
StarRocks数据库查询加速及Colocation Join工作原理
注:本篇文章阐述的是StarRocks-3.2版本的Colocation Join
官网文章地址:
一、StarRocks数据划分
在介绍Colocation Join之前,再回顾下StarRocks的数据划分及tablet多副本机制。
StarRocks支持两层的数据划分,第一层是Range Partition,第二层是Hash Bucket(Tablet)。StarRocks的数据表按照分区分桶规则,被水平切分成若干个数据分片(Tablet,也称作数据分桶 Bucket)存储在不同的be节点上,每个tablet都有多个副本(默认是3副本)。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。Tablet 是数据移动、复制等操作的最小物理存储单元。 一个 Tablet 只属于一个数据分区(Partition),而一个 Partition 包含若干个 Tablet。
下图说明 Table、Partition、Bucket(Tablet) 的关系:
- 假设Table 按照 Range 的方式按照 date 字段进行分区,得到了 N 个 Partition
- 每个 Partition 通过相同的 Hash 方式将其中的数据划分为 M 个 Bucket(Tablet)
- 从逻辑上来说,Bucket 1 可以包含 N 个 Partition 中划分得到的数据,比如下图中的 Tablet 11、Tablet 21、Tablet N1
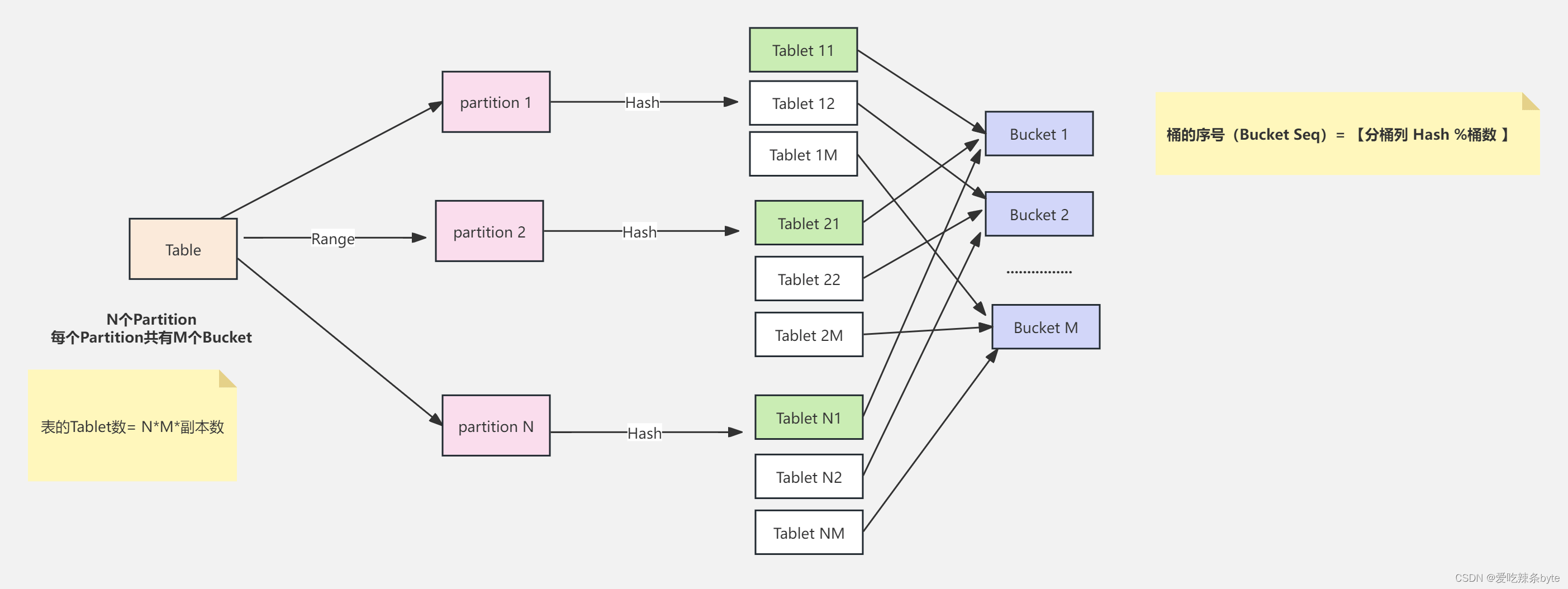
1.1 分区
逻辑概念,分区用于将数据划分成不同的区间,主要作用是将一张表按照分区键拆分成不同的管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
1.2 分桶
物理概念,StarRocks一般采用Hash算法作为分桶算法。在同一分区内,分桶键哈希值相同的数据会划分到同一个tablet(数据分片),tablet以多副本冗余的形式存储,是数据均衡和恢复的最⼩单位,数据导入和查询最终都下沉到所涉及的 tablet副本上。
二、Colocation Join实现原理
2.1 Colocate Join概述
在数据分布满足一定条件的前提下,计算节点只需做本地 Join,减少跨节点的数据移动和网络传输开销,提高查询性能。Colocate Join 十分适合几张大表按照相同字段分桶的场景,这样可以将数据预先存储到相同的分桶中,实现本地计算。
要理解这个算法,需要先了解以下几个概念:
- Colocation Group(CG):同一 CG 内的表需遵循相同的 Colocation Group Schema(CGS),即表对应的分桶副本具有一致的分桶键、副本数量和副本放置方式。如此可以保证同一 CG 内,所有表的数据分布在相同一组 BE 节点上。
- Colocation Group Schema(CGS):用于描述一个 CG 中的Table,和Colocation相关的通用 Schema 信息。包括分桶列类型,分桶数以及副本数等。
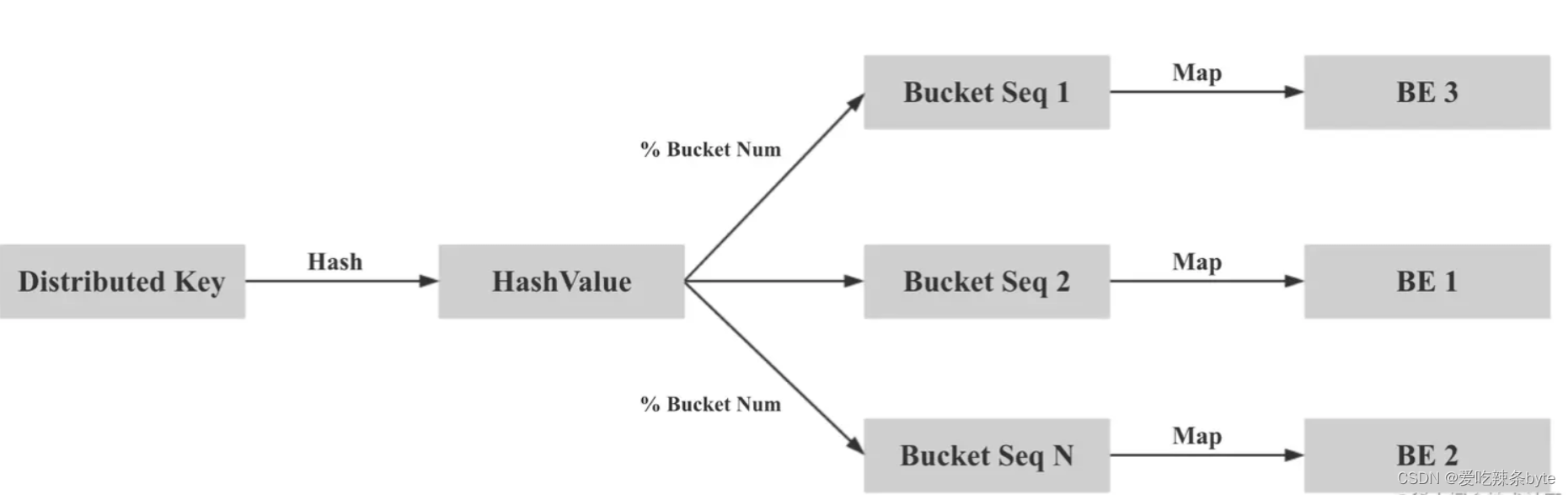
- 分桶编号Bucket Seq:一个表的数据,根据分桶列 Hash、对桶数取模后落在某一个分桶内。假设一个 Table 的分桶数为 8,则共有 [0, 1, 2, 3, 4, 5, 6, 7] 8 个分桶(Bucket)。因此【分桶列 Hash %桶数 】一致的数据会划分到同一个桶中。
2.2 Colocate Join工作原理
Colocation Join 功能,是将一组拥有相同CGS 的 Table 组成一个 CG。并保证这些 Table 对应的数据分片会落在同一个 BE 节点上。使得当 CG 内的表进行分桶列上的 Join 操作时,可以通过直接进行本地数据 Join,减少数据在节点之间的传输耗时。
因此核心问题直接转变成【如果保证这些table对应的数据分片会落在同一个be节点上?】
同一 CG 内的Table必须保证以下属性:
(1)分桶列和分桶数
同一 CG内表的分桶键的类型、数量和顺序完全一致,并且桶数一致,从而保证多张表的数据分片能够一一对应地进行分布控制。
分桶列,即在建表语句中distributed by hash(col1, col2, ...) 中指定的列。分桶列决定了一张表的数据通过哪些列的值进行Hash划分到不同的Tablet 中。同一 CG内的 Table 必须保证分桶列的类型和数量完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
(2)副本数
同一个 CG内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。不过,同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
ps:同一个 CG 内所有表的分区键,分区数量可以不同。因为Partition只是一个逻辑上的分区,真正影响数据分布在哪一个BE节点的是由Bucket决定的。
综上,在固定了分桶列和分桶数后,同一个CG内的表会拥有相同的Buckets Seq。而副本数决定了每个分桶内的 Tablet 的多个副本分别存放在哪些 BE 上。假设Buckets Seq为 [0, 1, 2, 3, 4, 5, 6, 7],BE 节点有 [A, B, C, D] 4个。则一个可能的数据分布如下:

CG 内表的一致的数据分布定义和tablet副本映射,能够保证分桶列值相同的数据都在同一个 BE 节点上,可以进行本地数据 Join。其核心思想是「两次映射」,保证相同的 Distributed Key 的数据会被映射到相同的 Bucket Seq,再保证 Bucket Seq对应的 Bucket 映射到相同的 BE 节点:
三、应用案例
Colocation Join的使用案例见官网:
Colocate Join | StarRocks本小节介绍如何使用 Colocate Join。
https://docs.starrocks.io/zh/docs/3.1/using_starrocks/Colocate_join/
参考文章:
Apache Doris的Colocation join本地join实现_colocation 怎么做-CSDN博客
第2.9章:StarRocks表设计--Colocation Join_show colocation_group-CSDN博客
编程小梦|Apache Doris Colocate Join 原理与实践
到此这篇关于StarRocks数据库查询加速及Colocation Join工作原理的文章就介绍到这了,更多相关StarRocks查询加速内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 SQL注入是比较常见的网络攻击方式之一,它不是利用操作系统的BUG来实现攻击,而是针对程序员编程时的疏忽,通过SQL语句,实现无帐号登录,甚至篡改数据库。下面这篇文章主要给大家介绍了关于防止SQL注入的5种方法,教大家有效的防止sql注入,需要的朋友可以参考学习。2017-03-03
SQL注入是比较常见的网络攻击方式之一,它不是利用操作系统的BUG来实现攻击,而是针对程序员编程时的疏忽,通过SQL语句,实现无帐号登录,甚至篡改数据库。下面这篇文章主要给大家介绍了关于防止SQL注入的5种方法,教大家有效的防止sql注入,需要的朋友可以参考学习。2017-03-03 Hive是一个构建在Hadoop上的数据仓库框架,最初,Hive是由Facebook开发,后台移交由Apache软件基金会开发,并做为一个Apache开源项目,感兴趣的同学可以参考阅读2023-04-04
Hive是一个构建在Hadoop上的数据仓库框架,最初,Hive是由Facebook开发,后台移交由Apache软件基金会开发,并做为一个Apache开源项目,感兴趣的同学可以参考阅读2023-04-04 在实际的数据库使用中除了CRUD还有很多高级应用值得学习和掌握,能够在平时的工作中得到很多便利,这篇文章主要给大家分享介绍了14种SQL的进阶用法,通过文中介绍的方法可以更高效地处理数据库数据,需要的朋友可以参考下2024-01-01
在实际的数据库使用中除了CRUD还有很多高级应用值得学习和掌握,能够在平时的工作中得到很多便利,这篇文章主要给大家分享介绍了14种SQL的进阶用法,通过文中介绍的方法可以更高效地处理数据库数据,需要的朋友可以参考下2024-01-01 大家好,本篇文章主要讲的是使用Sqlyog远程连接数据库报错解决方案,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下,方便下次浏览2021-12-12
大家好,本篇文章主要讲的是使用Sqlyog远程连接数据库报错解决方案,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下,方便下次浏览2021-12-12 Sql语句求最小可用id...2007-04-04
Sql语句求最小可用id...2007-04-04 这篇文章主要介绍了postgresql 按小时分表(含触发器)的实现方式,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-01-01
这篇文章主要介绍了postgresql 按小时分表(含触发器)的实现方式,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-01-01 如何用分表存储来提高性能 ,需要的朋友可以参考下。2011-09-09
如何用分表存储来提高性能 ,需要的朋友可以参考下。2011-09-09 这篇文章主要介绍了一款免费开源的通用数据库工具DBeaver,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-10-10
这篇文章主要介绍了一款免费开源的通用数据库工具DBeaver,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-10-10 这篇文章仅仅是对SQL注入进行了一个简单的入门知识的讲解,是sql注入的基础篇,有个好的开头能够帮助大家对SQL注入有一个具体清晰的了解和认识。下面来一起看看吧,有需要的可以参考借鉴。2016-09-09
这篇文章仅仅是对SQL注入进行了一个简单的入门知识的讲解,是sql注入的基础篇,有个好的开头能够帮助大家对SQL注入有一个具体清晰的了解和认识。下面来一起看看吧,有需要的可以参考借鉴。2016-09-09 数据完整性是指数据的正确性、完备性和一致性,是衡量数据库质量好坏的规范。数据库完整性由各式各样的完整性约束来确保,因而可以说数据库完整性规划即是数据库完整性约束的规划。那么,数据库设计的完整性约束表现哪些方面?2015-10-10
数据完整性是指数据的正确性、完备性和一致性,是衡量数据库质量好坏的规范。数据库完整性由各式各样的完整性约束来确保,因而可以说数据库完整性规划即是数据库完整性约束的规划。那么,数据库设计的完整性约束表现哪些方面?2015-10-10










最新评论