
Java实现爬虫给App提供数据(Jsoup 网络爬虫)
一、需求
最近基于 Material Design 重构了自己的新闻 App,数据来源是个问题。
有前人分析了知乎日报、凤凰新闻等 API,根据相应的 URL 可以获取新闻的 JSON 数据。为了锻炼写代码能力,笔者打算爬虫新闻页面,自己获取数据构建 API。
二、效果图
下图是原网站的页面
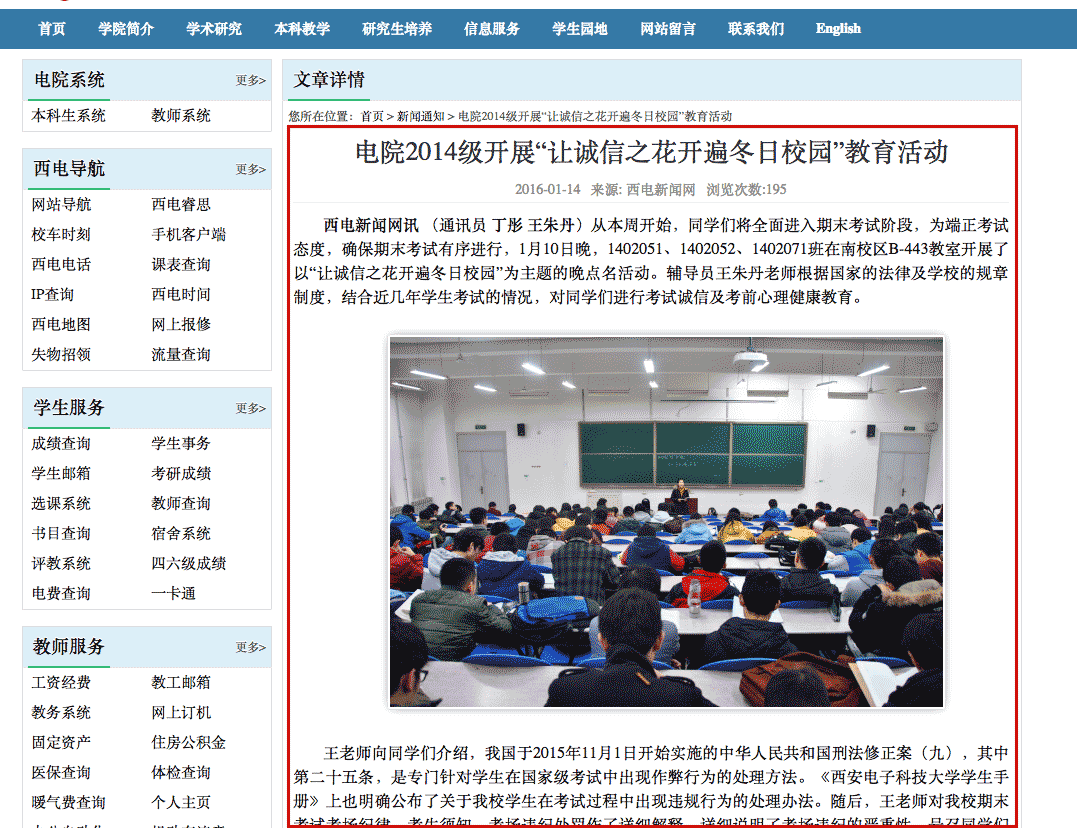
爬虫获取了数据,展示到 APP 手机端

三、爬虫思路
关于App 的实现过程可以参看这几篇文章,本文主要讲解一下如何爬虫数据。
Android下录制App操作生成Gif动态图的全过程 ://www.jb51.net/article/78236.htm
学习Android Material Design(RecyclerView代替ListView)://www.jb51.net/article/78232.htm
Android项目实战之仿网易新闻的页面(RecyclerView )://www.jb51.net/article/78230.htm
Jsoup 简介
Jsoup 是一个 Java 的开源HTML解析器,可直接解析某个URL地址、HTML文本内容。
Jsoup主要有以下功能:
- - 从一个URL,文件或字符串中解析HTML;
- - 使用DOM或CSS选择器来查找、取出数据;
- - 对HTML元素、属性、文本进行操作;
- - 清除不受信任的HTML (来防止XSS攻击)
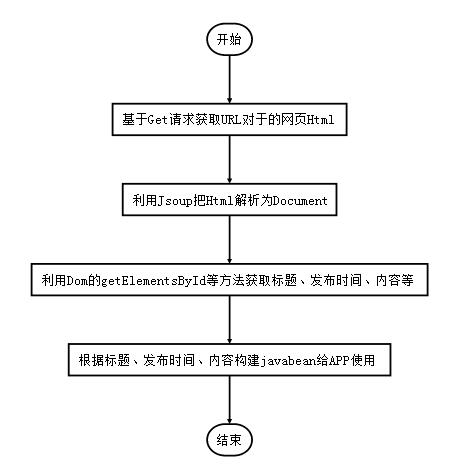
四、爬虫过程
Get 请求获取网页 HTML
新闻网页Html的DOM树如下所示:

下面这段代码根据指定的 url,用代码获取get 请求返回的 html 源代码。
public static String doGet(String urlStr) throws CommonException {
URL url;
String html = "";
try {
url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setDoInput(true);
connection.setDoOutput(true);
if (connection.getResponseCode() == 200) {
InputStream in = connection.getInputStream();
html = StreamTool.inToStringByByte(in);
} else {
throw new CommonException("新闻服务器返回值不为200");
}
} catch (Exception e) {
e.printStackTrace();
throw new CommonException("get请求失败");
}
return html;
}
InputStream in = connection.getInputStream();将得到输入流转化为字符串是个普遍需求,我们将其抽象出来,写一个工具方法。
public class StreamTool {
public static String inToStringByByte(InputStream in) throws Exception {
ByteArrayOutputStream outStr = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = 0;
StringBuilder content = new StringBuilder();
while ((len = in.read(buffer)) != -1) {
content.append(new String(buffer, 0, len, "UTF-8"));
}
outStr.close();
return content.toString();
}
}
五、解析 HTML 获取标题
利用 google 浏览器的审查元素,找出新闻标题对于的html 代码:
<div id="article_title"> <h1> <a href="http://see.xidian.edu.cn/html/news/7428.html"> 关于举办《经典音乐作品欣赏与人文审美》讲座的通知 </a> </h1> </div>
我们需要从上面的 HTML 中找出id="article_title"的部分,使用 getElementById(String id) 方法
String htmlStr = HttpTool.doGet(urlStr);
// 将获取的网页 HTML 源代码转化为 Document
Document doc = Jsoup.parse(htmlStr);
Element articleEle = doc.getElementById("article");
// 标题
Element titleEle = articleEle.getElementById("article_title");
String titleStr = titleEle.text();
六、获取发布日期、信息来源
同样找出对于的 HTML 代码
<html> <head></head> <body> <div id="article_detail"> <span> 2015-05-28 </span> <span> 来源: </span> <span> 浏览次数: <script language="JavaScript" src="http://see.xidian.edu.cn/index.php/news/click/id/7428"> </script> 477 </span> </div> </body> </html>
思路也和上面类似,使用 getElementById(String id) 方法找出id="article_detail"为Element,再利用getElementsByTag获取span 部分。因为一共有3个<span> ... </span>,所以返回的是Elements而不是Element。
// article_detail包括了 2016-01-15 来源: 浏览次数:177
Element detailEle = articleEle.getElementById("article_detail");
Elements details = detailEle.getElementsByTag("span");
// 发布时间
String dateStr = details.get(0).text();
// 新闻来源
String sourceStr = details.get(1).text();
七、解析浏览次数
如果打印出上面的details.get(2).text(),只会得到
浏览次数:
没有浏览次数?为什么呢?
因为浏览次数是JavaScript 渲染出来的, Jsoup爬虫可能仅仅提取HTML内容,得不到动态渲染出的数据。
解决方法有两种
- 在爬虫的时候,内置一个浏览器内核,执行js渲染页面后,再抓取。这方面对应的工具有Selenium、HtmlUnit或者PhantomJs。
- 所以分析JS请求,找到对应数据的请求url
如果你访问上面的 urlhttp://see.xidian.edu.cn/index.php/news/click/id/7428,会得到下面的结果
document.write(478)
这个478就是我们需要的浏览次数,我们对上面的url做get 请求,得到返回的字符串,利用正则找出其中的数字。
// 访问这个新闻页面,浏览次数会+1,次数是 JS 渲染的
String jsStr = HttpTool.doGet(COUNT_BASE_URL + currentPage);
int readTimes = Integer.parseInt(jsStr.replaceAll("\\D+", ""));
// 或者使用下面这个正则方法
// String readTimesStr = jsStr.replaceAll("[^0-9]", "");
八、解析新闻内容
本来是获取新闻内容纯文字的形式,但后来发现 Android 端也可以显示 CSS 格式,所以后来内容保留了 HTML 格式。
Element contentEle = articleEle.getElementById("article_content");
// 新闻主体内容
String contentStr = contentEle.toString();
// 如果用 text()方法,新闻主体内容的 html 标签会丢失
// 为了在 Android 上用 WebView 显示 html,用toString()
// String contentStr = contentEle.text();
九、解析图片 Url
注意一个网页上大大小小的图片很多,为了只获取新闻正文中的内容,我们最好首先定位到新闻内容的Element,然后再利用getElementsByTag(“img”)筛选出图片。
Element contentEle = articleEle.getElementById("article_content");
// 新闻主体内容
String contentStr = contentEle.toString();
// 如果用 text()方法,新闻主体内容的 html 标签会丢失
// 为了在 Android 上用 WebView 显示 html,用toString()
// String contentStr = contentEle.text();
Elements images = contentEle.getElementsByTag("img");
String[] imageUrls = new String[images.size()];
for (int i = 0; i < imageUrls.length; i++) {
imageUrls[i] = images.get(i).attr("src");
}
十、新闻实体类 JavaBean
上面获取了新闻的标题、发布日期、阅读次数、新闻内容等等,我们自然需要构造一个 javabean,把获取的内容封装进实体类中。
public class ArticleItem {
private int index;
private String[] imageUrls;
private String title;
private String publishDate;
private String source;
private int readTimes;
private String body;
public ArticleItem(int index, String[] imageUrls, String title, String publishDate, String source, int readTimes,
String body) {
this.index = index;
this.imageUrls = imageUrls;
this.title = title;
this.publishDate = publishDate;
this.source = source;
this.readTimes = readTimes;
this.body = body;
}
@Override
public String toString() {
return "ArticleItem [index=" + index + ",\n imageUrls=" + Arrays.toString(imageUrls) + ",\n title=" + title
+ ",\n publishDate=" + publishDate + ",\n source=" + source + ",\n readTimes=" + readTimes + ",\n body=" + body
+ "]";
}
}
测试
public static ArticleItem getNewsItem(int currentPage) throws CommonException {
// 根据后缀的数字,拼接新闻 url
String urlStr = ARTICLE_BASE_URL + currentPage + ".html";
String htmlStr = HttpTool.doGet(urlStr);
Document doc = Jsoup.parse(htmlStr);
Element articleEle = doc.getElementById("article");
// 标题
Element titleEle = articleEle.getElementById("article_title");
String titleStr = titleEle.text();
// article_detail包括了 2016-01-15 来源: 浏览次数:177
Element detailEle = articleEle.getElementById("article_detail");
Elements details = detailEle.getElementsByTag("span");
// 发布时间
String dateStr = details.get(0).text();
// 新闻来源
String sourceStr = details.get(1).text();
// 访问这个新闻页面,浏览次数会+1,次数是 JS 渲染的
String jsStr = HttpTool.doGet(COUNT_BASE_URL + currentPage);
int readTimes = Integer.parseInt(jsStr.replaceAll("\\D+", ""));
// 或者使用下面这个正则方法
// String readTimesStr = jsStr.replaceAll("[^0-9]", "");
Element contentEle = articleEle.getElementById("article_content");
// 新闻主体内容
String contentStr = contentEle.toString();
// 如果用 text()方法,新闻主体内容的 html 标签会丢失
// 为了在 Android 上用 WebView 显示 html,用toString()
// String contentStr = contentEle.text();
Elements images = contentEle.getElementsByTag("img");
String[] imageUrls = new String[images.size()];
for (int i = 0; i < imageUrls.length; i++) {
imageUrls[i] = images.get(i).attr("src");
}
return new ArticleItem(currentPage, imageUrls, titleStr, dateStr, sourceStr, readTimes, contentStr);
}
public static void main(String[] args) throws CommonException {
System.out.println(getNewsItem(7928));
}
输出信息
ArticleItem [index=7928, imageUrls=[/uploads/image/20160114/20160114225911_34428.png], title=电院2014级开展“让诚信之花开遍冬日校园”教育活动, publishDate=2016-01-14, source=来源: 电影新闻网, readTimes=200, body=<div id="article_content"> <p style="text-indent:2em;" align="justify"> <strong><span style="font-size:16px;line-height:1.5;">西电新闻网讯</span></strong><span style="font-size:16px;line-height:1.5;"> (通讯员</span><strong><span style="font-size:16px;line-height:1.5;"> 丁彤 王朱丹</span></strong><span style="font-size:16px;line-height:1.5;">...)
本文讲解了如何实现Jsoup 网络爬虫,如果文章对您有帮助,那就给个赞吧。
相关文章
 这篇文章主要介绍了详解mybatis批量插入10万条数据的优化过程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-04-04
这篇文章主要介绍了详解mybatis批量插入10万条数据的优化过程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-04-04 作为分布式项目,单点登录是必不可少的,这篇文章主要介绍了SpringCloud实现SSO 单点登录的示例代码,非常具有实用价值,需要的朋友可以参考下2019-01-01
作为分布式项目,单点登录是必不可少的,这篇文章主要介绍了SpringCloud实现SSO 单点登录的示例代码,非常具有实用价值,需要的朋友可以参考下2019-01-01 这篇文章主要介绍了简单了解Java程序运行整体流程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07
这篇文章主要介绍了简单了解Java程序运行整体流程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07 这篇文章主要为大家详细介绍了Java解码H264格式视频流中的图片,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-02-02
这篇文章主要为大家详细介绍了Java解码H264格式视频流中的图片,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-02-02 Redisson非常适用于分布式锁,而我们的一项业务需要考虑分布式锁这个应用场景,于是我整合它做一个初步简单的例子(和整合redis一样)。2021-05-05
Redisson非常适用于分布式锁,而我们的一项业务需要考虑分布式锁这个应用场景,于是我整合它做一个初步简单的例子(和整合redis一样)。2021-05-05 这篇文章主要介绍了Java中深拷贝和浅拷贝的区别解析,浅拷贝是源对象和拷贝对象的存放地址不同,但被复制的源对象的引用类型属性存放的地址仍然和源对象的引用类型属性相同,修改引用类型属性的属性会影响相互影响,需要的朋友可以参考下2024-01-01
这篇文章主要介绍了Java中深拷贝和浅拷贝的区别解析,浅拷贝是源对象和拷贝对象的存放地址不同,但被复制的源对象的引用类型属性存放的地址仍然和源对象的引用类型属性相同,修改引用类型属性的属性会影响相互影响,需要的朋友可以参考下2024-01-01 这篇文章主要为大家详细介绍了SpringMVC实现文件上传和下载的工具类,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-05-05
这篇文章主要为大家详细介绍了SpringMVC实现文件上传和下载的工具类,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-05-05 这篇文章主要介绍了Mybatis查询语句返回对象和泛型集合的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-07-07
这篇文章主要介绍了Mybatis查询语句返回对象和泛型集合的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-07-07 这篇文章主要介绍了springboot v2.0.3版本多数据源配置方法,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值 ,需要的朋友可以参考下2018-11-11
这篇文章主要介绍了springboot v2.0.3版本多数据源配置方法,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值 ,需要的朋友可以参考下2018-11-11
SpringBoot集成tensorflow实现图片检测功能
TensorFlow名字的由来就是张量(Tensor)在计算图(Computational Graph)里的流动(Flow),它的基础就是前面介绍的基于计算图的自动微分,本文将给大家介绍Spring Boot集成tensorflow实现图片检测功能,需要的朋友可以参考下2024-06-06










最新评论