
如何解决mysql深度分页问题
更新时间:2023年01月09日 09:19:37 作者:苍穹之跃
这篇文章主要介绍了如何解决mysql深度分页问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教
mysql深度分页问题
数据:单表数据25万条。
1.基本分页:耗时0.019秒
select * from cf_qb_info limit 0,20
2.深度分页:耗时10.236秒
select * from cf_qb_info limit 200000,20
3.深度ID分页:耗时0.052秒
提示:如果这一步很慢,count(1) 查询总数应该也会很慢-解决方式:请为主键加上unique索引。
-- 主键ID字段:NUMID select NUMID from cf_qb_info limit 200000,20
4.两步走深度分页:耗时0.049秒+0.017秒
基于第三步的缺陷(只能查出ID信息),我们可以先查出分页数据的ID,在根据ID查询数据。
select NUMID from cf_qb_info LIMIT 200000,20
select * from cf_qb_info where NUMID in ( '330681650000202108180227345510', '330681650000202108171031534500', '330681650000202108190251532141', '330681650000202108200246376830', '330681650000202108210229398665', '330681650000202108220236113895', '330681650000202108230230034133', '330681650000202108231017279739', '330681650000202108231043456276', '330681650000202108231051404340', '330681650000202108240237397251', '330681650000202108250221489228', '330681650000202108250241536726', '330681650000202108260253039326', '330681650000202108270216016138', '330681650000202108280234013754', '330681650000202108290230029720', '330681650000202108300255579204', '330681650000202108310234184991', '330681650000202109010237315937' );
两步合成一步SQL耗时:11.9秒;这一步着实出乎了我的意料。
select * from cf_qb_info where NUMID in ( select NUMID from (select NUMID from cf_qb_info LIMIT 200000,20) as t );
鉴于这个结果:我们可以在程序里分成两步进行分页查询。
5.一步走深度分页:耗时0.05秒
这一步是对第四步的优化,毕竟两条SQL还需要码代码。利用join 两条SQL合成一条。
SELECT * FROM cf_qb_info a JOIN ( SELECT NUMID FROM cf_qb_info LIMIT 200000, 20 ) b ON a.NUMID = b.NUMID
6.集成BeanSearcher框架
原理是使用了BeanSearcher的sql拦截器对SQL进行拦截改造。
①改造Bean

②注入Sql拦截器
package com.ciih.qbbs.config;
import cn.hutool.core.util.ReUtil;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.annotation.TableId;
import com.ejlchina.searcher.SearchSql;
import com.ejlchina.searcher.SqlInterceptor;
import com.ejlchina.searcher.SqlSnippet;
import com.ejlchina.searcher.param.FetchType;
import org.springframework.stereotype.Component;
import java.lang.reflect.Field;
import java.util.List;
import java.util.Map;
/**
* BeanSearcher的Sql拦截器:优化深度分页
*
* @author sunziwen
*/
@Component
public class SqlInterceptorImpl implements SqlInterceptor {
@Override
public <T> SearchSql<T> intercept(SearchSql<T> searchSql, Map<String, Object> paraMap, FetchType fetchType) {
/**
* 改造思路
*
* <>
* 前:SELECT * FROM table1 t1 LIMIT 200000,20;
* 后:SELECT * FROM table1 t1 JOIN ( SELECT id FROM table1 LIMIT 200000, 20 ) t99 ON t1.id = t99.id;
* </>
*/
Field[] fields = searchSql.getBeanMeta().getBeanClass().getDeclaredFields();
String primaryColumnName = null;
for (Field field : fields) {
//这里使用了mybatis_plus的注解作为主键标识
TableId tableId = field.getAnnotation(TableId.class);
if (tableId != null) {
if (!"".equals(tableId.value())) {
primaryColumnName = tableId.value();
} else {
//驼峰转下划线
primaryColumnName = StrUtil.toUnderlineCase(field.getName());
}
}
}
//如果没有主键标识,则不能进行SQL优化。
if (primaryColumnName == null) {
return searchSql;
}
//正则表达式获取where之后语句
List<String> limits = ReUtil.findAll("where[\\s\\S]*limit[ ]+[?]{1}[ ]*,[ ]+[?]{1}", searchSql.getListSqlString(), 0);
//如果不分页,则不进行SQL优化,即语句中没有limit关键字不优化。
if (limits.size() == 0) {
return searchSql;
}
//表名小片段
SqlSnippet tableSnippet = searchSql.getBeanMeta().getTableSnippet();
//合成子查询SQL
String inSql = "JOIN ( SELECT " + primaryColumnName + " FROM " + tableSnippet.getSql() + " " + limits.get(0) + " ) t99 ON t1." + primaryColumnName + " = t99." + primaryColumnName + ";";
//合成整条SQL
String replace = searchSql.getListSqlString().replace(limits.get(0), inSql);
//替换
searchSql.setListSqlString(replace);
return searchSql;
}
}7.万能优化技巧:索引
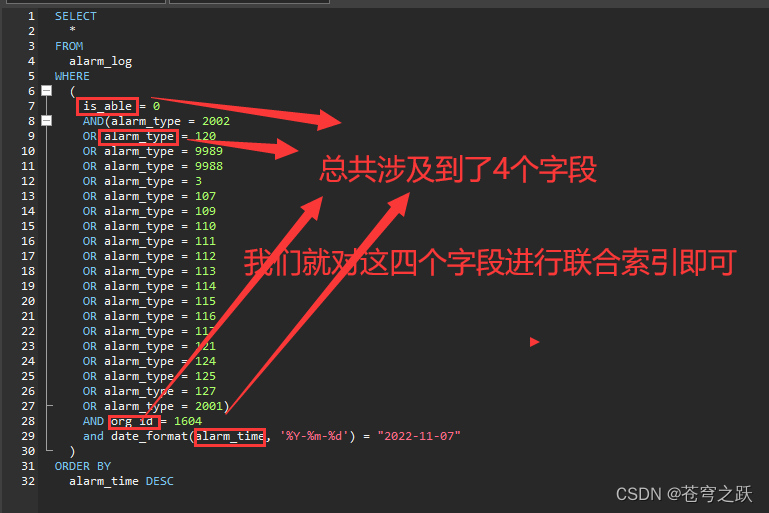
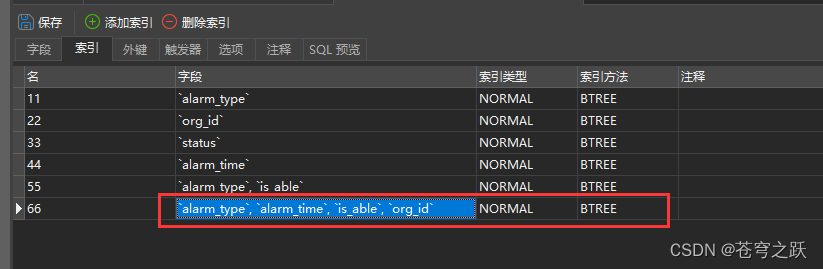
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章

mysql密码忘记后如何修改密码(2022年最新版详细教程保姆级)
因为长时间不操作mysql而忘记root密码的朋友估计不在少数,下面这篇文章主要给大家介绍了关于mysql密码忘记后如何修改密码的相关资料,本教程是2022年最新版详细教程保姆级,需要的朋友可以参考下2022-04-04
MySQL三大日志之redo log、undo log、binlog示例详解
在MySQL数据库的运行机制中,Redo Log、Undo Log和Binlog起着至关重要的作用,它们各司其职,共同保障数据库的数据安全、事务一致性以及高效的复制与恢复功能,这篇文章主要介绍了MySQL三大日志之redo log、undo log、binlog的相关资料,需要的朋友可以参考下2025-09-09 这篇文章主要给大家介绍了关于MySQL找出未提交事务SQL的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-12-12
这篇文章主要给大家介绍了关于MySQL找出未提交事务SQL的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-12-12 这篇文章主要介绍了Mysql+Keepalived实现双主热备方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-10-10
这篇文章主要介绍了Mysql+Keepalived实现双主热备方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-10-10
MySQL insert into select 主键冲突解决方案
本文主要介绍了MySQL insert into select主键冲突解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2024-06-06 这篇文章主要介绍了vs如何读取mysql中的数据并解决中文乱码问题,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-09-09
这篇文章主要介绍了vs如何读取mysql中的数据并解决中文乱码问题,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-09-09 树形结构对大家来说应该都不陌生,在日常开发中经常会遇到,下面这篇文章主要给大家介绍了关于Mysql树形结构的数据库表设计的相关资料,文中通过示例代码的非常详细,需要的朋友可以参考下2021-09-09
树形结构对大家来说应该都不陌生,在日常开发中经常会遇到,下面这篇文章主要给大家介绍了关于Mysql树形结构的数据库表设计的相关资料,文中通过示例代码的非常详细,需要的朋友可以参考下2021-09-09
CentOS7下mysql 8.0.16 安装配置方法图文教程
这篇文章主要为大家详细介绍了CentOS7下mysql 8.0.16 安装配置方法图文教程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-05-05 这篇文章主要介绍了Mybatis特殊字符处理的详解的相关资料,需要的朋友可以参考下2017-07-07
这篇文章主要介绍了Mybatis特殊字符处理的详解的相关资料,需要的朋友可以参考下2017-07-07 最近重新踩了一下mysql 这边的坑,记录一下自己忽略的地方,下面这篇文章主要给大家介绍了关于MySQL用命令行运行sql文件的详细图文教程,文中通过实例代码的非常详细,需要的朋友可以参考下2023-01-01
最近重新踩了一下mysql 这边的坑,记录一下自己忽略的地方,下面这篇文章主要给大家介绍了关于MySQL用命令行运行sql文件的详细图文教程,文中通过实例代码的非常详细,需要的朋友可以参考下2023-01-01










最新评论