
基于Java实现一个高效可伸缩的计算结果缓存
概述
现在的软件开发中几乎所有的应用都会用到某种形式的缓存,重用之前的计算结果能够降低延迟,提高系统吞吐量,但是需要消耗更多的内存,是一种以空间换时间的方法。和许多重复造的轮子一样,缓存看起来很简单,无非就是把所有的计算结果保存下来,下次使用的时候优先使用缓存中已经保存的结果,没有的情况下才去重新计算。但是不合理的缓存机制设计却会让程序的性能受到影响,本文就通过对一个计算结果缓存的设计迭代介绍,分析每个版本的并发缺陷,并分析如何修复这些缺陷,最终完成一个高效可伸缩的计算结果缓存。
1.缓存实现
为了演示,我们定义一个计算接口Computable<A,V>,并在接口中声明一个函数compute(A arg),其输入的值为A类型的,返回的值为V类型的,接口定义如下所示:
public interface Computable<A,V> {
V compute(A arg) throws InterruptedException;
}1.1 使用HashMap+Synchronized实现缓存
第一种方式是我们使用HashMap做缓存的容器,因为HashMap不是线程安全的,所以我们需要加上synchronized同步机制来保证数据的存取安全。
代码如下:
public class HashMapMemoizer<A,V> implements Computable<A,V>{
private final Map<A,V> cache = new HashMap<>();
private final Computable<A,V> computable;
private HashMapMemoizer(Computable<A,V> computable){
this.computable = computable;
}
@Override
public synchronized V compute(A arg) throws InterruptedException {
V res = cache.get(arg);
if (res == null) {
res = computable.compute(arg);
cache.put(arg,res);
}
return res;
}
}如上面的代码所示,我们使用HashMap保存之前的计算结果,我们每次在计算结果时,先去检查缓存中是否存在,如果存在则返回缓存中的结果,否则重新计算结果并将其放到缓存中,然后再返回结果。由于HashMap不是线程安全的,所以我们无法确保两个线程不会同时访问HashMap,所以我们对整个compute方法添加synchronized关键字对方法进行同步。这种方法可以保证线程安全型,但是会有一个明显的问题,那就是每次只有一个线程能够执行compute,如果另一个线程正在计算结果,由于计算是很耗时的,那么其他调用compute方法的线程可能会被阻塞很长时间。如果多个线程在排队等待还未计算出的结果,那么compute方法的计算时间可能比没有缓存操作的计算时间更长,那么缓存就失去了意义。
1.2 使用ConcurrentHashMap代替HashMap改进缓存的并发
由于ConcurrentHashMap是线程安全的,因此在访问底层Map时就不需要进行同步,因此可以避免在对compute方法进行同步时带来的多个线程排队等待还未计算出的结果的问题
改进后的代码如下所示:
public class ConcurrentHashMapMemoizer<A,V> implements Computable<A,V>{
private final Map<A,V> cache = new ConcurrentHashMap<>();
private final Computable<A,V> computable;
private ConcurrentHashMapMemoizer(Computable<A,V> computable){
this.computable = computable;
}
@Override
public V compute(A arg) throws InterruptedException {
V res = cache.get(arg);
if (res == null) {
res = computable.compute(arg);
cache.put(arg,res);
}
return res;
}
}注意:这种方式有着比第一种方式更好的并发行为,多个线程可以并发的使用它,但是它在做缓存时仍然存在一些不足,这个不足就是当两个线程同时调用compute方法时,可能会导致计算得到相同的值。因为缓存的作用就是避免相同的数据被计算多次。对于更通用的缓存机制来说,这种情况将更严重。而假设用于只提供单次初始化的对象来说,这个问题就会带来安全风险。
1.3 完成可伸缩性高效缓存的最终方案
使用ConcurrentHashMap的问题在于如果某个线程启动了一个开销很大的计算,而其他线程并不知道这个计算正在进行,那么就很有可能重复这个计算。所以我们希望能通过某种方法来表达“线程X正在进行f(10)这个耗时计算”,这样当另外一个线程查找f(10)时,它能够知道目前已经有线程在计算它想要的值了,目前最高效的办法是等线程X计算结束,然后再去查缓存找到f(10)的结果是多少。而FutureTask正好可以实现这个功能。我们可以使用FutureTask表示一个计算过程,这个过程可能已经计算完成,也可能正在进行。如果有结果可以用,那么FutureTask.get()方法将会立即返回结果,否则它会一直阻塞,知道结果计算出来再将其返回
我们将前面用于缓存值的Map重新定义为ConcurrentHashMap<A, Future<V>>,替换原来的ConcurrentHashMap<A, V>,代码如下所示:
public class PerfectMemoizer<A, V> implements Computable<A, V> {
private final ConcurrentHashMap<A, Future<V>> cache
= new ConcurrentHashMap<>();
private final Computable<A, V> computable;
public PerfectMemoizer(Computable<A, V> computable) {
this.computable = computable;
}
@Override
public V compute(final A arg) throws InterruptedException {
while (true) {
Future<V> f = cache.get(arg);
if (f == null) {
Callable<V> eval = new Callable<V>() {
@Override
public V call() throws Exception {
return computable.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<>(eval);
f = cache.putIfAbsent(arg, ft);
if (f == null) {
f = ft;
ft.run();
}
}
try {
return f.get();
} catch (CancellationException e) {
cache.remove(arg);
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
}
}
}如上面代码所示,我们首先检测某个相应的计算是否已经开始,如果还没开始,就创建一个FutureTask并注册到Map中,然后启动计算,如果已经开始计算,那么就等待计算的结果。结果可能很快得到,也可能还在运算过程中。但是对于Future.get()方法来说是透明的。
注意:我们在代码中用到了ConcurrentHashMap的putIfAbsent(arg, ft)方法,为啥不能直接用put方法呢?因为如果使用put方法,那么仍然会出现两个线程计算出相同的值的问题。我们可以看到compute方法中的if代码块是非原子的,如下所示:
// compute方法中的if部分代码
if (f == null) {
Callable<V> eval = new Callable<V>() {
@Override
public V call() throws Exception {
return computable.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<>(eval);
f = cache.putIfAbsent(arg, ft);
if (f == null) {
f = ft;
ft.run();
}
}因此两个线程仍有可能在同一时间调用compute方法来计算相同的值,只是概率比较低。即两个线程都没有在缓存中找到期望的值,因此都开始计算。而引起这个问题的原因复合操作(若没有则添加)是在底层的Map对象上执行的,而这个对象无法通过加锁来确保原子性,所以需要使用ConcurrentHashMap中的原子方法putIfAbsent,避免这个问题
1.4 测试代码
本来想弄一个动态图展示使用缓存和不使用缓存的速度对比的,但是弄出来的图太大,传不上来,所以给测试代码读者自己验证下:
public static void main(String[] args) throws InterruptedException {
Computable<Integer, List<String>> cache = arg -> {
List<String> res = new ArrayList<>();
for (int i = 0; i < arg; i++) {
Thread.sleep(50);
res.add("zhongjx==>" + i);
}
return res;
};
PerfectMemoizer<Integer, List<String>> memoizer = new PerfectMemoizer<>(cache);
new Thread(new Runnable() {
@Override
public void run() {
List<String> compute = null;
try {
compute = memoizer.compute(100);
System.out.println("zxj 第一次计算100的结果========: "
+ Arrays.toString(compute.toArray()));
compute = memoizer.compute(100);
System.out.println("zxj 第二次计算100的结果: " + Arrays.toString(compute.toArray()));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
System.out.println("zxj====>start===>");
}测试代码中我们使用Thread.sleep()方法模拟耗时操作。我们要测试不使用缓存的情况就是把 f = cache.putIfAbsent(arg, ft);这句代码注释调就行了:如下图所示
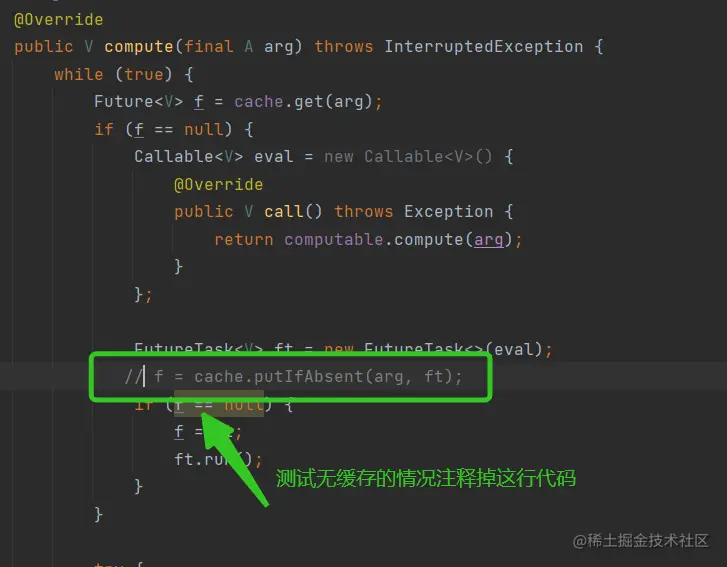
结论:使用缓存时,计算结果会很快得到,不使用缓存时,每次计算都会耗时。
2.并发技巧总结
至 此:一个可伸缩性的高效缓存就设计完了,至此我们可以总结下并发编程的技巧,如下所示:
1.尽量将域声明为final类型,除非它们是可变的,即设计域的时候要考虑是可变还是不可变的
2.不可变的对象一定是线程安全的,可以任意共享而无需使用加锁或者保护性复制等机制。
3.使用锁保护每个可变变量
4.当保护同一个不变性条件中的所有变量时,要使用同一个锁
5.在执行复合操作期间,要持有锁
6.在设计过程中要考虑线程安全。
到此这篇关于基于Java实现一个高效可伸缩的计算结果缓存的文章就介绍到这了,更多相关Java计算结果缓存内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 在Java中,原子操作尤为重要,尤其是在多线程环境中,想象一下,如果小黑在操作一个共享变量时,这个操作被其他线程打断,那会发生什么?可能会导致数据不一致,或者更糟糕的情况,本文将给大家详细介绍一下Java中的原子操作2024-01-01
在Java中,原子操作尤为重要,尤其是在多线程环境中,想象一下,如果小黑在操作一个共享变量时,这个操作被其他线程打断,那会发生什么?可能会导致数据不一致,或者更糟糕的情况,本文将给大家详细介绍一下Java中的原子操作2024-01-01 这篇文章主要为大家详细介绍了Springboot实现发送邮件功能,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-10-10
这篇文章主要为大家详细介绍了Springboot实现发送邮件功能,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-10-10 Java线程池是一种并发编程工具,它允许开发者以线程池的形式重用线程,从而避免频繁创建和销毁线程所带来的开销,这篇文章主要给大家介绍了关于Java线程池内部任务出异常后发现异常的3种方法,需要的朋友可以参考下2025-07-07
Java线程池是一种并发编程工具,它允许开发者以线程池的形式重用线程,从而避免频繁创建和销毁线程所带来的开销,这篇文章主要给大家介绍了关于Java线程池内部任务出异常后发现异常的3种方法,需要的朋友可以参考下2025-07-07 本文介绍了三种通过Value值获取Map中的Key值的方法:循环法、Stream方法和ApacheCommonsCollections的BidiMap,每种方法都有其特点和适用场景,选择哪种方法应根据具体需求来决定2026-01-01
本文介绍了三种通过Value值获取Map中的Key值的方法:循环法、Stream方法和ApacheCommonsCollections的BidiMap,每种方法都有其特点和适用场景,选择哪种方法应根据具体需求来决定2026-01-01 这篇文章主要为大家详细介绍了如何从源码中了解FutureTask实现最大等待时间的方法,文中的示例代码讲解详细,感兴趣的可以了解一下2023-03-03
这篇文章主要为大家详细介绍了如何从源码中了解FutureTask实现最大等待时间的方法,文中的示例代码讲解详细,感兴趣的可以了解一下2023-03-03 今天给大家带来的是小项目是 基于Java+Swing+IO流实现 的贪吃蛇大作战小游戏。实现了界面可视化、基本的吃食物功能、死亡功能、移动功能、积分功能,并额外实现了主动加速和鼓励机制,需要的可以参考一下2022-07-07
今天给大家带来的是小项目是 基于Java+Swing+IO流实现 的贪吃蛇大作战小游戏。实现了界面可视化、基本的吃食物功能、死亡功能、移动功能、积分功能,并额外实现了主动加速和鼓励机制,需要的可以参考一下2022-07-07 下面小编就为大家带来一篇java获取中文拼音首字母的实例。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-09-09
下面小编就为大家带来一篇java获取中文拼音首字母的实例。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-09-09 这篇文章主要介绍了Java Integer对象的比较方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-09-09
这篇文章主要介绍了Java Integer对象的比较方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-09-09
SpringBoot3集成SLF4J+logback进行日志记录的实现
本文主要介绍了SpringBoot3集成SLF4J+logback进行日志记录的实现,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-01-01 这篇文章主要介绍了Java使用dom4j实现对xml简单的增删改查操作,结合实例形式详细分析了Java使用dom4j实现对xml简单的增删改查基本操作技巧与相关注意事项,需要的朋友可以参考下2020-05-05
这篇文章主要介绍了Java使用dom4j实现对xml简单的增删改查操作,结合实例形式详细分析了Java使用dom4j实现对xml简单的增删改查基本操作技巧与相关注意事项,需要的朋友可以参考下2020-05-05










最新评论