
Java根据URL下载文件到本地的2种方式(大型文件与小型文件)
各位小伙伴是否有使用java,根据url下载文件到本地的需求,以下介绍两种方式
1.小型文件推荐使用
代码解析
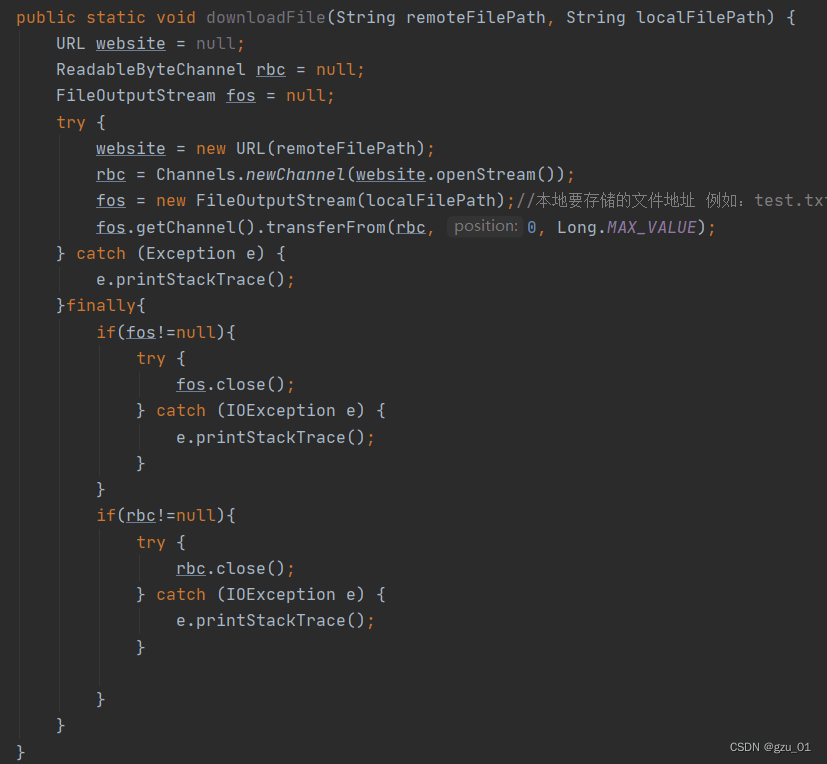
首先创建了一个URL对象website,用来表示远程文件的地址。
然后创建了一个ReadableByteChannel对象rbc和一个FileOutputStream对象fos。ReadableByteChannel用于读取远程文件的字节流,FileOutputStream用于将读取的内容写入本地文件。
在try块中,通过URL对象打开一个连接并获取其字节流,然后使用transferFrom方法将远程文件的内容直接传输到本地文件。这是NIO的一种高效的文件传输方式。
如果在上述过程中发生异常,将会捕获并打印异常信息。
无论是否发生异常,最后都会执行finally块中的清理工作,关闭文件输出流和远程字节流通道,以释放资源。
public static void downloadFile(String remoteFilePath, String localFilePath) {
URL website = null;
ReadableByteChannel rbc = null;
FileOutputStream fos = null;
try {
website = new URL(remoteFilePath);
rbc = Channels.newChannel(website.openStream());
fos = new FileOutputStream(localFilePath);//本地要存储的文件地址 例如:test.txt
fos.getChannel().transferFrom(rbc, 0, Long.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
}finally{
if(fos!=null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(rbc!=null){
try {
rbc.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2.大型文件推荐使用
代码解析:
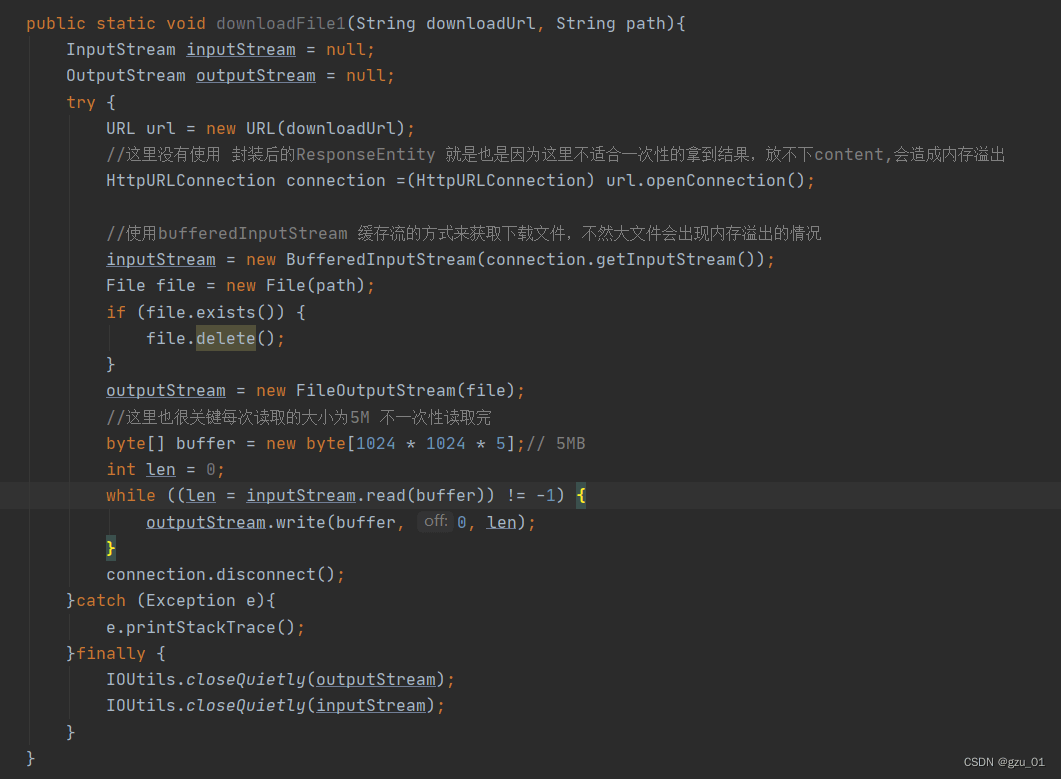
首先创建了一个URL对象url,用来表示要下载文件的地址。
使用URL对象打开一个连接,并将其强制转换为HttpURLConnection对象。HttpURLConnection是Java提供的用于发送HTTP请求和接收HTTP响应的类。
通过连接获取输入流 inputStream,使用BufferedInputStream对输入流进行缓存。这是为了避免一次性读取大文件造成内存溢出。
创建一个File对象 file,表示要保存的本地文件。如果该文件已存在,则删除之。
创建一个输出流 outputStream,将文件作为输出目标。
创建一个字节数组 buffer,大小为5MB(1024 * 1024 * 5),用于缓存每次从输入流中读取的数据。
使用 while 循环,不断从输入流中读取数据到缓冲区,然后将缓冲区的内容写入输出流。循环会一直进行,直到输入流的末尾。
关闭连接 connection,并在 finally 块中关闭输入流和输出流。使用 IOUtils.closeQuietly 方法可以安全地关闭流,即使发生异常也不会抛出异常。
总的来说,这段代码实现了从指定URL下载文件到本地的功能,并且通过缓存流和分块读取的方式,避免了一次性读取大文件导致的内存溢出问题。同时,在下载完成或出现异常后,也进行了资源的关闭和释放操作。
public static void downloadFile1(String downloadUrl, String path){
InputStream inputStream = null;
OutputStream outputStream = null;
try {
URL url = new URL(downloadUrl);
//这里没有使用 封装后的ResponseEntity 就是也是因为这里不适合一次性的拿到结果,放不下content,会造成内存溢出
HttpURLConnection connection =(HttpURLConnection) url.openConnection();
//使用bufferedInputStream 缓存流的方式来获取下载文件,不然大文件会出现内存溢出的情况
inputStream = new BufferedInputStream(connection.getInputStream());
File file = new File(path);
if (file.exists()) {
file.delete();
}
outputStream = new FileOutputStream(file);
//这里也很关键每次读取的大小为5M 不一次性读取完
byte[] buffer = new byte[1024 * 1024 * 5];// 5MB
int len = 0;
while ((len = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, len);
}
connection.disconnect();
}catch (Exception e){
e.printStackTrace();
}finally {
IOUtils.closeQuietly(outputStream);
IOUtils.closeQuietly(inputStream);
}
}
总结
到此这篇关于Java根据URL下载文件到本地的2种方式的文章就介绍到这了,更多相关Java根据URL下载文件到本地内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 Lombok是一个java库,可自动插入您的编辑器和构建工具,为您的java增添趣味,这篇文章主要介绍了VSCode配置java中lombok的相关资料,文中通过代码介绍的非常详细,需要的朋友可以参考下2026-03-03
Lombok是一个java库,可自动插入您的编辑器和构建工具,为您的java增添趣味,这篇文章主要介绍了VSCode配置java中lombok的相关资料,文中通过代码介绍的非常详细,需要的朋友可以参考下2026-03-03
SpringBoot如何使用MyBatisPlus逆向工程自动生成代码
本文介绍如何使用SpringBoot、MyBatis-Plus进行逆向工程自动生成代码,并结合Swagger3.0实现API文档的自动生成和访问,通过详细步骤和配置,确保Swagger与SpringBoot版本兼容,并通过配置文件和测试类实现代码生成和Swagger文档的访问2024-12-12 下面小编就为大家带来一篇深入理解java工厂模式。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2021-07-07
下面小编就为大家带来一篇深入理解java工厂模式。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2021-07-07
Spring MVC 更灵活的控制 json 返回问题(自定义过滤字段)
本篇文章主要介绍了Spring MVC 更灵活的控制 json 返回问题(自定义过滤字段),具有一定的参考价值,感兴趣的小伙伴们可以参考一下。2017-02-02 大家好,本篇文章主要讲的是SpringBoot配置图片访问的虚拟路径,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下2022-02-02
大家好,本篇文章主要讲的是SpringBoot配置图片访问的虚拟路径,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下2022-02-02 这篇文章主要介绍了Java中三种简单注解介绍和代码实例,本文讲解了Override注解、Deprecated注解、Suppresswarnings注解、元注解等内容,需要的朋友可以参考下2014-09-09
这篇文章主要介绍了Java中三种简单注解介绍和代码实例,本文讲解了Override注解、Deprecated注解、Suppresswarnings注解、元注解等内容,需要的朋友可以参考下2014-09-09
对Mybatis Plus中@TableField的使用正解
这篇文章主要介绍了对Mybatis Plus中@TableField的使用正解,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-01-01 本篇文章主要介绍了JAVA 文件监控 WatchService的示例方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10
本篇文章主要介绍了JAVA 文件监控 WatchService的示例方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10 这篇文章主要介绍了使用IDEA启动项目build时出现OOM相关异常的解决,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-06-06
这篇文章主要介绍了使用IDEA启动项目build时出现OOM相关异常的解决,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-06-06 这篇文章主要介绍了spring-security关于hasRole的坑及解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09
这篇文章主要介绍了spring-security关于hasRole的坑及解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09










最新评论