
MySQL必备基础之分组函数 聚合函数 分组查询详解
更新时间:2021年10月13日 10:19:33 作者:叶绿体不忘呼吸
这篇文章主要介绍了MySQL分组函数、聚合函数、分组查询,结合实例形式分析了MySQL查询分组函数以及查询聚合函数相关使用技巧,需要的朋友可以参考下
一、简单使用
SUM:求和(一般用于处理数值型)
AVG:平均(一般用于处理数值型)
MAX:最大(也可以用于处理字符串和日期)
MIN:最小(也可以用于处理字符串和日期)
COUNT:数量(统计非空值的数据个数)
以上分组函数都忽略空NULL值的数据
SELECT SUM(salary) AS 和,AVG(salary) AS 平均,MAX(salary) AS 最大,MIN(salary) AS 最小,COUNT(salary) AS 数量 FROM employees;

二、搭配DISTINCT去重
(以上函数均可)
SELECT SUM(DISTINCT salary) AS 和,AVG(DISTINCT salary) AS 平均,COUNT( DISTINCT salary) AS 去重数量,COUNT(salary) AS 不去重数量 FROM employees;

三、COUNT()详细介绍
#相当于统计行数方式一 SELECT COUNT(*) FROM employees;
#相当于统计行数方式二,其中1可以用其他常量或字段替换 SELECT COUNT(1) FROM employees;
效率问题:
MYISAM存储引擎下,COUNT(*)的效率高
INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)高
因此一般用COUNT(*)统计行数
四、分组查询
#其中[]内为可选 SELECT 分组函数,列表(要求出现在 GROUP BY 的后面) FROM 表 [WHERE 筛选条件] GROUP BY 分组列表 [ORDER BY 子句]
示例:
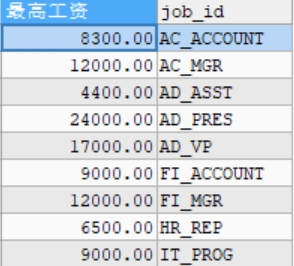
#查询每个工种的最高工资 SELECT MAX(salary) AS 最高工资,job_id FROM employees GROUP BY job_id;
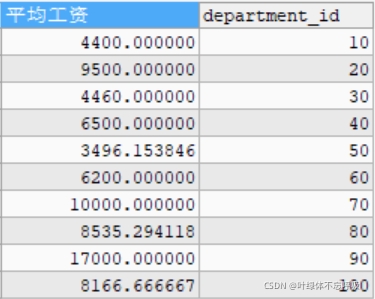
#查询每个部门中,邮箱包含a的员工的平均工资(分组前的筛选) SELECT AVG(salary) AS 平均工资,department_id FROM employees WHERE email LIKE '%a%' GROUP BY department_id;
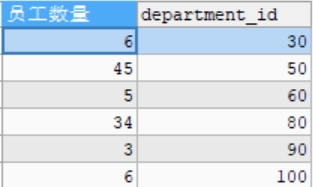
#查询部门员工数量大于2的部门的员工数量(分组后的筛选) #使用HAVING SELECT COUNT(*) AS 员工数量,department_id FROM employees GROUP BY department_id HAVING COUNT(*)>2;
#按照多字段 SELECT COUNT(*) AS 员工数量,job_id,department_id FROM employees GROUP BY job_id,department_id;

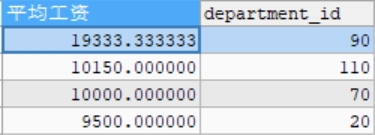
#完整结构 SELECT AVG(salary) AS 平均工资,department_id FROM employees WHERE department_id IS NOT NULL GROUP BY department_id HAVING AVG(salary)>9000 ORDER BY AVG(salary) DESC;
到此这篇关于MySQL必备基础之分组函数 聚合函数 分组查询详解的文章就介绍到这了,更多相关MySQL 分组函数 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了MySQL单表恢复的步骤,帮助大家更好的理解和学习MySQL,感兴趣的朋友可以了解下2020-08-08
这篇文章主要介绍了MySQL单表恢复的步骤,帮助大家更好的理解和学习MySQL,感兴趣的朋友可以了解下2020-08-08 MySQL SQL 语法参考...2006-12-12
MySQL SQL 语法参考...2006-12-12 上周遇到一个因insert而引发的死锁问题,其成因比较令人费解,下面这篇文章主要给大家介绍了关于MySQL insert死锁问题解决详细记录的相关资料,需要的朋友可以参考下2022-11-11
上周遇到一个因insert而引发的死锁问题,其成因比较令人费解,下面这篇文章主要给大家介绍了关于MySQL insert死锁问题解决详细记录的相关资料,需要的朋友可以参考下2022-11-11
Window下如何恢复被删除的Mysql8.0.17 Root账户及密码
这篇文章主要介绍了Window下如何恢复被删除的Mysql8.0.17 Root账户及密码,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-02-02 本文主要介绍了MySQL查看所有用户的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03
本文主要介绍了MySQL查看所有用户的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03
MySQL脏读幻读不可重复读及事务的隔离级别和MVCC、LBCC实现
这篇文章主要介绍了MySQL脏读幻读不可重复读及事务的隔离级别和MVCC、LBCC实现,事务A 按照查询条件读取某个范围的记录,其他事务又在该范围内出入了满足条件的新记录,当事务A再次读取数据到时候我们发现多了满足记录的条数2022-07-07 我们知道Mysql并发事务会引起更新丢失问题,解决办法是锁,所以本文将对锁(乐观锁、悲观锁)进行分析,这篇文章主要给大家介绍了关于MySQL悲观锁与乐观锁方案的相关资料,需要的朋友可以参考下2021-11-11
我们知道Mysql并发事务会引起更新丢失问题,解决办法是锁,所以本文将对锁(乐观锁、悲观锁)进行分析,这篇文章主要给大家介绍了关于MySQL悲观锁与乐观锁方案的相关资料,需要的朋友可以参考下2021-11-11 mysql myisam 优化设置设置,需要的朋友可以参考下。2010-03-03
mysql myisam 优化设置设置,需要的朋友可以参考下。2010-03-03 在MySQL中,查看用户权限可以通过多种方式实现,主要取决于我们想要查看的权限类型和详细程度,本文给大家介绍了MySQL查看用户权限及权限管理的方法,并通过代码示例介绍的非常详细,需要的朋友可以参考下2024-03-03
在MySQL中,查看用户权限可以通过多种方式实现,主要取决于我们想要查看的权限类型和详细程度,本文给大家介绍了MySQL查看用户权限及权限管理的方法,并通过代码示例介绍的非常详细,需要的朋友可以参考下2024-03-03 这篇文章主要介绍了关于MySql的kill命令详解,不知道你在使用 MySQL 的时候,有没有遇到过这样的现象:使用了 kill 命令,却没能断开这个连接,今天我们就来讲一讲这个问题,需要的朋友可以参考下2023-05-05
这篇文章主要介绍了关于MySql的kill命令详解,不知道你在使用 MySQL 的时候,有没有遇到过这样的现象:使用了 kill 命令,却没能断开这个连接,今天我们就来讲一讲这个问题,需要的朋友可以参考下2023-05-05










最新评论