
C#正则表达式用法入门大全
正则表达式
(这部分内容难以理解,想要讲透还是比较困难,请跟随贴主一步一步探寻)
首先我们要知道正则表达式能够做什么?
- 查找:在文本中找到特定模式的内容
- 替换:将符合某种模式的文本替换为其他内容
- 验证:检查输入的数据是否符合预期格式
- 提取:从复杂文本中提取需要的信息
总的来说就是用于模式匹配和搜索文本的一个工具,也可以把它想作是一个 超级通配符
对于通配符举一个简单的例子,也常常发生在我们查找文件的过程
//像查找 data(\w)?\.dat 这种,你可能会查到以下形式的文件 data.dat data1.dat data2.dat datax.dat dataN.dat //而像查找 data.*\.dat 这种,你可能会查到以下形式的文件 data.dat data1.dat data2.dat data12.dat datax.dat dataXYZ.dat // ? 通配符匹配文件名中的 0 个或 1 个字符,而 * 通配符匹配零个或多个字符
从上述的搜索结果很容易看出,通配符确实具有它的强大,但是也存在相应限制。假如类似文件名很多,也是日常中常会碰到的这种情况下,定位到指定文件夹就显得较为困难。
这也就是为什么我们会在引入“超级通配符”,即正则表达式。
想要学习正则表达式,我们要从一个简单的正则表达式开始认识。
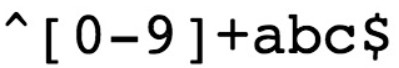
- ^ 为匹配输入字符串的开始位置
- [0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个
- abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置
以上这个简单的正则表达式其实在生活中常常会遇到,只是大家都没有过多去关心这背后的实现原理。以贴主自己为例,打游戏无法取到心仪的名字也正是它在“捣鬼”,hhh
言归正传
由上面的简单正则表达式进一步进阶为下面的表达式
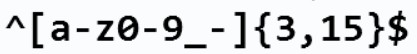
- ^表示匹配字符串的开头
[a-zA-Z0-9_-]表示字符集,包含小写字母、大写字母、数字、下划线_和连接字符-{3,15}表示前面的字符集最少出现 3 次,最多出现 15 次,从而限制了用户名的长度在 3 到 15 个字符之间$表示匹配字符串的结尾
以上的正则表达式匹配 runoob、runoob1、run-oob、run_oob等,但不匹配 ru、 runoob$等
当然正则表达式的日常使用远不止上面的这些,它也有它自己的元字符和特性
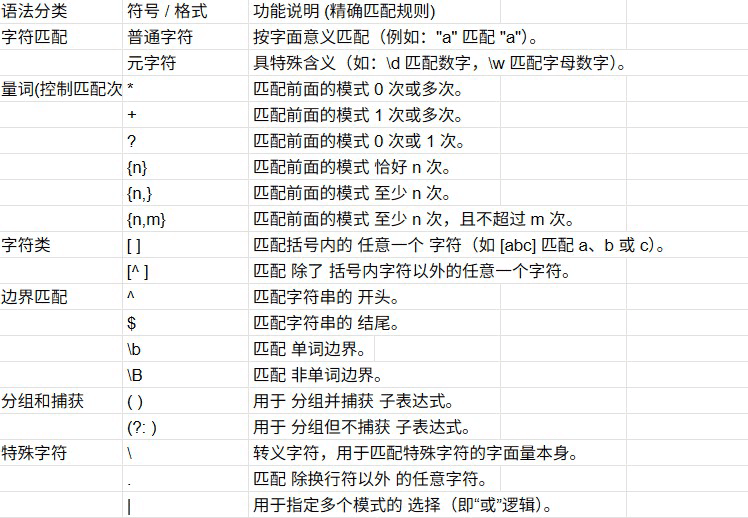
看到这个表格,相信很多小伙伴就会比较焦虑,这么多都需要记住吗?确切的来说是,但又不是。因为这个东西本就是孰能生巧的一个过程,当你用多了,它自然就会在你脑子里留下印象,你自然也就记住了。就好比贴主之前不会做饭,食材和调料放什么怎么放都不知道,但后来迫于生活的压力不得不自己做,于是慢慢就会了,也就记住了。这是一个道理,hhh
有了前面的基础,相信你对正则表达式已经有了一个比较确切的认识,由于目前以C#语言为主,故后面的内容围绕C#展开,不同语言可能用法有所不同,但是底层的逻辑基本都是一致的。下面的内容会略微枯燥,但是贴主已经尽力挑最精华的部分讲,请耐心看完。
1、字符类
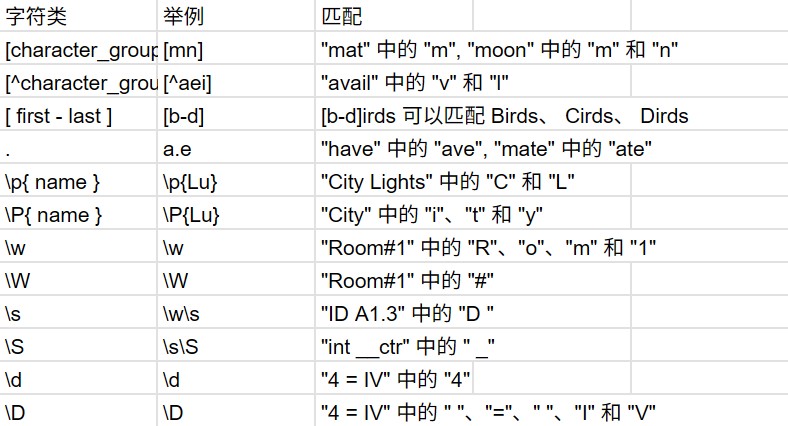
上述不好理解的应该主要是\p{name}和\P{name},一个是与 name 指定的 Unicode 通用类别或命名块中的任何单个字符匹配,而另一个则相反,与不在 name 指定的 Unicode 通用类别或命名块中的任何单个字符匹配。在 Unicode 标准中,Lu 代表 "Letter, uppercase"(大写字母)。也就有了上面的结果。具体遇到了之后可以通过查阅资料得知。
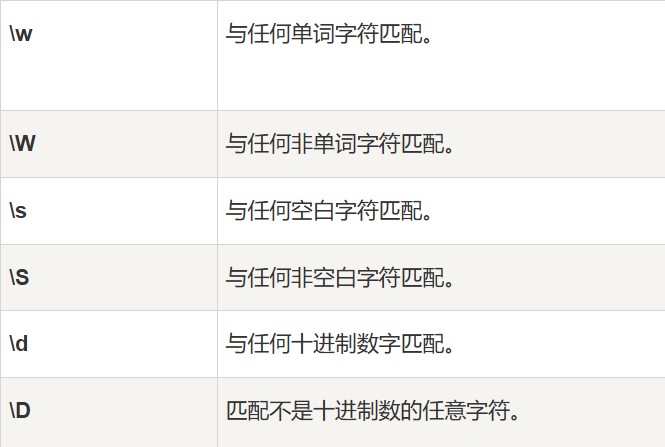
2、字符转义

下面所列举的是历史遗留的控制字符 (在日常中较少用,可要到后再前往学习即可)
\a(报警/响铃):早期终端遇到这个字符会发出“滴”的响声\v(垂直制表符) 和\f(换页符):早期用于控制打印机纸张的滚动\e(转义符 Escape):匹配 ASCII 里的 ESC 键控制码\c X(ASCII 控制字符):用于匹配按键组合。例如\cC匹配Ctrl + C产生的控制字符\b(退格符 Backspace):注意这里有一个非常关键的细节! 在正则表达式中,\b通常代表“单词边界”(比如匹配整个单词)。只有当它被放在方括号内,写成[\b]时,它才代表键盘上的“退格键”(Backspace)。图片中的描述特意强调了“在字符类中”,就是指放在[]里面。
当您的键盘打不出某个字符,或者您想极其精确地指定某个字符时,可以使用它的计算机底层编码来匹配。这三种方式本质上是一样的,只是进制不同:
\x nn(十六进制):用两位十六进制数表示字符。例如\x20代表空格(ASCII码 32 的十六进制是 20)\u nnnn(Unicode):用四位十六进制数表示全球统一的 Unicode 字符。例如\u0020同样代表普通空格。它也可以用来匹配中文等复杂字符(如\u4e00代表汉字“一”)\nnn(八进制):用两到三位八进制数表示。例如\040代表空格(32的八进制是40)。这种写法现在相对少见了
这些是我们日常处理文本时最常遇到的不可见字符:
\n(换行符, Newline):代表我们在键盘上按下 Enter 键换行。匹配下一行开始的位置\r(回车符, Carriage Return):在 Windows 系统中,换行通常是\r\n连用的;而在 Linux/macOS 中通常只有\n。图中的例子\r\n就是用来匹配 Windows 风格的换行\r(回车符, Carriage Return):在 Windows 系统中,换行通常是\r\n连用的;而在 Linux/macOS 中通常只有\n。图中的例子\r\n就是用来匹配 Windows 风格的换行
万能的“取消魔法”符:
\(反斜杠本身):这是极其重要的一点。如果想在文本中寻找真正的加号+或者星号*,不能直接写+,因为正则会以为您要“匹配前一个字符一次或多次”。必须写成\+或\*。图中例子解析:在举例\d+[\+-x\*]\d+中,\+和\*就是告诉正则:“我不是要用你们的魔法规则,我就是要找文本里长得像加号和星号的符号”。所以它能成功匹配出数学算式"2+2"和"3*9"。
3、定位点

基础行边界 (最常用):
- ^(脱字符):匹配字符串或一行的绝对开头
$(美元符):匹配字符串或一行的绝对结尾
绝对字符串边界 (应对多行文本):
\A:只匹配整个字符串的绝对开头。无论换不换行,它只认整个文本的第一个位置\Z:匹配整个字符串的结尾,或者如果文本最后有一个换行符\n,它会匹配在换行符之前\z:比\Z更严格,匹配字符串的终极末尾,哪怕最后有换行符,它也匹配在换行符的后面
单词边界 (处理英文单词极佳):
\b(Word Boundary):匹配单词边界。图中举例:er\b。这意味着"er"的后面必须跟着一个边界(比如空格或句号)。所以在单词"never"中,最后的"er"符合要求;但在单词"verb"中,"er"后面跟着"b"(是个字母,不是边界),所以无法匹配\B(Non-word Boundary):匹配非单词边界(即单词的内部)
连续匹配边界 (进阶用法):
\G:匹配必须从上一次匹配结束的那个位置接着开始。这通常用于要求一连串特定格式的连续出现,中间不能断开
4、分组构造

捕获与非捕获分组 (基础核心):
( )普通捕获组:不仅将多个字符组合成一个整体(以便在后面加*或?等量词),还会记住(捕获)匹配到的内容。举例解析:(\w)\1。\w匹配任意字母,加上括号后它就成了一号捕获组。后面的\1叫做反向引用,意思是“这里必须出现和第一组一模一样的内容”。所以它能匹配连续相同的两个字母,如"ee"。(?<name>)命名捕获组:功能同上,但给这个组起了一个名字,方便以后在代码里直接用名字提取数据,而不是数数字。举例解析:(?<double>\w)\k<double>。给捕获组起名叫double,后面的\k<double>就是通过名字来引用它。(?: )非捕获组:只起到“把几个字符打包”的作用,不记住匹配的内容,也不占用组号。这可以节省系统资源,提高匹配效率。举例解析:Write(?:Line)?。匹配 "Write" 或者 "WriteLine"。"Line" 被打包,后面的?表示 "Line" 出现 0 次或 1 次,但不会捕获 "Line" 这个词。
环视 / 零宽断言 (高级条件检查):
(?= )正预测先行(Lookahead):要求当前位置的后面必须出现指定内容。举例解析:\w+(?=\.)。匹配一个单词\w+,但条件是这个单词后面必须紧跟一个英文句号\.。注意,匹配结果中不包含这个句号(只提取"is",不提取"is.")。(?! )负预测先行(Negative Lookahead):要求当前位置的后面不能出现指定内容。举例解析:\b(?!un)\w+\b。匹配一个完整的单词,但条件是这个单词不能以 "un" 开头。(?<= )正回顾后发(Lookbehind):要求当前位置的前面必须出现指定内容。举例解析:(?<=19)\d{2}\b。匹配两位数字\d{2},但条件是这俩数字前面必须是 "19"。它巧妙地从四位数年份中只提取出 19XX 年的后两位。(?<! )负回顾后发(Negative Lookbehind):要求当前位置的前面不能出现指定内容。举例解析:(?<!wo)man\b。匹配单词 "man",但条件是它前面不能有 "wo",这样就排除了 "woman"。
选项修改与原子组 (性能与修饰):
(?i: )局部修饰符:允许您只在特定部分开启某种模式(如大小写不敏感i)。举例解析:A\d{2}(?i:\w+)\b。开头的A必须大写,但(?i:\w+)这部分内的字母可以不区分大小写。(?> )原子组(固化分组):一旦匹配成功,就锁定结果,禁止引擎“回溯”(反悔重新尝试)。主要用于处理极其复杂的正则以防止引擎陷入死循环(即灾难性回溯),通常在做极致的性能优化时使用。
平衡组 (特殊引擎专属):
(?<name1-name2>)平衡组:这是 .NET 等少数高级正则引擎特有的功能,通常用于匹配成对出现的括号或标签(如 HTML 标签匹配)。逻辑非常复杂,相当于正则内部维持了一个栈来记录左括号和右括号的数量。通常在日常简单的文本处理中较少用到。
5、限定符

限定符理解相对容易,再前面的元字符也有类似介绍,在此不过多赘述
6、反向引用构造
反向引用如果细心的伙伴可能再先前讲述其它正则表达的时候就能够注意到
- \ number:前面的举例解析:
(\w)\1。\w匹配任意字母,加上括号后它就成了一号捕获组。后面的\1叫做反向引用,意思是“这里必须出现和第一组一模一样的内容”。所以它能匹配连续相同的两个字母,如"ee"。 - \k< name >:前面的举例解析:
(?<double>\w)\k<double>。给捕获组起名叫double,后面的\k<double>就是通过名字来引用它。
7、替换

提取并重组子字符串 (最常用):
$number:按序号引用捕获组。举例解析:模式匹配了三个组(单词、空格、单词)。输入是"one two"。替换模式$3$2$1的意思是:先放第 3 组("two"),再放第 2 组(空格),最后放第 1 组("one")。结果成功将两词互换成了"two one"。${name}:按名字引用捕获组。和上面原理一样,只不过把数序号变成了喊名字,代码可读性更好。
利用上下文信息进行高级替换:
$&(包含自己):代表刚刚匹配到的那一段文本本身。比如您想给匹配到的金额前加星号,就可以用**$&。$`(左侧内容):代表匹配文本左边的所有内容。举例解析:匹配到"BB",左边是"AA"。所以把"BB"替换成了"AA"。最后拼接起来变成了"AA"(原左侧)+"AA"(替换后的BB)+"CC"(原右侧) ="AAAACC"。$'(右侧内容):代表匹配文本右边的所有内容。举例解析:匹配到"BB",右边是"CC"。把"BB"替换成"CC"。拼接后变成"AA"+"CC"+"CC"="AACCCC"。$_(全部内容):代表整个最初输入的字符串。举例解析:把"BB"替换成完整的"AABBCC"。结果就变成了"AA"+"AABBCC"+"CC"="AAAABBCCCCC"。
特殊符号处理:
$$:因为$符号在替换语句里变成了“魔法符号”(用来指代变量),所以当您真的只想在文本里打印一个普通的$金额符号时,必须连写两个$$来“取消魔法”(类似于之前讲的\转义字符)。举例解析:替换模式$$$1中,前两个$$会变成一个真正的普通字符$,后面的$1是引用第一个数字捕获组。因此把"103 USD"完美替换成了"$103"。
以上列举的都是正则表达式中贴主个人认为比较重要且可能会常用到的,但是仍然存在一些关于正则表达式没有讲到的内容。该部分内容就需要大家在遇到后自己借助资料和AI学习,也欢迎在评论区补充。
相信在看完整个文章后,你已经对正则表达式已经有了较为深入的理解。虽然正则表达式理解具有一定的困难,但当你真正理解后它也就还好。虽然内容较多,但是在当今AI时代,AI可以帮你很好的弥补记忆不牢固这一缺陷,并且也能帮你快速捡起以前学过的东西。
总结
到此这篇关于C#正则表达式用法入门大全的文章就介绍到这了,更多相关C#正则表达式内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 桶排序是一种快速且高效的排序算法,通过将数据分配到有序桶中并分别排序,适合均匀分布数据,它的时间复杂度为O(n),但不适合数据分布极不均匀或数据范围很大的情况,桶排序算法简单、易实现,可调整桶的大小和数量以适应不同数据,感兴趣的可以了解一下2024-10-10
桶排序是一种快速且高效的排序算法,通过将数据分配到有序桶中并分别排序,适合均匀分布数据,它的时间复杂度为O(n),但不适合数据分布极不均匀或数据范围很大的情况,桶排序算法简单、易实现,可调整桶的大小和数量以适应不同数据,感兴趣的可以了解一下2024-10-10
C#使用Spire.XLS for .NET将Excel转换为SVG图片
在C#开发中,C# Excel转换为SVG的需求日益增长,尤其Web应用中Excel矢量预览已成为痛点解决关键,本文客观分享实现路径与代码,帮助C#开发者快速集成,提升项目效率,需要的朋友可以参考下2026-03-03 这篇文章主要为大家详细介绍了WPF开发txt阅读器时如何实现目录提取功能,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-06-06
这篇文章主要为大家详细介绍了WPF开发txt阅读器时如何实现目录提取功能,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-06-06![C# string转换为几种不同编码的Byte[]的问题解读](//img.jbzj.com/images/xgimg/bcimg3.png)
C# string转换为几种不同编码的Byte[]的问题解读
这篇文章主要介绍了C# string转换为几种不同编码的Byte[]的问题解读,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 这篇文章主要介绍了C#中DateTimePicker默认值显示为空的问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-06-06
这篇文章主要介绍了C#中DateTimePicker默认值显示为空的问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-06-06 restful接口常用的两种方式是get和post.接下来通过本文给大家介绍Restful接口的两种使用方式,本文给大家介绍的非常详细,需要的朋友参考下吧2018-09-09
restful接口常用的两种方式是get和post.接下来通过本文给大家介绍Restful接口的两种使用方式,本文给大家介绍的非常详细,需要的朋友参考下吧2018-09-09 这篇文章主要为大家详细介绍了如何使用C#从零开始实现一个截屏工具,文中的示例代码讲解详细,具有一定的借鉴价值,感兴趣的小伙伴可以了解下2026-06-06
这篇文章主要为大家详细介绍了如何使用C#从零开始实现一个截屏工具,文中的示例代码讲解详细,具有一定的借鉴价值,感兴趣的小伙伴可以了解下2026-06-06 这篇文章主要为大家详细介绍了Unity3D Shader实现扫描显示效果,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-03-03
这篇文章主要为大家详细介绍了Unity3D Shader实现扫描显示效果,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-03-03 下面小编就为大家分享一C#日期格式强制转换的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2017-11-11
下面小编就为大家分享一C#日期格式强制转换的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2017-11-11 下面小编就为大家带来一篇C# ping网络IP 实现网络状态检测的方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-08-08
下面小编就为大家带来一篇C# ping网络IP 实现网络状态检测的方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-08-08



![C# string转换为几种不同编码的Byte[]的问题解读](http://img.jbzj.com/images/xgimg/bcimg3.png)






最新评论