
聚合函数和group by的关系详解
前言
world:世界表格
continent:大洲名称
name:国家名称
population:人口数量
聚合函数介绍
| sum() | 求和函数 |
|---|---|
| avg() | 求平均值函数 |
| max() | 求最大值函数 |
| min() | 求最小值函数 |
| count() | 求行数函数 |
group by介绍
group up + 字段名:规定哪个字段分组聚合
在单独使用使用时,作用为分组去重 结果与distinct一样,但是逻辑并不一样:先对字段值相同的分为一个区,再将同区的拿出来进行分组,对应多少值就分多少组。分组就是将相同的字段进行剔除。简单来说,就是打破了表格的格式生成了一张新的表格。
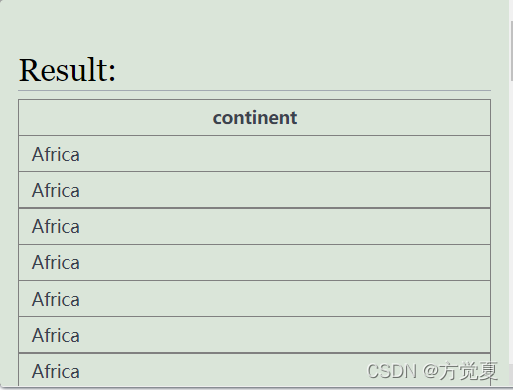

例如在上面这张表格就是执行group up后形成的分区结果,将相同的字段值分在了一起。下面的表格即是执行group by分组的结果,基于上面分区的结果,进行了去重的分组。

解释聚合函数和group by的关系
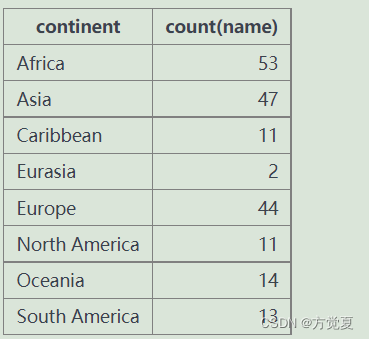
那么为什么使用group by会形成这样的结果呢?我们可以使用上聚合函数进行分析原因,执行下面一句SQL代码。
select continent,count(name) from world group by continent
结果为
那么我们试着将group by continent和continent去掉,得到以下结果
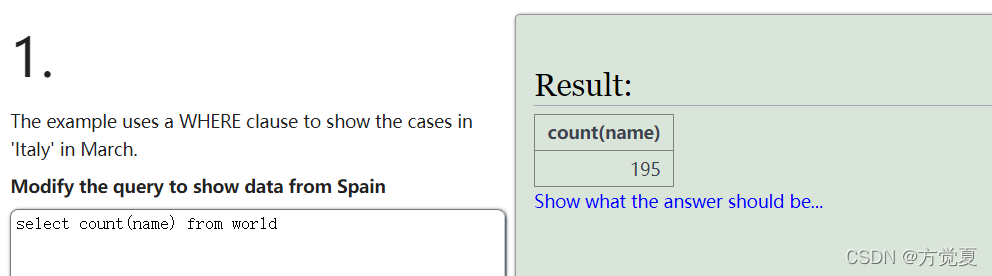
结果执行后查询出来 count(name) 就只是所有 name 这一列的行数的总合,并不能将每个大洲(continent)进行分组统计出来每个大洲所有国家(name)的数量。
这就是聚合函数和group by联合使用的作用,帮助聚合函数找到分组后的表格进行计算,在这一句
select continent,count(name) from world group by continent
SQL语句中是先进行了group by的分组,在进行select continent,最后在进行count(name),基于的就是group by后的分组进行计算。
我们可以将continent的字段名删除,查看结果是否统一,作为印证。

很明显我们无论有没有将continent进行显示,结果都是一样的。
通过这次测试,我们就可以得出相对应的结论:在group up执行的时候,就已经将表格生成出来了,select只是选择展示和不展示出来而已,对于结果并没有影响。而聚合函数的作用就是在生成出来新的表格内进行计算,舍弃了没有进行分组的表格。
使用group by和聚合函数需要注意的地方
在使用group up子句时,select只能使用聚合函数和group up引用的字段,否则会报错!
尝试执行下列SQL语句:
select continent,count(name),population from world group by continent

为什么会出现报错呢,因为在这句SQL语句中,group by已经先运行了,所以select不能出现在group by中没有的字段,只能基于在聚合依据的这个表中进行字段匹配。
总结
到此这篇关于聚合函数和group by的关系详解的文章就介绍到这了,更多相关聚合函数和group by内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 网站随着数据量与访问量越来越大,访问的速度变的越来越慢,于是开始想办法解决优化速度慢的原因,下面是对程序中一条sql的分析与提高效率的过程2018-03-03
网站随着数据量与访问量越来越大,访问的速度变的越来越慢,于是开始想办法解决优化速度慢的原因,下面是对程序中一条sql的分析与提高效率的过程2018-03-03 DBeaver 可通过 JDBC 连接到数据库,可以支持几乎所有的数据库产品,本文介绍常用一种通用数据库工具Dbeaver,通过DBeaver连接Phoenix操作hbase的操作,需要的朋友跟随小编一起看看吧2021-11-11
DBeaver 可通过 JDBC 连接到数据库,可以支持几乎所有的数据库产品,本文介绍常用一种通用数据库工具Dbeaver,通过DBeaver连接Phoenix操作hbase的操作,需要的朋友跟随小编一起看看吧2021-11-11
关于Rsa Public Key not Find的问题及解决
这篇文章主要介绍了关于Rsa Public Key not Find的问题及解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-07-07 这篇文章主要介绍了mybatis映射XML文件详解及实例的相关资料,需要的朋友可以参考下2017-03-03
这篇文章主要介绍了mybatis映射XML文件详解及实例的相关资料,需要的朋友可以参考下2017-03-03 HBase是一种针对海量数据的key-value型NoSQL数据库,本文详细介绍了在Linux系统下HBase的安装与配置步骤,本文给大家介绍Linux的HBASE数据库集群部署方法,感兴趣的朋友一起看看吧2024-10-10
HBase是一种针对海量数据的key-value型NoSQL数据库,本文详细介绍了在Linux系统下HBase的安装与配置步骤,本文给大家介绍Linux的HBASE数据库集群部署方法,感兴趣的朋友一起看看吧2024-10-10
StarRocks数据库查询加速及Colocation Join工作原理
本文详细解释了StarRocks数据库中数据的分区和分桶策略,重点介绍了ColocationJoin的工作原理,即如何通过相同分桶列和副本数确保在本地进行Join操作,从而提升查询性能,感兴趣的朋友一起看看吧2025-03-03 最近TDengine很火,本人也一直很早就有关注,其官方给出的测试性能结果很喜人,所以一开源,本人就进行了相关调研,最终发现还是存在着一定的问题,期待后续的完善吧2022-03-03
最近TDengine很火,本人也一直很早就有关注,其官方给出的测试性能结果很喜人,所以一开源,本人就进行了相关调研,最终发现还是存在着一定的问题,期待后续的完善吧2022-03-03 非常不错使用join on实现数据库字段的连接输出效果。2009-07-07
非常不错使用join on实现数据库字段的连接输出效果。2009-07-07 问个高难度的复杂查询(在一个时间段内的间隔查询)...2007-04-04
问个高难度的复杂查询(在一个时间段内的间隔查询)...2007-04-04 这篇文章介绍了SQLite与MySQL的区别及优缺点,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-01-01
这篇文章介绍了SQLite与MySQL的区别及优缺点,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-01-01










最新评论