
Java Spring三级缓存
三级缓存是指什么
我们常说的三级缓存如下:
- CPU三级缓存
- Spring三级缓存
- 应用架构(JVM、分布式缓存、db)三级缓存
CPU
基本概念
CPU 的访问速度每 18 个月就会翻 倍,相当于每年增⻓ 60% 左右,内存的速度当然也会不断增⻓,但是增⻓的速度远小于 CPU,平均每年 只增⻓ 7% 左右。于是,CPU 与内存的访问性能的差距不断拉大。
为了弥补 CPU 与内存两者之间的性能差异,就在 CPU 内部引入了 CPU Cache,也称高速缓存。
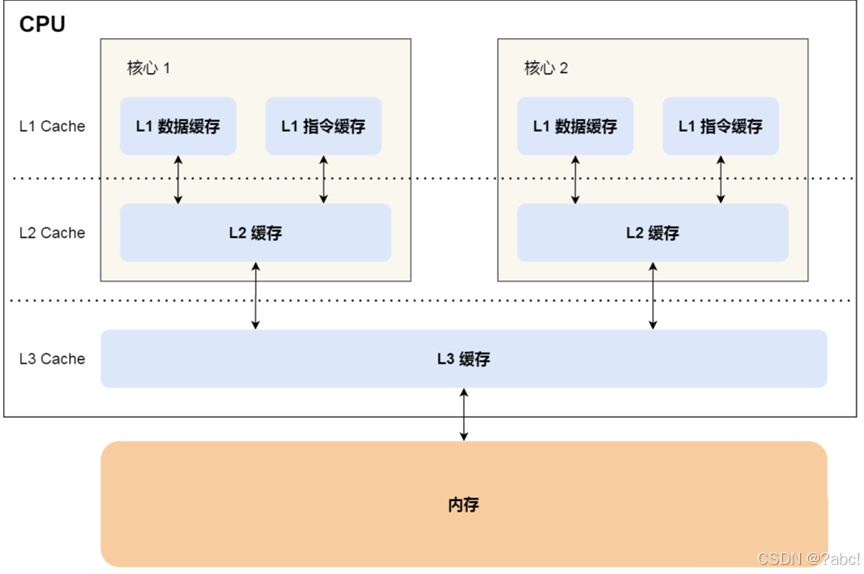
CPU Cache 通常分为大小不等的三级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache。其中L3是多个核心共享的。
离 CPU 核心越近,缓存的读写速度就越快
但 CPU 的空间很狭小,离 CPU 越近缓存大小受到的限制也越大。
所以,综合硬件布局、性能等因素,CPU 缓存通常分为大小不等的三级缓存。
三级缓存要比一、二级缓存大许多倍,这是因为当下的 CPU 都是多核心的,每个核心都有自己的一、二级缓存,- 但
三级缓存却是一颗 CPU 上所有核心共享的 缓存一致性:在多核CPU时代,CPU有“缓存一致性”原则,也就是说每个处理器(核)都会通过嗅探在总线上传播的数据来检查自己的缓存值是不是过期了。如果过期了,则失效。- 比如声明volitate,当变量被修改,则会立即要求写入系统内存。
程序执行数据流向
顺序如下
- 先将内存中的数据加载到共享的 L3 Cache 中,
- 再加载到每个核心独有的 L2 Cache,
- 最后 进入到最快的 L1 Cache,之后才会被 CPU 读取。
- 之间的层级关系,如下图。
Spring三级缓存
概述
三级缓存就是在Bean生成流程中保存Bean对象三种形态的三个Map集合
]
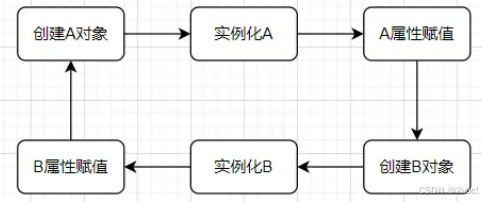
这个三级缓存就是为了解决循环依赖
当创建相互依赖的对象时,会形成死循环,例如下图无缓存中的情况。
- 而Spring通过增加缓存,
将未完全创建好的A提前暴露在缓存中,当相互依赖的对象B对属性A赋值时,可以直接从缓存中获取A,而不需要再创建A。如下所示
哪三个缓存
Spring三级缓存机制包括以下三个缓存:
singletonObjects:一级缓存,缓存中的bean是已经创建完成的,该bean经历过实例化->属性填充->初始化以及各种的后置处理。因此,一旦需要获取bean时,会优先寻找一级缓存-
earlySingletonObjects:二级缓存,该缓存跟一级缓存的区别在于,该缓存所获取到的bean是提前曝光出来的,是还没创建完成的。也就是说获取到的bean只能确保已经进行了实例化,但是属性填充跟初始化还没有做完,因此该bean还没创建完成,时半成品,仅仅能作为指针提前曝光,被其他bean所引用 singletonFactories:三级缓存,在bean实例化完之后,属性填充以及初始化之前,如果允许提前曝光,spring会将实例化后的bean提前曝光,也就是把该bean转换成beanFactory并加入到三级缓存。在需要引用提前曝光对象时再通过singletonFactory.getObject()获取。
// 一级缓存Map 存放完整的Bean(流程跑完的) private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256); // 二级缓存Map 存放不完整的Bean(只实例化完,还没属性赋值、初始化) private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap(16); // 三级缓存Map 存放一个Bean的lambda表达式(也是刚实例化完) private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
发现两个Bean循环依赖时
当Spring发现两个或更多个bean之间存在循环依赖关系时
- 它会先将其中一个beanA创建的过程中尚未完成的实例放入earlySingletonObjects缓存中,
- 然后将创建该beanA的工厂对象放入singletonFactories缓存中。
- 接着,Spring会暂停当前bean的创建过程,去创建它所依赖的bean。
- 当依赖的bean创建完成后,Spring会将其放入singletonObjects缓存中,并使用它来完成当前bean的创建过程。
- 在创建当前bean的过程中,如果发现它还依赖其他的bean,Spring会重复上述过程,直到所有bean的创建过程都完成为止。
- 注意:当使用构造函数注入方式时,循环依赖是无法解决的。
- 因为在创建bean时,必须先创建它所依赖的bean实例,而构造函数注入方式需要在创建bean实例时就将依赖的bean实例传入构造函数中。
- 如果依赖的bean实例尚未创建完成,就无法将其传入构造函数中,从而导致循环依赖无法解决。
- 此时,可以考虑使用setter注入方式来解决循环依赖问题。
当A和B相互依赖时,若先创建实例A,则整个调用过程如下:
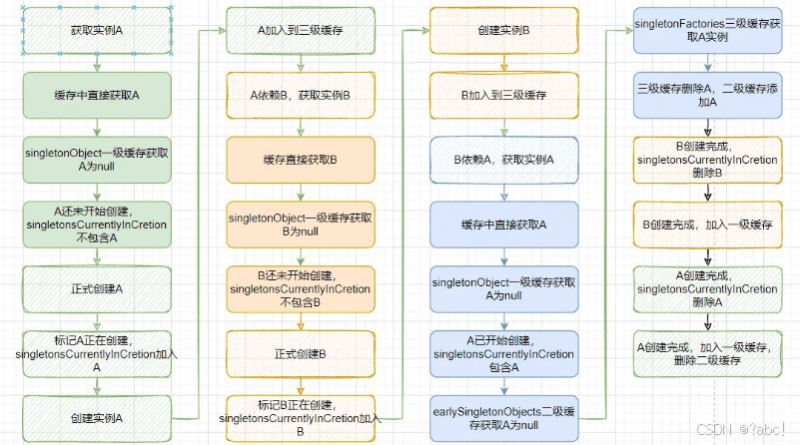
简化图如下
应用架构三级缓存
概述
应用架构三级缓存的时候,一般说JVM级别的、分布式缓存级别的、数据库级别的
JVM级别:一般常见本地缓存框架有Guava Cache和Caffeine Cache分布式缓存级别:一般用的Redis。数据库级别:mysql等数据库
众所周知 MySQL 数据库会将数据存储在硬盘以防止掉电丢失,但是受制于硬盘的物理设计,即便是目前性能最好的企业级 SSD 硬盘,也比内存的这种高速设备 IO 层面差一个数量级
典型的 “读多写少” 的场景,需要在设计上进行数据的读写分离,数据写入时直接落盘处理,
而占比超过 90% 的数据读取操作时则从以 Redis 为代表的内存 NoSQL 数据库提取数据,利用内存的高吞吐瞬间完成数据提取,这里 Redis 的作用就是我们常说的缓存。
二级缓存架构
二级缓存架构
1级为本地缓存,或者进程内的缓存(如 Ehcache) ——速度快,进程内可用-
2级为集中式缓存(如 Redis)——可同时为多节点提供服务
Java 的应用端多级缓存
- 在 Java 的应用端也要设计多级缓存,我们
将进程内缓存与分布式缓存服务结合,有效分摊应用压力。 - 在
Java 应用层面,只有 本地缓存(EhCache、Caffeine Cache) 的缓存不存在时,再去 Redis 分布式缓存获取, - 如果 Redis 也没有此数据再去数据库查询,
数据查询成功后对 Redis 与 本地缓存 同时进行双写更新。 - 这样 Java 应用下一次再查询相同数据时便直接从本地缓存提取,不再产生新的网络通信,应用查询性能得到显著提高。
为了保证缓存一致性,利用 通知(MQ、发布订阅模式等) 向其他服务实例以及 Redis 缓存服务发起变更通知。
到此这篇关于三级缓存的文章就介绍到这了,更多相关三级缓存内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

PostConstruct注解标记类ApplicationContext未加载空指针
这篇文章主要为大家介绍了@PostConstruct注解标记类ApplicationContext未加载空指针示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-11-11
Java 响应式编程之Spring WebFlux+Reactor 实战攻略
本文详细介绍了Java响应式编程的核心概念,重点讲解了SpringWebFlux框架与Reactor响应式库的实战用法,通过大量可运行的示例代码,帮助读者快速上手并理解响应式编程的精髓,本文结合实例代码给大家介绍的非常详细,感兴趣的朋友跟随小编一起看看吧2025-12-12 对于静态变量、静态初始化块、变量、初始化块、构造器,它们的初始化顺序依次是(静态变量、静态初始化块)>(变量、初始化块)>构造器2013-08-08
对于静态变量、静态初始化块、变量、初始化块、构造器,它们的初始化顺序依次是(静态变量、静态初始化块)>(变量、初始化块)>构造器2013-08-08 这篇文章主要介绍了JDBC插入数据返回数据主键代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11
这篇文章主要介绍了JDBC插入数据返回数据主键代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11 在Java开发中JUnit是最常用的单元测试框架之一,编写JUnit测试的目的是确保代码的正确性、可维护性和可扩展性,这篇文章主要介绍了Java中单元测试框架JUnit知识点整理的相关资料,需要的朋友可以参考下2025-08-08
在Java开发中JUnit是最常用的单元测试框架之一,编写JUnit测试的目的是确保代码的正确性、可维护性和可扩展性,这篇文章主要介绍了Java中单元测试框架JUnit知识点整理的相关资料,需要的朋友可以参考下2025-08-08 这篇文章主要介绍了Spring中容器的创建流程详细解读,Spring 框架其本质是作为一个容器,提供给应用程序需要的对象,了解容器的诞生过程,有助于我们理解 Spring 框架,也便于我们“插手”这个过程,需要的朋友可以参考下2023-10-10
这篇文章主要介绍了Spring中容器的创建流程详细解读,Spring 框架其本质是作为一个容器,提供给应用程序需要的对象,了解容器的诞生过程,有助于我们理解 Spring 框架,也便于我们“插手”这个过程,需要的朋友可以参考下2023-10-10 本文给大家分享编写一个简单的mybatis进行插入数据的实例代码,非常不错具有参考借鉴价值,感兴趣的朋友一起看看吧2016-10-10
本文给大家分享编写一个简单的mybatis进行插入数据的实例代码,非常不错具有参考借鉴价值,感兴趣的朋友一起看看吧2016-10-10
Java Swing实现自定义弹窗组件CusDialog(附源码)
Swing 原生对话框 JDialog 和 JFrame 一样,标题栏是系统自带的,样式陈旧且无法自定义,下面我们就来看看如何通过Java Swing实现自定义弹窗组件CusDialog吧2026-05-05 这篇文章主要为大家详细介绍了Java中的过滤器Filter和监听器Listener的使用以及二者的区别,文中的示例代码讲解详细,需要的可以参考一下2022-10-10
这篇文章主要为大家详细介绍了Java中的过滤器Filter和监听器Listener的使用以及二者的区别,文中的示例代码讲解详细,需要的可以参考一下2022-10-10 这篇文章主要介绍了SpringBoot中属性赋值操作的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-10-10
这篇文章主要介绍了SpringBoot中属性赋值操作的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-10-10










最新评论