
Linux系统的线程入门:基本概念、虚拟内存、Linux内核线程、线程应用
大家好,本篇是Linux系统编程系列的线程入门,我会结合底层原理,把线程是什么、为什么需要虚拟内存、Linux 线程本质、优缺点与用途一次性讲透,帮你从内核视角真正理解线程。
一. 什么是线程?一句话抓住本质
线程 = 进程内部的一条执行流 / 控制序列
- 一个进程至少有 1 个线程(主线程)
- 线程在进程虚拟地址空间内运行,共享进程大部分资源
- Linux 内核没有专门的 “线程结构体”,线程本质是轻量级进程 LWP,用
task_struct描述,只是比普通进程更 “轻量化”
一句话区分进程与线程:进程是资源分配的基本单位;线程是 CPU 调度的基本单位



📌 不过:
- 仅仅有上面的理解,是不够的
- 要真正理解线程,就必须搞清楚,内核是如何进行资源划分的,尤其是代码
二. 必须先懂:虚拟地址空间与分页机制
线程之所以能 “共享、轻量化”,完全依赖虚拟地址空间。这部分是理解线程的地基。
2.1 没有虚拟内存会怎样?
早期操作系统没有虚拟内存:
- 程序直接占用连续物理内存
- 程序大小不一,退出后留下大量内存碎片
- 多程序容易地址冲突、越界、崩溃
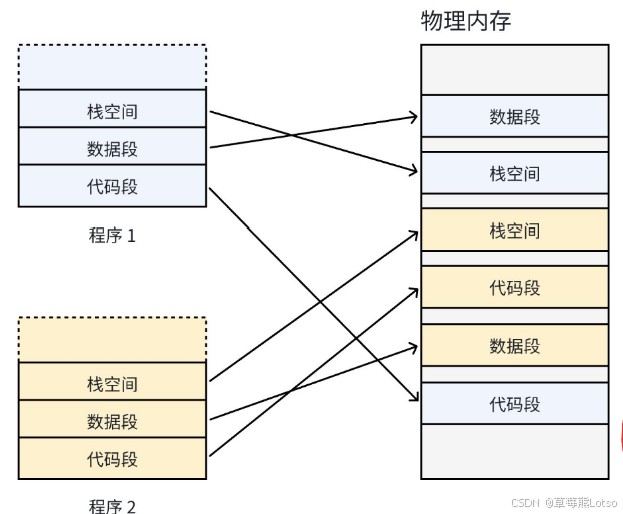

我们希望:
- 用户视角:地址连续、用起来方便
- 内核视角:物理内存离散、无碎片、可管理

于是:虚拟地址空间 + 分页 + 页表 诞生。
2.2 分页基本概念
- 物理内存按固定大小分割:页框(Page Frame)
- 虚拟地址按同样大小分割:页(Page)
- 常见页大小:32 位系统 4KB,64 位系统 8KB
- 作用:把连续的虚拟地址,映射到不连续的物理内存页,解决内存碎片问题。
机制:
- CPU不直接访问物理内存,而是通过虚拟地址空间间接访问。
- 操作系统为每个执行中的进程分配逻辑地址空间。32 位机:范围 0 ~ 4G-1。
- 通过页表建立虚拟地址 ↔ 物理地址的映射。
2.3 物理内存管理(重点看图)
以 4GB 物理内存、4KB 页框为例:总页数 = 4GB / 4KB = 1048576 个页框。
内核用 struct page 表示系统中的每个物理页。为节省内存,struct page 大量使用 union(联合体)。
struct page {
/* 原子标志,有些情况下会异步更新 */
unsigned long flags;
union {
struct {
/* 换出页列表,例如由 zone->lru_lock 保护的 active_list */
struct list_head lru;
/* 如果最低位为 0,则指向 inode 的 address_space,或为 NULL;
* 如果页映射为匿名内存,最低位置位,且该指针指向 anon_vma 对象
*/
struct address_space *mapping;
/* 在映射内的偏移量 */
pgoff_t index;
/*
* 由映射私有,不透明数据
* - 如果设置了 PagePrivate,通常用于 buffer_heads
* - 如果设置了 PageSwapCache,则用于 swp_entry_t
* - 如果设置了 PG_buddy,则用于表示伙伴系统中的阶
*/
unsigned long private;
};
struct { /* slab, slob and slub */
union {
struct list_head slab_list; /* 复用 lru */
struct { /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* 剩余页数 */
int pobjects; /* 近似对象计数 */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* 不用于 slob */
/* 双字边界对齐 */
void *freelist; /* 第一个空闲对象 */
union {
void *s_mem; /* slab: 第一个对象 */
unsigned long counters; /* SLUB: 计数器 */
struct { /* SLUB 专用 */
unsigned inuse : 16; /* 已使用的对象数 */
unsigned objects : 15; /* 总对象数 */
unsigned frozen : 1; /* 是否冻结 */
};
};
};
/* 其他可能的联合成员(如用于文件系统等) */
...
};
union {
/* 内存管理子系统中映射的页表项计数,用于表示页是否已经映射,
* 还用于限制逆向映射搜索 */
atomic_t _mapcount;
unsigned int page_type;
unsigned int active; /* SLAB */
int units; /* SLOB */
};
/* 其余字段(如引用计数、私有用例等) */
...
#if defined(WANT_PAGE_VIRTUAL)
/* 内核虚拟地址(如果没有映射则为 NULL,即高端内存) */
void *virtual;
#endif /* WANT_PAGE_VIRTUAL */
/* 后续可能还有其他成员,取决于内核配置 */
...
};
关键成员:
flags
- 存放页的状态:是否锁定、是否脏页、是否在缓存、是否空闲等。每一位表示一种状态,最多可表示 32 种状态。重要标志:
- PG_locked:页是否被锁定
- PG_uptodate:页数据是否有效
- PG_dirty:页是否被修改(脏页)
_mapcount
- 表示有多少页表项指向该页,即被引用计数。当值为 -1 时,表示该页空闲可分配。
virtual
- 页的内核虚拟地址。高端内存不永久映射,此时 virtual 为 NULL,需要动态映射。
内存开销计算:struct page 约占 40 字节。4GB 内存共 1048576 个 page:总消耗 = 1048576 * 40B ≈ 40MB。相对于 4GB 内存可以忽略。
页大小的权衡:
- 页太大:页内碎片大
- 页太小:页表过长、切换开销大
- Linux/Windows 默认:4KB。


2.4 页表(单级页表)
页表中每一个表项,指向一个物理页的起始地址。
32 位系统 4GB 虚拟空间:总表项 = 4GB / 4KB = 1048576 项,每项 4 字节 → 页表总大小 4MB。
问题:单级页表需要连续 1024 个物理页框存储。我们用分页解决物理连续,结果页表自己又要连续内存。
同时,根据局部性原理,进程只使用少量页,不需要全量页表。

2.5 多级页表(二级页表)&& 地址转换
解决思路:把页表再分页。
结构:
- 页目录表(PGD):1024 项
- 页表(PT):每个 1024 项
- 总覆盖:1024 * 1024 = 1048576 项,依然覆盖 4GB。
虚拟地址划分(32 位、4KB 页):10 位页目录 | 10 位页表 | 12 位页内偏移
- 页目录与页表可以离散存储
- 进程只加载用到的页表,大幅节省内存
- 支持大地址空间
- 示例:10MB 程序 → 对齐到 12MB → 需要 3 个页表 即可。


地址转换流程
- CR3 寄存器存放页目录物理地址
- 用虚拟地址高 10 位查页目录 → 找到页表
- 用中间 10 位查页表 → 找到物理页框
- 低 12 位偏移 → 最终物理地址
- 整个过程由 MMU(内存管理单元) 硬件完成。


2.6 TLB 快表(Translation Lookaside Buffer)
多级页表虽然省内存,但访问变慢(多次访存)。
解决方案:MMU 集成TLB 缓存,流程如下:
- CPU 给出虚拟地址
- MMU 先查 TLB
- 命中:直接得到物理地址
- 不命中:查页表,并把映射写入 TLB
TLB 命中率极高,极大加速地址翻译。

2.8 缺页异常 Page Fault
当虚拟地址在 TLB 与页表中都找不到物理页时,触发缺页异常。这是硬件中断,可由软件修复。
缺页异常分为三类:
- 硬缺页(Major Page Fault)物理内存中没有该页,必须从磁盘读取到内存,再建立映射。
- 软缺页(Minor Page Fault)物理内存已有该页,只是当前进程未建立映射,直接映射即可。常见于共享内存、父子进程、多线程。
- 无效缺页(Invalid Page Fault) 地址非法:越界、空指针、非法权限。触发
Segment Fault,内核直接终止进程。

三. Linux 线程本质:LWP 轻量级进程
Linux 内核没有专门的线程结构体!
- 进程、线程都用 task_struct 描述
- 线程 = 轻量级进程 LWP
- 线程共享 mm_struct(虚拟地址空间)
- 线程只私有少量执行上下文

测试样例用到的代码:
// #include <iostream>
// #include <thread>
// #include <unistd.h>
// // C++中的线程
// void hello()
// {
// while(true)
// {
// std::cout << "我是新进程..., pid: " << getpid() << std::endl;
// sleep(1);
// }
// }
// int main()
// {
// std::thread t(hello);
// while(true)
// {
// std::cout << "我是主线程..., pid: " << getpid() << std::endl;
// sleep(1);
// }
// t.join();
// return 0;
// }
#include <iostream>
#include <pthread.h>
#include <unistd.h>
// Linux中封装的线程 -- 其实Linux是只有轻量级进程的概念的
void *hello(void *args)
{
while(true)
{
const char *name = (const char*)args;
std::cout << "我是新线程..., pid: " << getpid() << " name is : "<< name <<std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, hello, (void*)"new-thread");
while(true)
{
std::cout << "我是主线程..., pid: " << getpid() << std::endl;
sleep(1);
}
return 0;
}

3.1 线程资源共享 && 线程私有资源
同一进程内所有线程共享:
- 虚拟地址空间(代码段、数据段、bss、堆、共享区)
- 文件描述符表
- 信号处理方式(SIG_IGN、SIG_DFL、自定义 handler)
- 当前工作目录
- 用户 ID、组 ID,大部分内存资源
每个线程独立拥有:
- 线程 ID(LWP、pthread_t)
- 一组寄存器(上下文)
- 独立栈空间
- errno 变量
- 信号屏蔽字
- 调度优先级

3.2 线程栈位置 && Linux中线程的理解图示
- 主线程栈:在进程默认栈区,可动态增长
- 其他线程栈:在共享区(mmap 区域)
- 由 pthread 库通过 mmap 分配
- 默认大小:8MB,固定不可动态增长

四. 线程的优缺点和异常与用途
4.1 线程的优点
创建一个新线程的代价要比创建一个新进程小的多
与进程之前的切换相比,线程之间的切换需要OS做的工作要少很多
- 最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
- 另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚拟内存空间的时候,处理的页表缓冲
TLB(快表)会被全部刷新,这将导致内存的访问在一段时间相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。
线程占用的资源要比进程少
能充分利用多处理器的并行数量
在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
计算密集型应用,为了能够在多处理器系统上运行,将计算分解到多个线程中实现
I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同d1


进一步图示解析


关于cache和TLB

4.2 线程的缺点
性能损失
- ⼀个很少被外部事件阻塞的计算密集型线程往往无法与其它线程共享同⼀个处理器。如果计
算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指
的是增加了额外的同步和调度开销,而可用的资源不变。
- ⼀个很少被外部事件阻塞的计算密集型线程往往无法与其它线程共享同⼀个处理器。如果计
健壮性降低
- 编写多线程需要更全面更深入的考虑,在⼀个多线程程序里,因时间分配上的细微偏差或者
因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
- 编写多线程需要更全面更深入的考虑,在⼀个多线程程序里,因时间分配上的细微偏差或者
缺乏访问控制
- 进程是访问控制的基本粒度,在⼀个线程中调用某些OS函数会对整个进程造成影响。
编程难度提高
- 编写与调试⼀个多线程程序比单线程程序困难得多

- 代码示例:我们通过代码可以看到我们的线程是共享全局变量,函数,甚至是malloc出来的空间
int g_val = 100;
int *p = nullptr;
void hello(const std::string &name) {
printf("haha, I am common function!, %s\n", name.c_str());
sleep(5);
}
void *threaddrun1(void *args)
{
p = (int*)malloc(sizeof(int) * 10);
std::string threadname = static_cast<const char*>(args);
while(true)
{
printf("%s is running, g_val: %d, &g_val: %p\n", threadname.c_str(), g_val, &g_val);
sleep(1);
hello(threadname);
}
}
void* threaddrun2(void *args)
{
std::string threadname = static_cast<const char*>(args);
while(true)
{
printf("%s is running, g_val: %d, &g_val: %p\n", threadname.c_str(), g_val, &g_val);
sleep(1);
g_val++;
hello(threadname);
}
}
int main()
{
pthread_t t1, t2;
pthread_create(&t1, nullptr, threaddrun1, (void*)"thread-1");
pthread_create(&t2, nullptr, threaddrun2, (void*)"thread-2");
pthread_join(t1, nullptr);
pthread_join(t2, nullptr);
return 0;
}



4.3 线程的异常与用途(异常上面的缺点中也涉及到了)
异常:
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
用途:
• 合理的使用多线程,能提高CPU密集型程序的执行效率
• 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们⼀边写代码一边下载开发工具,就是多线程运行的⼀种表现)
4.4 最简单总结
- 线程:CPU 调度的基本单位
- Linux 线程 = 轻量级进程 LWP
- 线程共享地址空间、页表、文件描述符、堆、数据段
- 线程私有:栈、寄存器、线程 ID、errno、信号屏蔽字
- 线程优点:创建快、切换快、占用少、适合多核、适合 I/O
- 线程缺点:健壮性差、一崩全崩、编程复杂
- 线程用途:加速计算、提高 I/O 体验、高并发服务
结尾
结语:线程是 Linux 并发编程的核心基石,理解其内核本质、与进程的核心区别、优缺点和适用场景,是后续掌握线程控制、同步互斥、线程安全的关键。希望这篇博客能帮你吃透线程的基础概念,后续我也会继续分享线程控制、地址空间布局等进阶内容,欢迎点赞收藏,一起交流学习~
到此这篇关于Linux系统的线程入门:基本概念、虚拟内存、Linux内核线程、线程应用的文章就介绍到这了,更多相关从内核视角理解Linux线程内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 本篇文章主要介绍了Linux定时任务Crontab详解,具有一定的参考价值,感兴趣的小伙伴们可以参考一下。2016-12-12
本篇文章主要介绍了Linux定时任务Crontab详解,具有一定的参考价值,感兴趣的小伙伴们可以参考一下。2016-12-12 sudo的目的:为非根用户授予根用户的权限,下面这篇文章主要给大家介绍了关于Linux中利用sudo进行赋权的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴,下面随着小编来一起学习学习吧。2018-01-01
sudo的目的:为非根用户授予根用户的权限,下面这篇文章主要给大家介绍了关于Linux中利用sudo进行赋权的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴,下面随着小编来一起学习学习吧。2018-01-01 文章描述了CentOS7登录慢的问题,可能是由于反向验证DNS导致的,解决方案有两个:禁用DNS解析或停止systemd-logind服务,通过修改sshd_config文件或重启sshd进程可以实现禁用DNS解析2026-04-04
文章描述了CentOS7登录慢的问题,可能是由于反向验证DNS导致的,解决方案有两个:禁用DNS解析或停止systemd-logind服务,通过修改sshd_config文件或重启sshd进程可以实现禁用DNS解析2026-04-04 这篇文章主要介绍了Linux 重命名命令自制详细介绍的相关资料,需要的朋友可以参考下2017-01-01
这篇文章主要介绍了Linux 重命名命令自制详细介绍的相关资料,需要的朋友可以参考下2017-01-01 这篇文章主要给大家介绍了关于linux下获取文件的创建时间与实战的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用linux系统具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-12-12
这篇文章主要给大家介绍了关于linux下获取文件的创建时间与实战的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用linux系统具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-12-12 这篇文章主要介绍了Linux parted 分区命令使用方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-04-04
这篇文章主要介绍了Linux parted 分区命令使用方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-04-04 下面小编就为大家带来一篇浅谈Linux中ldconfig和ldd的用法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-12-12
下面小编就为大家带来一篇浅谈Linux中ldconfig和ldd的用法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-12-12 这篇文章主要给大家介绍了在Debian 9系统下修改默认网卡为eth0的方法,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-06-06
这篇文章主要给大家介绍了在Debian 9系统下修改默认网卡为eth0的方法,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-06-06 在linux下配置开发环境有点麻烦,对于linux刚入门的菜鸟来说,命令使用不熟悉,环境也是朦朦胧胧,今天整理了一下ubnutu14.04下安装eclipse的步骤,希望对大家有用。废话不多说,进入主题2014-09-09
在linux下配置开发环境有点麻烦,对于linux刚入门的菜鸟来说,命令使用不熟悉,环境也是朦朦胧胧,今天整理了一下ubnutu14.04下安装eclipse的步骤,希望对大家有用。废话不多说,进入主题2014-09-09 在执行sudo apt-get update时遇到域名解析故障,通过修改/etc/resolvconf/resolv.conf.d/head文件,添加Google的域名服务器nameserver 8.8.8.8,成功解决问题2026-04-04
在执行sudo apt-get update时遇到域名解析故障,通过修改/etc/resolvconf/resolv.conf.d/head文件,添加Google的域名服务器nameserver 8.8.8.8,成功解决问题2026-04-04










最新评论