
把CSV文件导入到SQL Server表中的方法
有时候我们可能会把CSV中的数据导入到某个数据库的表中,比如做报表分析的时候。
对于这个问题,我想一点也难不倒程序人员吧!但是要是SQL Server能够完成这个任务,岂不是更好!
对,SQL Server确实有这个功能。
首先先让我们看一下CSV文件,该文件保存在我的D:盘下,名为csv.txt,内容是:
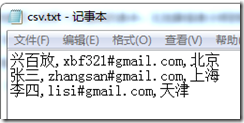
现在就是SQL Server的关键部分了;
我们使用的是SQL Server的BULK INSERT命令,关于该命令的详细解释,请点击此处;
我们先在SQL Server中建立用于保存该信息的一张数据表,
CREATE TABLE CSVTable( Name NVARCHAR(MAX), Email NVARCHAR(MAX), Area NVARCHAR(MAX) )
然后执行下面的语句:
BULK INSERT CSVTable FROM 'D:\csv.txt' WITH( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n' ) SELECT * FROM CSVTable
按F5,执行结果如下:
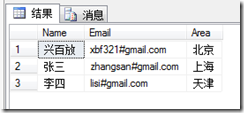
怎么样?是不是比用程序简单!
但是现在有几个问题需要考虑一下:
1,CSV文件中有的列值是用双引号,有的列值则没有双引号:
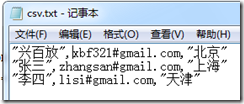
如果再次运行上面的语句,得到结果就和上一个结果不同了:
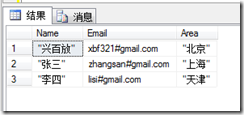
其中有的列就包含双引号了,这应该不是我们想要的结果,要解决这个问题,我们只能利用临时表了,先把CSV导入到临时表中,然后在从这个临时表中导入到最终表的过程中把双引号去掉。
2,CSV文件的列值全部是由双引号组成的:
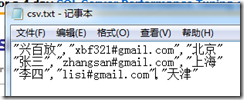
这个问题要比上一个稍微复杂点,除了要先把CSV文件导入到临时表中,还必须修改一下在把CSV文件导入到临时表的代码:

注意圈中的部分。
3,CSV文件的列要多于数据表的列:
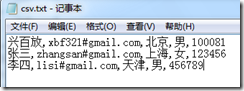
而我们的数据表只有三列,如果在执行上面的导入代码,会产生什么结果呢?
结果就是:
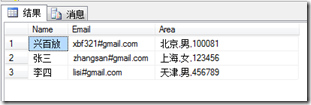
它把后边的全部放在了Area列中了,要处理这个问题,其实也很简单,就是我们把我们想要的列值在数据表中都按顺序建立一列,而把不需要的列值,也在数据表中建立一个,只不过只是一个临时列,在把这个数据表导入到最终表的时候,忽略这个临时列就行了。
相关文章

winXP系统安装SQLServer2005开发版具体过程与注意问题
XP系统系统只能安装SQL Server 2005开发版,可以到到网上下载SQL Server 2005开发版的iso文件2009-08-08
sql2005附加数据库操作步骤(sql2005还原数据库)
本文介绍了sql2005附加数据库的操作步骤,简单几步就可以完成,大家参考使用吧2014-01-01 sql2005中或安装后sa用户无法登陆系统的处理方法。2009-07-07
sql2005中或安装后sa用户无法登陆系统的处理方法。2009-07-07
sqlserver2005 TSql新功能学习总结(数据类型篇)
sql server2005 TSql新功能学习总结(数据类型篇) ,希望对需要的朋友有所帮助。2010-07-07 视图是一种常用的数据库对象,它将查询的结果以虚拟表的形式存储在数据中2012-08-08
视图是一种常用的数据库对象,它将查询的结果以虚拟表的形式存储在数据中2012-08-08 使用sql的计划任务可以处理一些特殊环境的数据,除了使用windows系统的计划任务来定时处理,不过要配合程序才行,有些事情可以直接使用sql本身的计划任务,更方便,所以本文图解一下Sql2005计划任务的创建使用。2010-03-03
使用sql的计划任务可以处理一些特殊环境的数据,除了使用windows系统的计划任务来定时处理,不过要配合程序才行,有些事情可以直接使用sql本身的计划任务,更方便,所以本文图解一下Sql2005计划任务的创建使用。2010-03-03
SQLServer2005安装提示服务无法启动原因分析及解决
安装时出现了如下错误:SQL Server 2005 安装错误码29503,接下来讲解一下,错误原因及解决方法,感兴趣的你可以参考下,或许对你有所帮助2013-03-03 在查询分析器中写了半天的SQL,竟忘了保存,坑爹啊~想找回某段时间曾执行过的一段SQL语句,怎么办2011-10-10
在查询分析器中写了半天的SQL,竟忘了保存,坑爹啊~想找回某段时间曾执行过的一段SQL语句,怎么办2011-10-10 相信大家都在当心数据库的丢失,这也是每个开发者头痛的一件事件,因为正在运行的服务器及数据库也在这台服务器上2014-04-04
相信大家都在当心数据库的丢失,这也是每个开发者头痛的一件事件,因为正在运行的服务器及数据库也在这台服务器上2014-04-04 pivot和unpivot实现行列转换,这极大的方便了我们存储数据和呈现数据,下面对这两个关键字进行分析,结合实例讲解如何存储数据,如何呈现数据2013-08-08
pivot和unpivot实现行列转换,这极大的方便了我们存储数据和呈现数据,下面对这两个关键字进行分析,结合实例讲解如何存储数据,如何呈现数据2013-08-08










最新评论