
SpringBoot操作spark处理hdfs文件的操作方法
更新时间:2025年01月09日 11:56:45 作者:念言-ny
本文介绍了如何使用Spring Boot操作Spark处理HDFS文件,包括导入依赖、配置Spark信息、编写Controller和Service处理地铁数据、运行项目以及观察Spark和HDFS的状态,感兴趣的朋友跟随小编一起看看吧
SpringBoot操作spark处理hdfs文件
1、导入依赖
<!-- spark依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.2.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>3.2.2</version>
</dependency>2、配置spark信息
建立一个配置文件,配置spark信息
import org.apache.spark.SparkConf;
import org.apache.spark.sql.SparkSession;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
//将文件交于spring管理
@Configuration
public class SparkConfig {
//使用yml中的配置
@Value("${spark.master}")
private String sparkMaster;
@Value("${spark.appName}")
private String sparkAppName;
@Value("${hdfs.user}")
private String hdfsUser;
@Value("${hdfs.path}")
private String hdfsPath;
@Bean
public SparkConf sparkConf() {
SparkConf conf = new SparkConf();
conf.setMaster(sparkMaster);
conf.setAppName(sparkAppName);
// 添加HDFS配置
conf.set("fs.defaultFS", hdfsPath);
conf.set("spark.hadoop.hdfs.user",hdfsUser);
return conf;
}
@Bean
public SparkSession sparkSession() {
return SparkSession.builder()
.config(sparkConf())
.getOrCreate();
}
}3、controller和service
controller类
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import xyz.zzj.traffic_main_code.service.SparkService;
@RestController
@RequestMapping("/spark")
public class SparkController {
@Autowired
private SparkService sparkService;
@GetMapping("/run")
public String runSparkJob() {
//读取Hadoop HDFS文件
String filePath = "hdfs://192.168.44.128:9000/subwayData.csv";
sparkService.executeHadoopSparkJob(filePath);
return "Spark job executed successfully!";
}
}处理地铁数据的service
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import xyz.zzj.traffic_main_code.service.SparkReadHdfs;
import java.io.IOException;
import java.net.URI;
import static org.apache.spark.sql.functions.*;
@Service
public class SparkReadHdfsImpl implements SparkReadHdfs {
private final SparkSession spark;
@Value("${hdfs.user}")
private String hdfsUser;
@Value("${hdfs.path}")
private String hdfsPath;
@Autowired
public SparkReadHdfsImpl(SparkSession spark) {
this.spark = spark;
}
/**
* 读取HDFS上的CSV文件并上传到HDFS
* @param filePath
*/
@Override
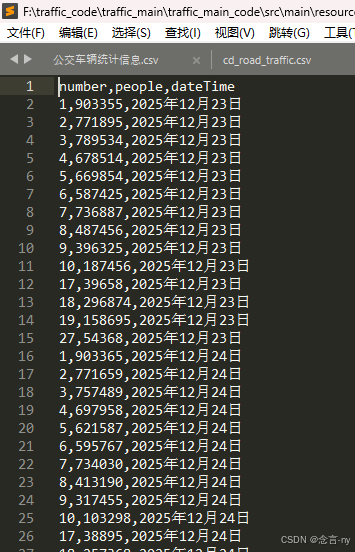
public void sparkSubway(String filePath) {
try {
// 设置Hadoop配置
JavaSparkContext jsc = JavaSparkContext.fromSparkContext(spark.sparkContext());
Configuration hadoopConf = jsc.hadoopConfiguration();
hadoopConf.set("fs.defaultFS", hdfsPath);
hadoopConf.set("hadoop.user.name", hdfsUser);
// 读取HDFS上的文件
Dataset<Row> df = spark.read()
.option("header", "true") // 指定第一行是列名
.option("inferSchema", "true") // 自动推断列的数据类型
.csv(filePath);
// 显示DataFrame的所有数据
// df.show(Integer.MAX_VALUE, false);
// 对DataFrame进行清洗和转换操作
// 检查缺失值
df.select("number", "people", "dateTime").na().drop().show();
// 对数据进行类型转换
Dataset<Row> df2 = df.select(
col("number").cast(DataTypes.IntegerType),
col("people").cast(DataTypes.IntegerType),
to_date(col("dateTime"), "yyyy年MM月dd日").alias("dateTime")
);
// 去重
Dataset<Row> df3 = df2.dropDuplicates();
// 数据过滤,确保people列没有负数
Dataset<Row> df4 = df3.filter(col("people").geq(0));
// df4.show();
// 数据聚合,按dateTime分组,统计每天的总客流量
Dataset<Row> df6 = df4.groupBy("dateTime").agg(sum("people").alias("total_people"));
// df6.show();
sparkForSubway(df6,"/time_subwayData.csv");
//数据聚合,获取每天人数最多的地铁number
Dataset<Row> df7 = df4.groupBy("dateTime").agg(max("people").alias("max_people"));
sparkForSubway(df7,"/everyday_max_subwayData.csv");
//数据聚合,计算每天的客流强度:每天总people除以632840
Dataset<Row> df8 = df4.groupBy("dateTime").agg(sum("people").divide(632.84).alias("strength"));
sparkForSubway(df8,"/everyday_strength_subwayData.csv");
} catch (Exception e) {
e.printStackTrace();
}
}
private static void sparkForSubway(Dataset<Row> df6, String hdfsPath) throws IOException {
// 保存处理后的数据到HDFS
df6.coalesce(1)
.write().mode("overwrite")
.option("header", "true")
.csv("hdfs://192.168.44.128:9000/time_subwayData");
// 创建Hadoop配置
Configuration conf = new Configuration();
// 获取FileSystem实例
FileSystem fs = FileSystem.get(URI.create("hdfs://192.168.44.128:9000"), conf);
// 定义临时目录和目标文件路径
Path tempDir = new Path("/time_subwayData");
FileStatus[] files = fs.listStatus(tempDir);
// 检查目标文件是否存在,如果存在则删除
Path targetFile1 = new Path(hdfsPath);
if (fs.exists(targetFile1)) {
fs.delete(targetFile1, true); // true 表示递归删除
}
for (FileStatus file : files) {
if (file.isFile() && file.getPath().getName().startsWith("part-")) {
Path targetFile = new Path(hdfsPath);
fs.rename(file.getPath(), targetFile);
}
}
// 删除临时目录
fs.delete(tempDir, true);
}
}4、运行
- 项目运行完后,打开浏览器
- spark处理地铁数据
- http://localhost:8686/spark/dispose
- 观察spark和hdfs
- http://192.168.44.128:8099/
- http://192.168.44.128:9870/explorer.html#/
到此这篇关于SpringBoot操作spark处理hdfs文件的文章就介绍到这了,更多相关SpringBoot spark处理hdfs文件内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了java中的Arrays这个工具类你真的会用吗,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了java中的Arrays这个工具类你真的会用吗,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-06-06 这篇文章主要介绍了Java线程变量ThreadLocal详细解读,多线程访问同一个变量的时候,很容易出现问题,特别是多线程对一个共享变量进行写入的时候,为了线程的安全在进行数据写入时候会进行数据的同步,需要的朋友可以参考下2024-01-01
这篇文章主要介绍了Java线程变量ThreadLocal详细解读,多线程访问同一个变量的时候,很容易出现问题,特别是多线程对一个共享变量进行写入的时候,为了线程的安全在进行数据写入时候会进行数据的同步,需要的朋友可以参考下2024-01-01 这篇文章主要介绍了Java中如何动态创建接口的实现方法的相关资料,需要的朋友可以参考下2017-09-09
这篇文章主要介绍了Java中如何动态创建接口的实现方法的相关资料,需要的朋友可以参考下2017-09-09 这篇文章主要介绍了Spring实战之使用@Resource配置依赖操作,结合实例形式分析了Spring使用@Resource配置依赖具体步骤、实现及测试案例,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了Spring实战之使用@Resource配置依赖操作,结合实例形式分析了Spring使用@Resource配置依赖具体步骤、实现及测试案例,需要的朋友可以参考下2019-12-12 Spring WebFlux是Spring Framework 5的响应式框架,结合性能优化与最佳实践,构建高效、可扩展的Web应用,本节将深入探讨 WebFlux 的核心功能,包括 REST API 构建、响应式数据库访问和实时通信,感兴趣的朋友一起看看吧2025-08-08
Spring WebFlux是Spring Framework 5的响应式框架,结合性能优化与最佳实践,构建高效、可扩展的Web应用,本节将深入探讨 WebFlux 的核心功能,包括 REST API 构建、响应式数据库访问和实时通信,感兴趣的朋友一起看看吧2025-08-08 这篇文章主要介绍了浅谈JAVA版本号的问题 Java版本号与JDk版本,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-08-08
这篇文章主要介绍了浅谈JAVA版本号的问题 Java版本号与JDk版本,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-08-08 将彩色图片转换为灰度图片是图像处理中的常见操作,通常用于简化图像、增强对比度、或者进行后续的图像分析,本项目的目标是通过Java实现将彩色图片转换为灰度图片,需要的朋友可以参考下2025-02-02
将彩色图片转换为灰度图片是图像处理中的常见操作,通常用于简化图像、增强对比度、或者进行后续的图像分析,本项目的目标是通过Java实现将彩色图片转换为灰度图片,需要的朋友可以参考下2025-02-02 多态性是对象多种表现形式的体现。在面向对象中,最常见的多态发生在使用父类的引用来引用子类的对象。下面这篇文章主要给大家深入的介绍了Java三大特性中多态的相关资料,有需要的朋友可以参考借鉴,下面来一起看看吧。2017-01-01
多态性是对象多种表现形式的体现。在面向对象中,最常见的多态发生在使用父类的引用来引用子类的对象。下面这篇文章主要给大家深入的介绍了Java三大特性中多态的相关资料,有需要的朋友可以参考借鉴,下面来一起看看吧。2017-01-01 这篇文章主要介绍了mybatis-generator如何自定义注释生成的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-09-09
这篇文章主要介绍了mybatis-generator如何自定义注释生成的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-09-09 这是一个关于Java多线程编程的例子,用多线程的思想模拟停车场管理系统,这里分享给大家,供需要的朋友参考。2017-10-10
这是一个关于Java多线程编程的例子,用多线程的思想模拟停车场管理系统,这里分享给大家,供需要的朋友参考。2017-10-10










最新评论