
Apache Flink的网络协议栈详细介绍
▼ 造成反压(2)
与没有流量控制的接收端反压机制不同,Credit 提供了更直接的控制:如果接收端的处理速度跟不上,最终它的 Credit 会减少成 0,此时发送端就不会在向网络中发送数据(数据会被序列化到 Buffer 中并缓存在发送端)。由于反压只发生在逻辑链路上,因此没必要阻断从多路复用的 TCP 连接中读取数据,也就不会影响其他的接收者接收和处理数据。
▼ Credit-based 的优势与问题
由于通过 Credit-based 流控机制,多路复用中的一个信道不会由于反压阻塞其他逻辑信道,因此整体资源利用率会增加。此外,通过完全控制正在发送的数据量,我们还能够加快 Checkpoint alignment:如果没有流量控制,通道需要一段时间才能填满网络协议栈的内部缓冲区并表明接收端不再读取数据了。在这段时间里,大量的 Buffer 不会被处理。任何 Checkpoint barrier(触发 Checkpoint 的消息)都必须在这些数据 Buffer 后排队,因此必须等到所有这些数据都被处理后才能够触发 Checkpoint(“Barrier 不会在数据之前被处理!”)。
但是,来自接收方的附加通告消息(向发送端通知 Credit)可能会产生一些额外的开销,尤其是在使用 SSL 加密信道的场景中。此外,单个输入通道( Input channel)不能使用缓冲池中的所有 Buffer,因为存在无法共享的 Exclusive buffer。新的流控协议也有可能无法做到立即发送尽可能多的数据(如果生成数据的速度快于接收端反馈 Credit 的速度),这时则可能增长发送数据的时间。虽然这可能会影响作业的性能,但由于其所有优点,通常新的流量控制会表现得更好。可能会通过增加单个通道的独占 Buffer 数量,这会增大内存开销。然而,与先前实现相比,总体内存使用可能仍然会降低,因为底层的网络协议栈不再需要缓存大量数据,因为我们总是可以立即将其传输到 Flink(一定会有相应的 Buffer 接收数据)。
在使用新的 Credit-based 流量控制时,可能还会注意到另一件事:由于我们在发送方和接收方之间缓冲较少的数据,反压可能会更早的到来。然而,这是我们所期望的,因为缓存更多数据并没有真正获得任何好处。如果要缓存更多的数据并且保留 Credit-based 流量控制,可以考虑通过增加单个输入共享 Buffer 的数量。


注意:如果需要关闭 Credit-based 流量控制,可以将这个配置添加到 flink-conf.yaml 中:taskmanager.network.credit-model:false。但是,此参数已过时,最终将与非 Credit-based 流控制代码一起删除。
4.序列号与反序列化
下图从上面的扩展了更高级别的视图,其中包含网络协议栈及其周围组件的更多详细信息,从发送算子发送记录(Record)到接收算子获取它:

在生成 Record 并将其传递出去之后,例如通过 Collector#collect(),它被传递给 RecordWriter,RecordWriter 会将 Java 对象序列化为字节序列,最终存储在 Buffer 中按照上面所描述的在网络协议栈中进行处理。RecordWriter 首先使用 SpanningRecordSerializer 将 Record 序列化为灵活的堆上字节数组。然后,它尝试将这些字节写入目标网络 Channel 的 Buffer 中。我们将在下面的章节回到这一部分。
在接收方,底层网络协议栈(Netty)将接收到的 Buffer 写入相应的输入通道(Channel)。流任务的线程最终从这些队列中读取并尝试在 RecordReader 的帮助下通过 SpillingAdaptiveSpanningRecordDeserializer 将累积的字节反序列化为 Java 对象。与序列化器类似,这个反序列化器还必须处理特殊情况,例如跨越多个网络 Buffer 的 Record,或者因为记录本身比网络缓冲区大(默认情况下为32KB,通过 taskmanager.memory.segment-size 设置)或者因为序列化 Record 时,目标 Buffer 中已经没有足够的剩余空间保存序列化后的字节数据,在这种情况下,Flink 将使用这些字节空间并继续将其余字节写入新的网络 Buffer 中。
4.1 将网络 Buffer 写入 Netty
在上图中,Credit-based 流控制机制实际上位于“Netty Server”(和“Netty Client”)组件内部,RecordWriter 写入的 Buffer 始终以空状态(无数据)添加到 Subpartition 中,然后逐渐向其中填写序列化后的记录。但是 Netty 在什么时候真正的获取并发送这些 Buffer 呢?显然,不能是 Buffer 中只要有数据就发送,因为跨线程(写线程与发送线程)的数据交换与同步会造成大量的额外开销,并且会造成缓存本身失去意义(如果是这样的话,不如直接将将序列化后的字节发到网络上而不必引入中间的 Buffer)。
在 Flink 中,有三种情况可以使 Netty 服务端使用(发送)网络 Buffer:
写入 Record 时 Buffer 变满,或者 Buffer 超时未被发送,或 发送特殊消息,例如 Checkpoint barrier。
▼ 在 Buffer 满后发送
RecordWriter 将 Record 序列化到本地的序列化缓冲区中,并将这些序列化后的字节逐渐写入位于相应 Result subpartition 队列中的一个或多个网络 Buffer中。虽然单个 RecordWriter 可以处理多个 Subpartition,但每个 Subpartition 只会有一个 RecordWriter 向其写入数据。另一方面,Netty 服务端线程会从多个 Result subpartition 中读取并像上面所说的那样将数据写入适当的多路复用信道。这是一个典型的生产者 - 消费者模式,网络缓冲区位于生产者与消费者之间,如下图所示。在(1)序列化和(2)将数据写入 Buffer 之后,RecordWriter 会相应地更新缓冲区的写入索引。一旦 Buffer 完全填满,RecordWriter 会(3)为当前 Record 剩余的字节或者下一个 Record 从其本地缓冲池中获取新的 Buffer,并将新的 Buffer 添加到相应 Subpartition 的队列中。这将(4)通知 Netty服务端线程有新的数据可发送(如果 Netty 还不知道有可用的数据的话4)。每当 Netty 有能力处理这些通知时,它将(5)从队列中获取可用 Buffer 并通过适当的 TCP 通道发送它。

注释4:如果队列中有更多已完成的 Buffer,我们可以假设 Netty 已经收到通知。
▼ 在 Buffer 超时后发送
为了支持低延迟应用,我们不能只等到 Buffer 满了才向下游发送数据。因为可能存在这种情况,某种通信信道没有太多数据,等到 Buffer 满了在发送会不必要地增加这些少量 Record 的处理延迟。因此,Flink 提供了一个定期 Flush 线程(the output flusher)每隔一段时间会将任何缓存的数据全部写出。可以通过 StreamExecutionEnvironment#setBufferTimeout 配置 Flush 的间隔,并作为延迟5的上限(对于低吞吐量通道)。下图显示了它与其他组件的交互方式:RecordWriter 如前所述序列化数据并写入网络 Buffer,但同时,如果 Netty 还不知道有数据可以发送,Output flusher 会(3,4)通知 Netty 服务端线程数据可读(类似与上面的“buffer已满”的场景)。当 Netty 处理此通知(5)时,它将消费(获取并发送)Buffer 中的可用数据并更新 Buffer 的读取索引。Buffer 会保留在队列中——从 Netty 服务端对此 Buffer 的任何进一步操作将在下次从读取索引继续读取。

注释5:严格来说,Output flusher 不提供任何保证——它只向 Netty 发送通知,而 Netty 线程会按照能力与意愿进行处理。这也意味着如果存在反压,则 Output flusher 是无效的。
▼ 特殊消息后发送
一些特殊的消息如果通过 RecordWriter 发送,也会触发立即 Flush 缓存的数据。其中最重要的消息包括 Checkpoint barrier 以及 end-of-partition 事件,这些事件应该尽快被发送,而不应该等待 Buffer 被填满或者 Output flusher 的下一次 Flush。
▼ 进一步的讨论
与小于 1.5 版本的 Flink 不同,请注意(a)网络 Buffer 现在会被直接放在 Subpartition 的队列中,(b)网络 Buffer 不会在 Flush 之后被关闭。这给我们带来了一些好处:
同步开销较少(Output flusher 和 RecordWriter 是相互独立的) 在高负荷情况下,Netty 是瓶颈(直接的网络瓶颈或反压),我们仍然可以在未完成的 Buffer 中填充数据 Netty 通知显著减少
但是,在低负载情况下,可能会出现 CPU 使用率和 TCP 数据包速率的增加。这是因为,Flink 将使用任何可用的 CPU 计算能力来尝试维持所需的延迟。一旦负载增加,Flink 将通过填充更多的 Buffer 进行自我调整。由于同步开销减少,高负载场景不会受到影响,甚至可以实现更高的吞吐。
4.2 BufferBuilder 和 BufferConsumer
更深入地了解 Flink 中是如何实现生产者 - 消费者机制,需要仔细查看 Flink 1.5 中引入的 BufferBuilder 和 BufferConsumer 类。虽然读取是以 Buffer 为粒度,但写入它是按 Record 进行的,因此是 Flink 中所有网络通信的核心路径。因此,我们需要在任务线程(Task thread)和 Netty 线程之间实现轻量级连接,这意味着尽量小的同步开销。你可以通过查看源代码获取更加详细的信息。
5. 延迟与吞吐
引入网络 Buffer 的目是获得更高的资源利用率和更高的吞吐,代价是让 Record 在 Buffer 中等待一段时间。虽然可以通过 Buffer 超时给出此等待时间的上限,但可能很想知道有关这两个维度(延迟和吞吐)之间权衡的更多信息,显然,无法两者同时兼得。下图显示了不同的 Buffer 超时时间下的吞吐,超时时间从 0 开始(每个 Record 直接 Flush)到 100 毫秒(默认值),测试在具有 100 个节点每个节点 8 个 Slot 的群集上运行,每个节点运行没有业务逻辑的 Task 因此只用于测试网络协议栈的能力。为了进行比较,我们还测试了低延迟改进(如上所述)之前的 Flink 1.4 版本。

如图,使用 Flink 1.5+,即使是非常低的 Buffer 超时(例如1ms)(对于低延迟场景)也提供高达超时默认参数(100ms)75% 的最大吞吐,但会缓存更少的数据。
6.结论
了解 Result partition,批处理和流式计算的不同网络连接以及调度类型,Credit-Based 流量控制以及 Flink 网络协议栈内部的工作机理,有助于更好的理解网络协议栈相关的参数以及作业的行为。后续我们会推出更多 Flink 网络栈的相关内容,并深入更多细节,包括运维相关的监控指标(Metrics),进一步的网络调优策略以及需要避免的常见错误等。
以上就是小编为大家带来的Apache Flink的网络协议栈详细介绍的全部内容,希望能对您有所帮助,小伙伴们有空可以来脚本之家网站,我们的网站上还有许多其它的资料等着小伙伴来挖掘哦!
相关文章
 物联网简称iot,本文中为大家的是物联网的7大协议以及对比,有需要的朋友可以阅读本文参考一下2019-06-28
物联网简称iot,本文中为大家的是物联网的7大协议以及对比,有需要的朋友可以阅读本文参考一下2019-06-28 HTTP和DNS这两种协议几乎已经成为家喻户晓,现在5G时代的来临,这些协议也都将发生巨大的变化,本文就介绍下HTTP和DNS这些协议在未来会如何发展的,如何改变的2017-07-05
HTTP和DNS这两种协议几乎已经成为家喻户晓,现在5G时代的来临,这些协议也都将发生巨大的变化,本文就介绍下HTTP和DNS这些协议在未来会如何发展的,如何改变的2017-07-05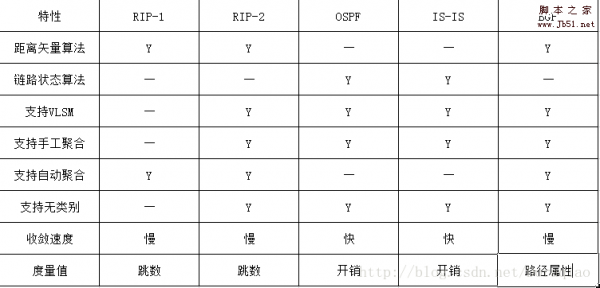
最常用路由协议RIP-1/2 OSPF IS-IS BGP的特点对比
RIP协议是最早的路由协议,OSPF是目前应用最广泛的IGP协议,IS-IS是另外一种链路状态型的路由协议,BGP协议是唯一的EGP协议,那么这几种路由协议有什么特点和不同呢?下面就2017-04-06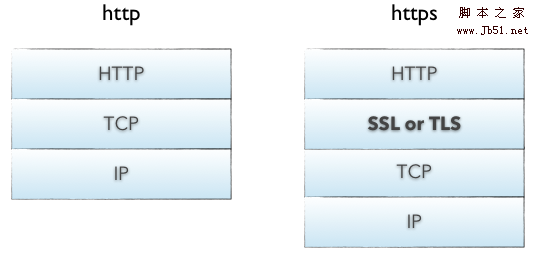
如何屏蔽https网站、禁止访问https、禁止跳转https的方法
由于网络安全形势越发严峻,为了保护用户隐私和网络安全,越来越多的网站都开启了HTTPS,如何禁止访问HTTPS网站、如何屏蔽HTTPS网站就成为重要的网络管理工作,下面就来看2017-03-29无线网络IEEE802.11/IEEE802.3协议标准和区别
IEEE802协议是一种物理协议集,而以太网协议是由一组IEEE 802.3标准定义的局域网协议集,下面就为大家介绍下IEEE802.11/IEEE802.3协议标准和区别,大家了解下吧2017-03-27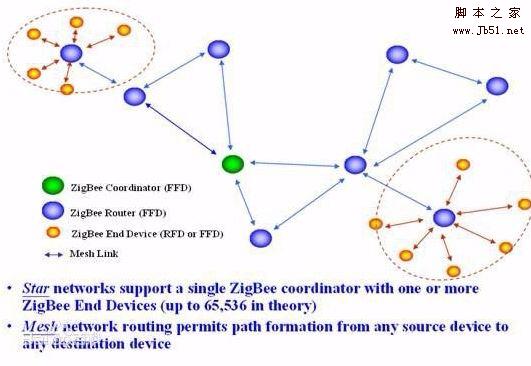
LoRa与ZigBee有什么区别?LoRa与ZigBee技术全面分析
ZigBee是基于IEEE802.15.4标准的低功耗局域网协议,LoRa 是LPWAN通信技术中的一种,那么两者之间有什么区别和联系呢?下面就详情来为大家解析下,希望对大家有帮助2017-03-26- 报文是HTTP协议下请求和响应的信息基础,这里就带大家来逐步解读HTTP报文的组成及含义,需要的朋友可以参考下2016-06-16
- 这篇文章主要介绍了SIP协议错误代码code大全(中英文对照),需要的朋友可以参考下2016-05-16
- 这篇文章主要为大家详细介绍了查看电脑MAC地址的方法,教大家如何查看电脑的MAC地址,感兴趣的小伙伴们可以参考一下2016-04-06
- 这篇文章主要介绍了图解TCP/IP协议,帮助大家轻松学会TCP/IP协议,需要的朋友可以参考下2015-12-16





最新评论