
Linux之匿名管道和命名管道详解
匿名管道
kubectl get pod -A | grep mysql
上面命令行里的「|」竖线就是一个管道,在命令行(如 Linux Shell 或 Windows CMD/PowerShell)中,管道操作符 | 的作用是将 前一个命令的标准输出(stdout) 传递给 后一个命令的标准输入(stdin)。但它默认 不会传递标准错误(stderr),这是它的核心行为特点。
1. 管道|的基本行为
command1 | command2
command1的stdout→ 作为command2的stdin。command1的stderr→ 直接打印到终端,不会传递给command2。
示例 1(stdout 被管道传递)
# ls 成功时,stdout(文件列表)会传递给 grep ls /usr/bin | grep "python"
示例 2(stderr 未被管道传递)
# 如果目录不存在,错误信息会直接显示,不会传递给 grep ls /nonexistent_dir | grep "error"
输出:
ls: cannot access '/nonexistent_dir': No such file or directory
(错误信息直接显示,grep 不会处理它)
2. 为什么|不处理 stderr
- 设计初衷:
|的职责是传递 正常输出,错误信息通常需要直接反馈给用户。 - 分离数据流:stdout(正常输出)和 stderr(错误信息)是独立的流,
|默认只操作 stdout。
3. 原理
int pipe(int fd[2])
这里表示创建一个匿名管道,并返回了两个描述符,一个是管道的读取端描述符,另一个是管道的写入端描述符fd。注意,这个匿名管道是特殊的文件,只存在于内存,不存于文件系统中。
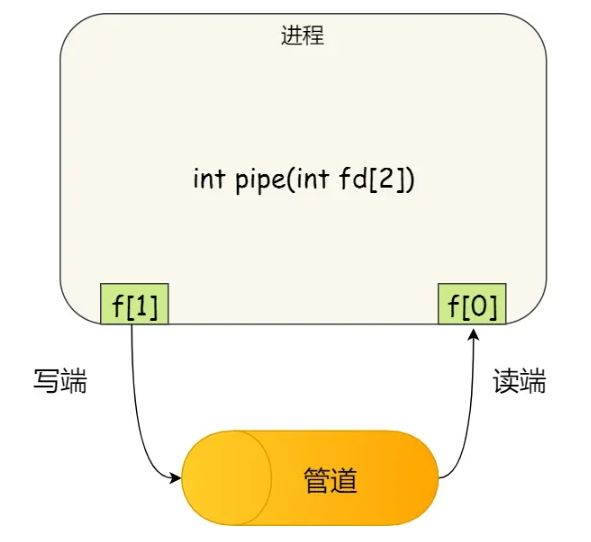
所谓的管道,就是内核里面的一串缓存。从管道的一段写入的数据,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据。另外,管道传输的数据是无格式的流且大小受限。
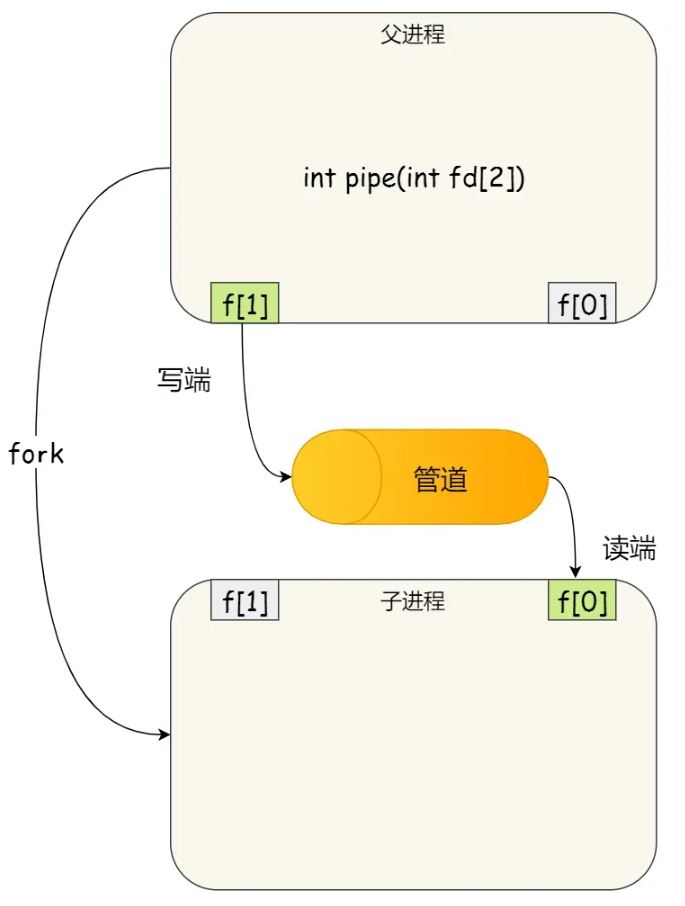
管道只能一端写入,另一端读出,所以上面这种模式容易造成混乱,因为父进程和子进程都可以同时写入,也都可以读出。那么,为了避免这种情况,通常的做法是:
- 父进程关闭读取的 fd[o],只保留写入的 fd[1];
- 子进程关闭写入的fd[1],只保留读取的 fd[o];
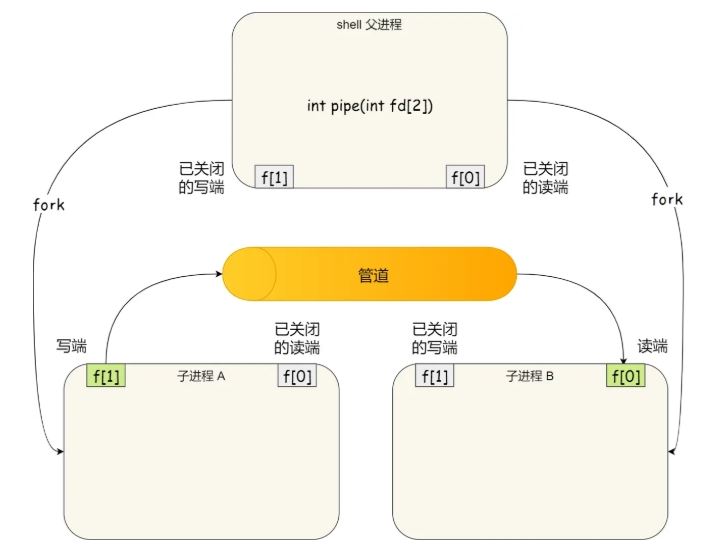
在shell 里面执行 A | B 命令的时候,A 进程和 B 进程都是shell 创建出来的子进程,A 和 B 之间不存在父子关系,它俩的父进程都是 shell。
命名管道
简介
- 匿名管道,它的通信范围是存在父子关系的进程。因为管道没有实体,也就是没有管道文件,只能通过fork来复制父进程 fd文件描述符,来达到通信的目的。
- 对于命名管道,它可以在不相关的进程间也能相互通信。因为命令管道,提前创建了一个类型为管道的设备文件,在进程里只要使用这个设备文件,就可以相互通信。
- 不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持Iseek之类的文件定位操作。
使用
int mkfifo(const char *pathname, mode_t mode);
创建 FIFO
使用 mkfifo 命令或 mkfifo() 函数创建:
mkfifo /tmp/myfifo # 创建一个名为 /tmp/myfifo 的 FIFO
pathname:FIFO 的文件路径(如/tmp/myfifo)。mode:权限(如0644,表示用户可读写,其他人只读)。
FIFO 的特点
半双工通信
- 同一时间只能 读 或 写,不能同时读写(类似单行道)。
- 示例:
# 终端1:写入数据 echo "Hello" > /tmp/myfifo # 终端2:读取数据 cat /tmp/myfifo # 输出 "Hello"
阻塞机制
- 如果没有进程在 读,写操作会 卡住,直到有进程来读。
- 如果没有进程在 写,读操作会 卡住,直到有进程来写。
数据是流式的
- 数据像水流一样,读完后会消失,不能像普通文件那样随意跳转(
lseek无效)。
如何使用 FIFO?
(1)命令行测试
# 终端1:监听 FIFO(读) cat /tmp/myfifo # 终端2:发送数据(写) echo "Hello FIFO" > /tmp/myfifo
终端1 会显示 Hello FIFO。
(2)C 语言示例
#include <fcntl.h>
#include <sys/stat.h>
#include <unistd.h>
int main() {
mkfifo("/tmp/myfifo", 0644); // 创建 FIFO
int fd = open("/tmp/myfifo", O_WRONLY); // 以写方式打开
write(fd, "Hello", 6); // 写入数据
close(fd);
return 0;
}
常见问题
Q1: FIFO 和普通文件有什么区别?
- FIFO 是 内存中的管道,数据读完就没了;普通文件会持久化存储。
Q2: FIFO 和匿名管道(|)有什么区别?
- 匿名管道只能用于 父子进程,FIFO 可用于 任意进程。
Q3: 如果 FIFO 已经存在,再创建会怎样?
mkfifo会失败,并提示File exists。
原理
1. 普通文件 vs. 命名管道(FIFO)
普通文件(如 a.txt):
- 数据存储在 磁盘 上,打开时会加载到内存。
- 修改后需要 写回磁盘(刷盘)。
- 多个进程打开同一文件时,数据可能不同步(除非加锁)。
命名管道(FIFO):
- 本质是一个 内存缓冲区,只是伪装成文件(磁盘上只有文件名,没有实际数据块)。
- 数据 不写入磁盘,直接在进程间流动。
- 专为 进程间通信(IPC) 设计,速度快。
2. 命名管道的工作原理
(1)创建 FIFO
当执行 mkfifo /tmp/myfifo 时:
- 磁盘上创建一个 空文件(只有 inode,没有数据块)。
- 操作系统内核维护一个 内存缓冲区(用于存储进程间传递的数据)。
(2)进程 A 写入数据
echo "Hello" > /tmp/myfifo
- 进程 A 打开 FIFO 以写方式(
O_WRONLY)。 - 数据
"Hello"被写入内核的 内存缓冲区(不刷盘!)。 - 如果 没有进程在读取,进程 A 会 阻塞(卡住),直到有进程来读。
(3)进程 B 读取数据
cat /tmp/myfifo
- 进程 B 打开 FIFO 以读方式(
O_RDONLY)。 - 从内核缓冲区读取
"Hello",数据被消费(缓冲区清空)。 - 如果 没有进程在写入,进程 B 会 阻塞,直到有进程写入。
3. 关键点解析
(1)文件描述符与内核结构
每个进程打开 FIFO 时,内核会 复用同一个 struct file(通过引用计数 ref 管理)。
- 第一次打开时创建
struct file,ref=1。 - 第二个进程打开时,
ref=2(指向同一个内存缓冲区)。 - 关闭时
ref--,ref=0时内核才释放资源。
(2)为什么数据不刷盘?
- FIFO 的 设计目的 是进程间通信,数据不需要持久化。
- 刷盘会 拖慢速度,且毫无意义(通信完数据即可丢弃)。
(3)半双工通信
- 同一时间只能 单向流动(读或写)。
- 如果需要双向通信,需创建 两个 FIFO(一个负责 A→B,一个负责 B→A)。
4. 类比理解
把 FIFO 想象成 一条水管:
写入端:进程 A 往水管里倒水(数据)。
读取端:进程 B 从水管接水(数据)。
特性:
- 水管没有储水功能(数据不持久化)。
- 如果没人接水,倒水的人会等待(阻塞写入)。
- 如果没人倒水,接水的人会等待(阻塞读取)。
总结
| 特性 | 命名管道(FIFO) | 普通文件 |
|---|---|---|
| 存储位置 | 内存缓冲区 | 磁盘 |
| 刷盘 | 永不刷盘 | 定期刷盘 |
| 多进程访问 | 共享同一缓冲区 | 可能数据不同步 |
| 阻塞行为 | 读/写会阻塞 | 无阻塞 |
| 用途 | 进程间通信 | 数据存储 |
简单来说:
FIFO 是 披着文件外衣的内存管道,让进程可以通过文件路径名通信,数据 不落盘,速度极快!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章

ubuntu运行gcfsd-admin守护进程需要认证的解决方案
在Ubuntu中运行`gcfsd-admin`守护进程时,如果每次进入都需要输入密码,可以通过重新挂载`/data`磁盘来解决这个问题,总结来说,需要对磁盘进行重新挂载以消除锁子2026-01-01 这篇文章主要介绍了apache下运行cgi模式的配置方法,需要的朋友可以参考下2014-04-04
这篇文章主要介绍了apache下运行cgi模式的配置方法,需要的朋友可以参考下2014-04-04 在负载均衡技术中,硬件设备是比较昂贵的,对于负载均衡的学习者如果不是在企业中应用或者是学员中学习,很少有机会能碰到实际操作的训练。所以,很多朋友都会选择软件方面的设置进行研究。现在我们就来介绍一下再Apache下的Tomcat负载均衡的一些使用问题2012-10-10
在负载均衡技术中,硬件设备是比较昂贵的,对于负载均衡的学习者如果不是在企业中应用或者是学员中学习,很少有机会能碰到实际操作的训练。所以,很多朋友都会选择软件方面的设置进行研究。现在我们就来介绍一下再Apache下的Tomcat负载均衡的一些使用问题2012-10-10 这篇文章主要介绍了Node.js环境在linux上的部署教程,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-02-02
这篇文章主要介绍了Node.js环境在linux上的部署教程,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-02-02
Linux中出现“No space left on device”错误的排查与解决方法
这篇文章主要给大家介绍了关于在Linux中出现"No space left on device"错误的排查与解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-09-09 这篇文章主要介绍了Linux(Ubuntu) adb 无法识别的问题解决方法的相关资料,需要的朋友可以参考下2016-11-11
这篇文章主要介绍了Linux(Ubuntu) adb 无法识别的问题解决方法的相关资料,需要的朋友可以参考下2016-11-11 文章介绍了如何通过替换class文件来避免重复打包的问题,具体步骤包括查找目标文件目录、解压目标文件、替换已解压文件、替换jar包文件等2025-11-11
文章介绍了如何通过替换class文件来避免重复打包的问题,具体步骤包括查找目标文件目录、解压目标文件、替换已解压文件、替换jar包文件等2025-11-11 这篇文章主要介绍了基于windowx的Hyper-v安装CentOS系统 ,本文图文并茂给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了基于windowx的Hyper-v安装CentOS系统 ,本文图文并茂给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-07-07 这篇文章主要介绍了centos7.0安装离线JDK1.8方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2018-06-06
这篇文章主要介绍了centos7.0安装离线JDK1.8方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2018-06-06 这篇文章主要介绍了linux系列之常用运维命令整理笔录(小结),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-01-01
这篇文章主要介绍了linux系列之常用运维命令整理笔录(小结),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-01-01










最新评论