次都是从状态0开始
int j=0;
//表达式遍历完成,单词符号为'#'
if(expression[expression_index]=='\0'){
strToken[0]='#';
strToken[1]='\0';
return END;
}
while(1){
switch(state){
case 0:
//读取一个字符
ch=strToken[j++]=expression[expression_index++];
if(isspace(ch)){
j--;//注意退格
state=0;
}
else if(isdigit(ch))
state=1;
else if(ch=='+')
state=2;
else if(ch=='-')
state=3;
else if(ch=='*')
state=4;
else if(ch=='/')
state=5;
else if(ch=='(')
state=6;
else if(ch==')')
state=7;
else
return ERR;
break;
case 1:
ch=strToken[j++]=expression[expression_index++];
if(isdigit(ch))
state=1;
else{
expression_index--;
strToken[--j]=0;
return NUM;
}
break;
case 2:
strToken[j]=0;
return PLUS;
case 3:
strToken[j]=0;
return MINUS;
case 4:
strToken[j]=0;
return TIMES;
case 5:
strToken[j]=0;
return SLASH;
case 6:
strToken[j]=0;
return LPAREN;
case 7:
strToken[j]=0;
return RPAREN;
}
}
}
//根据传入的枚举类型输出对应的单词符号
void printToken(Symbol i){
switch(i){
case -1:printf("ERR\n");break;
case 0:printf("END\n");break;
case 1:printf("NUM %s\n",strToken);break;
case 2:printf("PLUS %s\n",strToken);break;
case 3:printf("MINUS %s\n",strToken);break;
case 4:printf("TIMES %s\n",strToken);break;
case 5:printf("SLASH %s\n",strToken);break;
case 6:printf("LPAREN %s\n",strToken);break;
case 7:printf("RPAREN %s\n",strToken);break;
}
}
//测试词法分析
void testLexAnalyse()
{
Symbol tokenStyle;//单词符号类型
expression_index=0;
puts("\n词法分析结果如下:");
while(1){
tokenStyle=getToken();
printToken(tokenStyle);
if(tokenStyle == ERR){
error("词法分析错误!");
}
if(tokenStyle == END){
break;
}
}
}
//主函数
int main()
{
gets(expression);
testLexAnalyse();
return 0;
}
#endif
运行结果

5、语法分析
要求:接受一个表达式,分析该表达式,并根据输入正确与否给出相应信息
主要是根据无左递归文法写出对应的各个子程序
test2.c
复制代码 代码如下:
#ifndef TEST_2
#define TEST_2
/**
* 语法分析以及测试语法分析
**/
#include"test1.c"
/*
消除左递归后的文法:
E→TE'
E'→+TE' |ε
T→FT'
T'→*FT' |ε
F→(E) | i
*/
//每个非终结符有对应的子程序函数声明
void E();
void E1();
void T();
void T1();
void F();
//测试语法分析
void testSyntaxAnalyse();
//每个非终结符有对应的子程序
void E()
{
T();
E1();
}
void E1()
{
if(strcmp(strToken,"+")==0 || strcmp(strToken,"-")==0){
getToken();
T();
E1();
}
//Follow(E1)={#,)}
else if(strcmp(strToken,"#")!=0 && strcmp(strToken,")")!=0){
error("语法分析错误!");
}
}
void T()
{
F();
T1();
}
void T1()
{
if(strcmp(strToken,"*")==0 || strcmp(strToken,"/")==0){
getToken();
F();
T1();
}
//Follow(T1)={+,#,)},如果考虑-号的话要加上-号
else if(strcmp(strToken,"-")!=0 &&strcmp(strToken,"+")!=0 && strcmp(strToken,"#")!=0 && strcmp(strToken,")")!=0){
error("语法分析错误!");
}
}
void F()
{
if(isNum(strToken)){
getToken();
}
else{
if(strcmp(strToken,"(")==0){
getToken();
E();
if(strcmp(strToken,")")==0)
getToken();
else
error("语法分析错误!");
}
else
error("语法分析错误!");
}
}
//测试语法分析
void testSyntaxAnalyse()
{
expression_index=0;
getToken();
E();
puts("\n语法分析结果如下:");
if(strcmp(strToken,"#")!=0)
error("语法分析错误!");
else{
puts("语法分析正确!");
}
}
//主函数
int main()
{
gets(expression);
testLexAnalyse();
testSyntaxAnalyse();
return 0;
}
#endif
运行时要删掉test1.c中的主函数,运行结果

6、语义分析
要求:需要实现的语义分析程序的功能是,接受一个表达式,分析该表达式,并在分析的过程中建立该表达式的抽象语法树。由于四则运算表达式的抽象语法树可基本上看作是二叉树,因此中序遍历序列应该和输入的表达式一样——除了没有括号之外。可输出中序遍历序列检测程序功能是否正确。如果每个分支节点用一个临时变量标记,则对四则运算表达式的抽象语法树进行后序遍历,可以得到输入表达式所对应的四元式序列
test3.c文件
复制代码 代码如下:
#ifndef TEST3_C
#define TEST3_C
/**
* 语义分析以及测试语义分析
* 其实这个实验是在test2的代码上进行修改
**/
#include"test1.c"
/*
消除左递归的翻译模式:
E ::= T {E'.i:=T.nptr}
E' {E.nptr:=E'.s}
E'::= + T {E'1.i:=mknode('+',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= - T {E'1.i:=mknode('-',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= ε {E'.s:= E'.i}
T ::= F {T'.i:=F.nptr}
T' {T.nptr:=T'.s}
T'::= * F {T'1.i:=mknode('*',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T'::= / F {T'1.i:=mknode('/',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T' ::= ε {T'.s:= T'.i}
F ::= (E) {F.nptr:=E.nptr}
F ::= num {F.nptr:=mkleaf(num,num.val)}
*/
#define MAX_LENGTH 20 //四元式中操作数的最大长度
typedef int ValType;
//结点类型
typedef struct ASTNode {
Symbol sym;//类型
ValType val;//值
struct ASTNode * left, *right;//左、右孩子
}ASTNode, *AST;
//四元式类型定义如下
typedef struct Quaternion{
char op;
char arg1[MAX_LENGTH];
char arg2[MAX_LENGTH];
char result[MAX_LENGTH];
}Quaternion;
//四元式数组,存放产生的四元式
Quaternion quaternion[MAX_LENGTH*2];
//统计四元式的个数
int count=0;
//后序遍历抽象语法树时存放操作数和临时变量,这里当作一个栈来使用
char stack[MAX_LENGTH*2][MAX_LENGTH];
//stack栈的下标
int index=0;
//内存中临时数据存储地址的偏移量
int t=-4;
//函数声明
ASTNode* E();
ASTNode* E1(ASTNode* E1_i);
ASTNode* T();
ASTNode* T1(ASTNode* T1_i);
ASTNode* F();
void error(char* errerMessage);
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right);
ASTNode *mkleaf(Symbol sym, ValType val);
void yuyi_analyse();
void print_node(ASTNode *root);
void middle_list(ASTNode *root);
void last_list(ASTNode *root);
//测试语义分析
void testYuyiAnalyse();
//创建运算符结点
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right);
//创建操作数结点
ASTNode *mkleaf(Symbol sym, ValType val);
//输出结点
void printNode(ASTNode *root);
//中序遍历二叉树
void middle_list(ASTNode *root);
//后序遍历二叉树
void last_list(ASTNode *root);
/*
E ::= T {E'.i:=T.nptr}
E' {E.nptr:=E'.s}
*/
//为右边的每个非终结符定义一个属性,返回E的综合属性
ASTNode* E()
{
ASTNode * E_nptr;
ASTNode * E1_i;
E1_i=T();
E_nptr=E1(E1_i);
return E_nptr;
}
/*
E'::= + T {E'1.i:=mknode('+',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= - T {E'1.i:=mknode('-',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= ε {E'.s:= E'.i}
*/
//返回的是综合属性,传递的是继承属性
ASTNode * E1(ASTNode *E1_i)
{
ASTNode * E11_i;
ASTNode * E1_s;
ASTNode * T_nptr;
char oper;
if(strcmp(strToken,"+")==0 || strcmp(strToken,"-")==0){
oper=strToken[0];
getToken();
T_nptr=T();
if(oper=='+')
E11_i=mknode(PLUS,E1_i,T_nptr);
else
E11_i=mknode(MINUS,E1_i,T_nptr);
E1_s=E1(E11_i);
}
//Follow(E1)={#,)},可以匹配空串
else if(strcmp(strToken,"#")==0 || strcmp(strToken,")")==0){
E1_s=E1_i;
}else{
error("语法分析错误!");
}
return E1_s;
}
/*
T ::= F {T'.i:=F.nptr}
T' {T.nptr:=T'.s}
*/
ASTNode* T()
{
ASTNode * T_nptr;
ASTNode * T1_i;
T1_i=F();
T_nptr=T1(T1_i);
return T_nptr;
}
/*
T'::= * F {T'1.i:=mknode('*',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T'::= / F {T'1.i:=mknode('/',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T' ::= ε {T'.s:= T'.i}
*/
ASTNode* T1(ASTNode* T1_i)
{
ASTNode* F_nptr;
ASTNode* T11_i;
ASTNode* T1_s;
char oper;
if(strcmp(strToken,"*")==0 || strcmp(strToken,"/")==0){
oper=strToken[0];
getToken();
F_nptr=F();
if(oper=='*')
T11_i=mknode(TIMES,T1_i,F_nptr);
else
T11_i=mknode(SLASH,T1_i,F_nptr);
T1_s=T1(T11_i);
}
//Follow(T1)={+,#,)},如果考虑-号的话要加上-号
else if(strcmp(strToken,"-")==0 || strcmp(strToken,"+")==0 || strcmp(strToken,"#")==0 || strcmp(strToken,")")==0){
T1_s=T1_i;
}else{
error("语法分析错误!");
}
return T1_s;
}
/*
F ::= (E) {F.nptr:=E.nptr}
F ::= num {F.nptr:=mkleaf(num,num.val)}
*/
ASTNode* F()
{
ASTNode* F_nptr;
ASTNode* E_nptr;
if(isNum(strToken)){
F_nptr=mkleaf(NUM,atoi(strToken));
getToken();
}
else{
if(strcmp(strToken,"(")==0){
getToken();
E_nptr=E();
if(strcmp(strToken,")")==0)
getToken();
else
error("语法分析错误!");
F_nptr=E_nptr;
}
else {
error("语法分析错误!");
}
}
return F_nptr;
}
//创建运算符结点
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right)
{
ASTNode* p=(ASTNode*)malloc(sizeof(ASTNode));
p->left=left;
p->right=right;
p->sym=op;
p->val=0;
return p;
}
//创建操作数结点
ASTNode *mkleaf(Symbol sym, ValType val)
{
ASTNode* p=(ASTNode*)malloc(sizeof(ASTNode));
p->sym=sym;
p->val=val;
p->left=NULL;
p->right=NULL;
return p;
}
//输出结点
void printNode(ASTNode *root)
{
if(root->sym==NUM)
printf("%d ",root->val);
else if(root->sym==PLUS)
printf("+ ");
else if(root->sym==MINUS)
printf("- ");
else if(root->sym==TIMES)
printf("* ");
else if(root->sym==SLASH)
printf("/ ");
}
//中序遍历二叉树
void middle_list(ASTNode *root)
{
if(root==NULL)
return ;
middle_list(root->left);
printNode(root);
middle_list(root->right);
}
//后序遍历二叉树
void last_list(ASTNode *root)
{
char temp[MAX_LENGTH];
if(root==NULL)
return ;
last_list(root->left);
last_list(root->right);
if(root->sym == NUM){//如果是数字,则直接存入栈中
sprintf(temp,"%d\0",root->val);
strcpy(stack[index++],temp);
}
else if(root->sym == PLUS){//如果是+号,产生一个四元式
//给四元式赋值
quaternion[count].op='+';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
//输出该四元式
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == MINUS){//如果是+号,产生一个四元式
quaternion[count].op='-';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == TIMES){//如果是*号,产生一个四元式
quaternion[count].op='*';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == SLASH){
quaternion[count].op='/';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}
}
//测试语义分析
void testYuyiAnalyse()
{
ASTNode *root;
expression_index=0;
getToken();
root=E();
puts("\n语义分析结果如下:");
printf("中序遍历:");
middle_list(root);
putchar('\n');
printf("后序遍历得到的四元式:\n");
last_list(root);
putchar('\n');
}
//主函数
int main()
{
gets(expression);
testYuyiAnalyse();
return 0;
}
#endif
运行结果

7、代码生成
要求:以实验3的语义分析程序的四元式输出作为输入,输出汇编语言程序。
test4.c
复制代码 代码如下:
#ifndef TEST4_C
#define TEST4_C
/**
* 生产汇编代码
**/
#include"test3.c"
//传人一个四元式,输出对应的汇编代码
void print_code(Quaternion qua)
{
putchar('\n');
/*
mov eax, 3
add eax, 4
mov t+0, eax
*/
if(qua.op == '+'){
printf(" mov eax,%s\n",qua.arg1);
printf(" add eax,%s\n",qua.arg2);
printf(" mov %s,eax\n",qua.result);
}else if(qua.op == '-'){
printf(" mov eax,%s\n",qua.arg1);
printf(" sub eax,%s\n",qua.arg2);
printf(" mov %s,eax\n",qua.result);
}
/*
mov eax, 2
mov ebx, t+0
mul ebx
mov t+4, eax
*/
else if(qua.op == '*'){
printf(" mov eax,%s\n",qua.arg1);
printf(" mov ebx,%s\n",qua.arg2);
printf(" mul ebx\n");
printf(" mov %s,eax\n",qua.result);
}else if(qua.op == '/'){//除法的时候不考虑余数
printf(" mov eax,%s\n",qua.arg1);
printf(" mov ebx,%s\n",qua.arg2);
printf(" div ebx\n");
printf(" mov %s,eax\n",qua.result);
}
}
//输出全部汇编代码
void testCode()
{
int i=0;
puts("生成的汇编代码如下:\n");
puts(".386");
puts(".MODEL FLAT");
puts("ExitProcess PROTO NEAR32 stdcall, dwExitCode:DWORD");
puts("INCLUDE io.h ; header file for input/output");
puts("cr EQU 0dh ; carriage return character");
puts("Lf EQU 0ah ; line feed");
puts(".STACK 4096 ; reserve 4096-byte stack");
puts(".DATA ; reserve storage for data");
puts("t DWORD 40 DUP (?)");
puts("label1 BYTE cr, Lf, \"The result is \"");
puts("result BYTE 11 DUP (?)");
puts(" BYTE cr, Lf, 0");
puts(".CODE ; start of main program code");
puts("_start:");
//遍历实验3中的四元式,输出对应的汇编代码
for(;i<count;i++)
print_code(quaternion[i]);
puts(" dtoa result, eax ; convert to ASCII characters");
puts(" output label1 ; output label and sum");
puts(" INVOKE ExitProcess, 0 ; exit with return code 0");
puts("PUBLIC _start ; make entry point public");
puts("END ; end of source code");
}
//主函数
int main()
{
gets(expression);
testLexAnalyse();
testYuyiAnalyse();
testCode();
return 0;
}
#endif
运行结果

8、点击下载源代码
相关文章
 这篇文章介绍了数组循环移位操作实例,有需要的朋友可以参考一下2013-09-09
这篇文章介绍了数组循环移位操作实例,有需要的朋友可以参考一下2013-09-09
VSCode插件开发全攻略之跳转到定义、自动补全、悬停提示功能
这篇文章主要介绍了VSCode插件开发全攻略之跳转到定义、自动补全、悬停提示,需要的朋友可以参考下2020-05-05 这篇文章主要介绍了C语言完成排序的实例,在C语言基本类型的排序中特别有用,下面我们一起进入文章学习更详细的内容吧,需要的朋友可以参考下2022-03-03
这篇文章主要介绍了C语言完成排序的实例,在C语言基本类型的排序中特别有用,下面我们一起进入文章学习更详细的内容吧,需要的朋友可以参考下2022-03-03 这篇文章主要为大家详细介绍了opencv+arduino实现物体点追踪效果,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-01-01
这篇文章主要为大家详细介绍了opencv+arduino实现物体点追踪效果,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-01-01
OPENMP SECTIONS CONSTRUCT原理示例解析
这篇文章主要为大家介绍了OPENMP SECTIONS CONSTRUCT原理示例解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-03-03 C++ 允许多个函数拥有相同的名字,只要它们的参数列表不同就可以,这就是函数的重载(Function Overloading),借助重载,一个函数名可以有多种用途2022-07-07
C++ 允许多个函数拥有相同的名字,只要它们的参数列表不同就可以,这就是函数的重载(Function Overloading),借助重载,一个函数名可以有多种用途2022-07-07 代理服务器,即允许一个网络终端(一般为客户端)通过这个服务与另一 个网络终端(一般为服务器)进行非直接的连接,下面我们就来看看如何使用C++设计与实现一个HTTP 代理服务器吧2024-01-01
代理服务器,即允许一个网络终端(一般为客户端)通过这个服务与另一 个网络终端(一般为服务器)进行非直接的连接,下面我们就来看看如何使用C++设计与实现一个HTTP 代理服务器吧2024-01-01 这篇文章主要介绍了VC++ 中ListCtrl经验总结的相关资料,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了VC++ 中ListCtrl经验总结的相关资料,需要的朋友可以参考下2015-06-06 这篇文章主要为大家详细介绍了Qt自定义美化滑动条的相关知识,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2024-11-11
这篇文章主要为大家详细介绍了Qt自定义美化滑动条的相关知识,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2024-11-11 本文主要介绍了Qt在线安装加速的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02
本文主要介绍了Qt在线安装加速的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02










最新评论