
Redis和数据库的一致性(Canal+MQ) 的实现
想要保证缓存与数据库的双写一致,一共有4种方式,即4种同步策略:
- 先更新缓存,再更新数据库;
- 先更新数据库,再更新缓存;
- 先删除缓存,再更新数据库;
- 先更新数据库,再删除缓存
首先说好结论,这4种同步策略无论是哪一种,都无法保证数据库和redis的强一致性,只能保证最终一致性,如要保证强一致,那么只能通过加锁来实现,那么就会造成性能问题,即CAP理论中的AP(强一致)和CP(高可用性)进行取舍,绝大多数场景是确保高可用(CP)。
更新缓存还是删除缓存
下面,我们来分析一下,应该采用更新缓存还是删除缓存的方式。
1、更新缓存
优点:每次数据变化都及时更新缓存,所以查询时不容易出现未命中的情况。
缺点:更新缓存的消耗比较大。如果数据需要经过复杂的计算再写入缓存,那么频繁的更新缓存,就会影响服务器的性能。如果是写入数据频繁的业务场景,那么可能频繁的更新缓存时,却没有业务读取该数据。
2、删除缓存
优点:操作简单,无论更新操作是否复杂,都是将缓存中的数据直接删除。
缺点:删除缓存后,下一次查询缓存会出现未命中,这时需要重新读取一次数据库。从上面的比较来看,一般情况下,删除缓存是更优的方案。
先操作数据库还是更新缓存
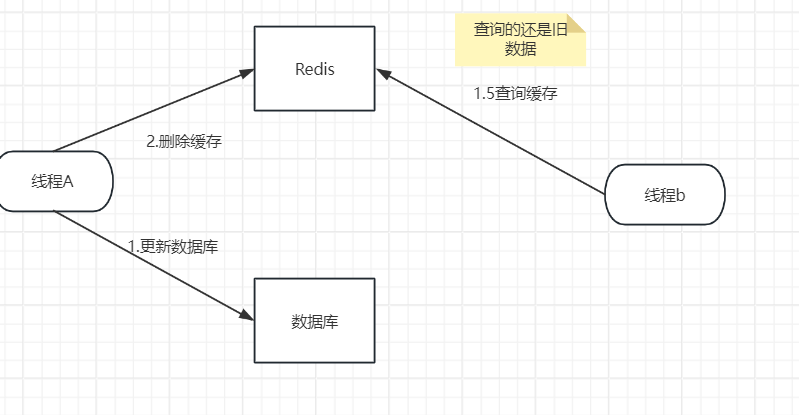
1.先更新数据库再删除缓存
- 线程A更新数据库成功,线程A删除缓存失败;
- 线程B读取缓存成功,由于缓存删除失败,所以线程B读取到的是缓存中旧的数据。
- 最后线程A删除缓存成功,有别的线程访问缓存同样的数据,与数据库中的数据是一样。
- 最终,缓存和数据库的数据是一致的,但是会有一些线程读到旧的数据。
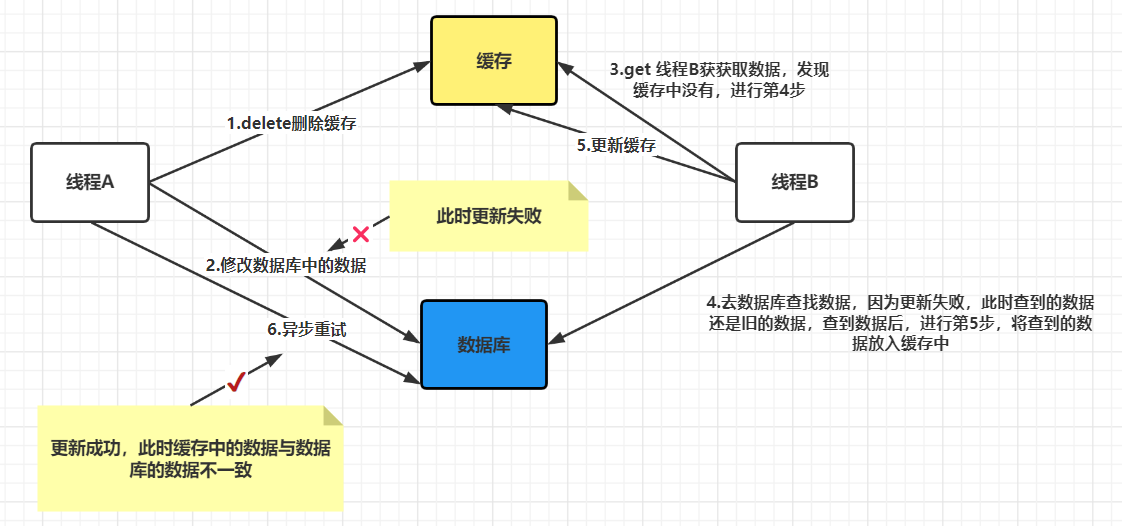
1.2正常情况下没有出现失败场景
在并发场景下,也许会有些许线程像线程b一样读的是旧数据,但在删除缓存后,最终缓存与数据库的数据是一致的,并且都是最新的数据。但线程B在这个过程里读到了旧的数据,可能还有其他线程也像线程B一样,在这两步之间读到了缓存中旧的数据,但因为这两步的执行速度会比较快,所以影响不大。对于这两步之后,其他进程再读取缓存数据的时候,就不会出现类似于进程B的问题了。
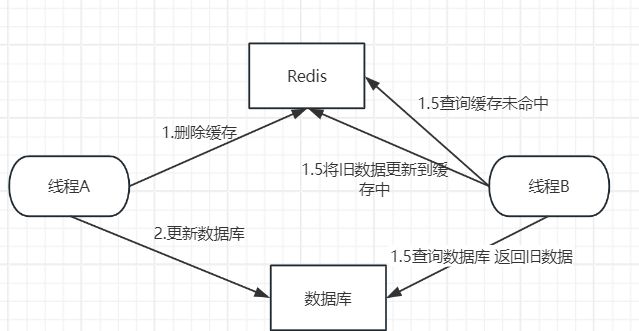
2.先删除缓存再更新数据库
- 线程A删除缓存成功,线程A更新数据库失败;
- 线程B从缓存中读取数据;由于缓存被删,进程B无法从缓存中得到数据,进而从数据库读取数据;此时数据库中的数据更新失败,线程B从数据库成功获取旧的数据,然后将数据更新到了缓存。
- 最终,如果没有异步重试的话缓存和数据库的数据是一致的,但仍然是旧的数据。
2.2正常情况下没有出现失败场景
进程A的两步操作均成功,但由于存在并发,在这两步之间,进程B访问了缓存。最终结果是,缓存中存储了旧的数据,而数据库中存储了新的数据,二者数据不一致。
这种方式的解决方案也就是在第2步更新数据库后,延迟一会再删一次Redis,也就是延迟双删,这样就可以保证最终数据一致性。
最终结论:
经过对比你会发现,先更新数据库、再删除缓存是影响更小的方案。如果第二步出现失败的情况,则可以采用重试机制解决问题。
最终解决方案
利用(MQ)消息队列和Canal中间件进行删除的补偿
Canal目前在大型企业中热度下降,使用flinkcdc是目前的趋势,而目前主流CDC(变更数据获取)是flink cdc 而flinkcdc插件是基于flink平台(大数据平台)此处只需要简单理解Canal作用并简单实现即可。目前企业中常见的数据同步方案就是CDC中间件+MQ的方案,大型公司一般是有大数据业务,所以使用大数据平台和kafka,此处使用的是Canal+Rabbitmq
Canal安装与部署
Mysql前置准备
在服务中找到Mysql配置文件对应目录
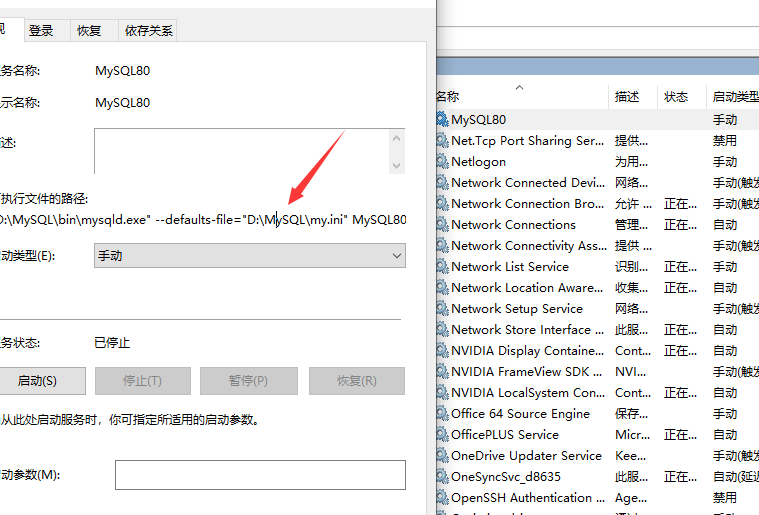
其中一共需要注意四个配置项
server-id=1 #master端的ID号【必须是唯一的】; log-bin=D:\MySQL\binlog\mysql-bin.log #同步的日志路径,一定注意这个目录要是mysql有权限写入的 binlog_format=row #行级,记录每次操作后每行记录的变化。 binlog-do-db=db_xiaomi #指定库,缩小监控的范围。
1.查看端口号配置对应主要用于集群环境下区分id
2.创建binlog文件存放目录

3.数据的保存格式(一共有三种)
4.指定需要监控的库名(如果该项不指定配置,那么默认所有数据库开启binlog)
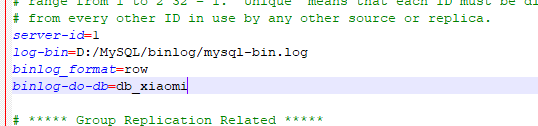
设置好后启动服务。
启动后看到在binlog文件目录中看到log文件

💡Mysql的binlog日志三种格式:
Canal默认选择的是ROW
- STATEMENT:基于SQL语句的复制(statement-based replication, SBR)
- ROW:基于行的复制(row-based replication, RBR)
- MIXED:混合模式复制(mixed-based replication, MBR)

官网下载地址:Release v1.1.7 · alibaba/canal · GitHub
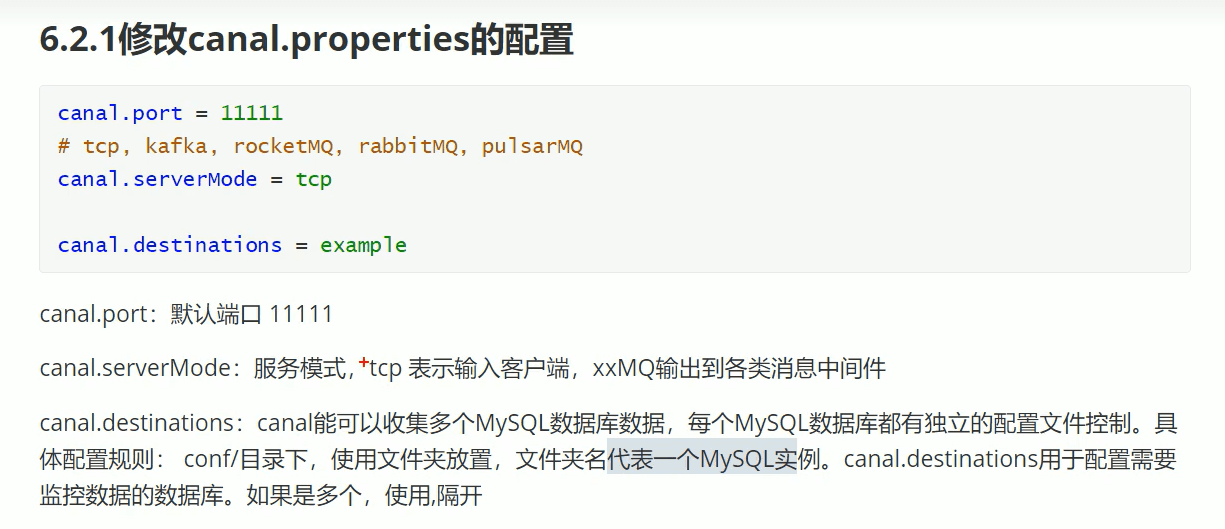
修改Mysql示例配置文件

修改连接数据库授权的用户和密码

配置好后在bin目录中执行启动命令文件

到此完成
JAVA项目整合Canal
引入依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>测试demo
public static void main(String[] args) throws InvalidProtocolBufferException {
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost", 11111), "example", "", "");
while (true) {
//2.获取连接
canalConnector.connect();
//3.指定要监控的数据库
canalConnector.subscribe("db.xiaomi.*");
//4.获取 Message
Message message = canalConnector.get(100);
List<CanalEntry.Entry> entries = message.getEntries();
if (entries.size() <= 0) {
System.out.println("没有数据,休息一会");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
for (CanalEntry.Entry entry : entries) {
// 获取表名
String tableName = entry.getHeader().getTableName();
// Entry 类型
CanalEntry.EntryType entryType = entry.getEntryType();
// 判断 entryType 是否为 ROWDATA
if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
// 序列化数据
ByteString storeValue = entry.getStoreValue();
// 反序列化
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
// 获取事件类型
CanalEntry.EventType eventType = rowChange.getEventType();
// 获取具体的数据
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
// 遍历并打印数据
for (CanalEntry.RowData rowData : rowDatasList) {
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
Map<String, Object> bMap = new HashMap<>();
for (CanalEntry.Column column : beforeColumnsList) {
bMap.put(column.getName(), column.getValue());
}
Map<String, Object> afMap = new HashMap<>();
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
afMap.put(column.getName(), column.getValue());
}
System.out.println("表名:" + tableName + ",操作类型:" + eventType);
System.out.println("改前:" + bMap);
System.out.println("改后:" + afMap);
}
}
}
}
}
}JAVA项目整合RabbitMQ
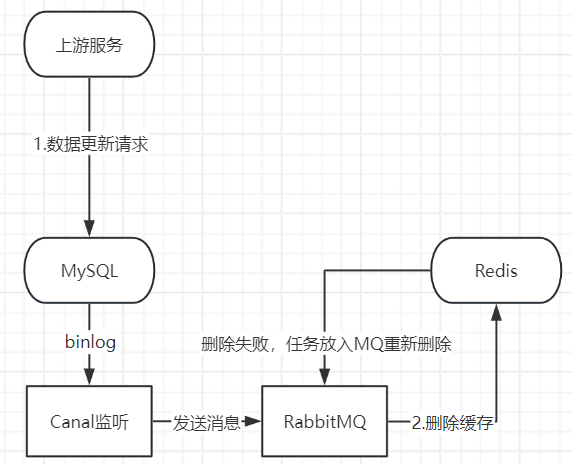
⭐最终解决思路
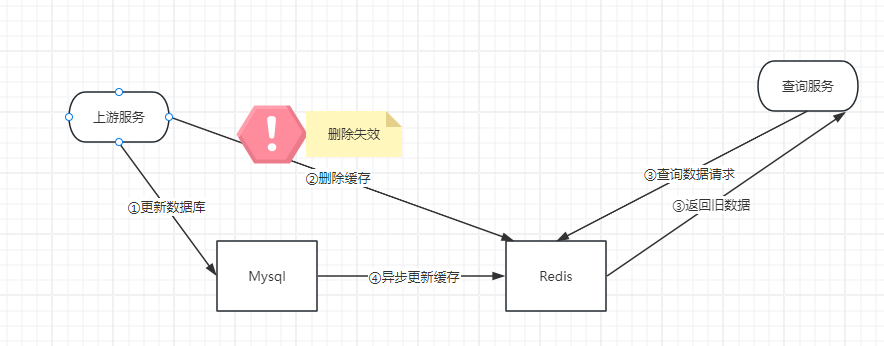
即先更新数据库,然后在删除缓存,更新数据库后通过Canal拉去MySQL的binlog日志,将更新消息放入MQ,由MQ异步执行删除操作。
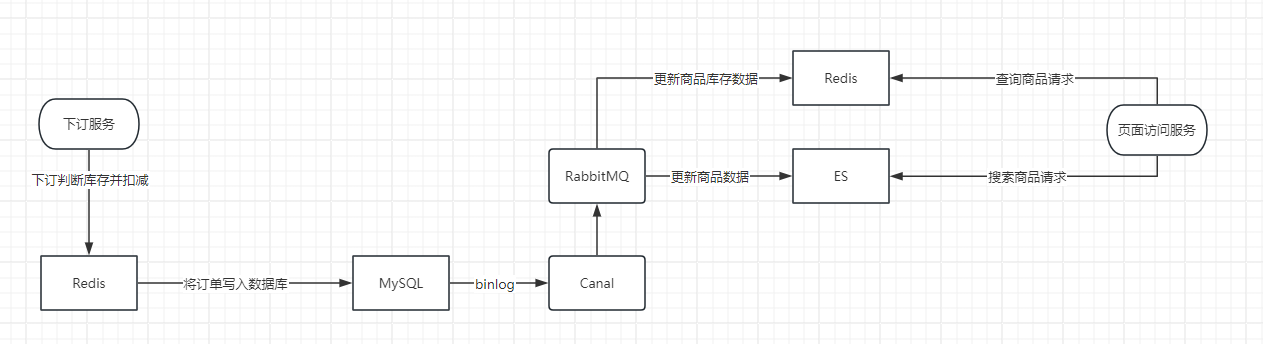
业务思路:
在下订后将库存数据库更新,根据商品的id值进行更新缓存和es;
业务思路图
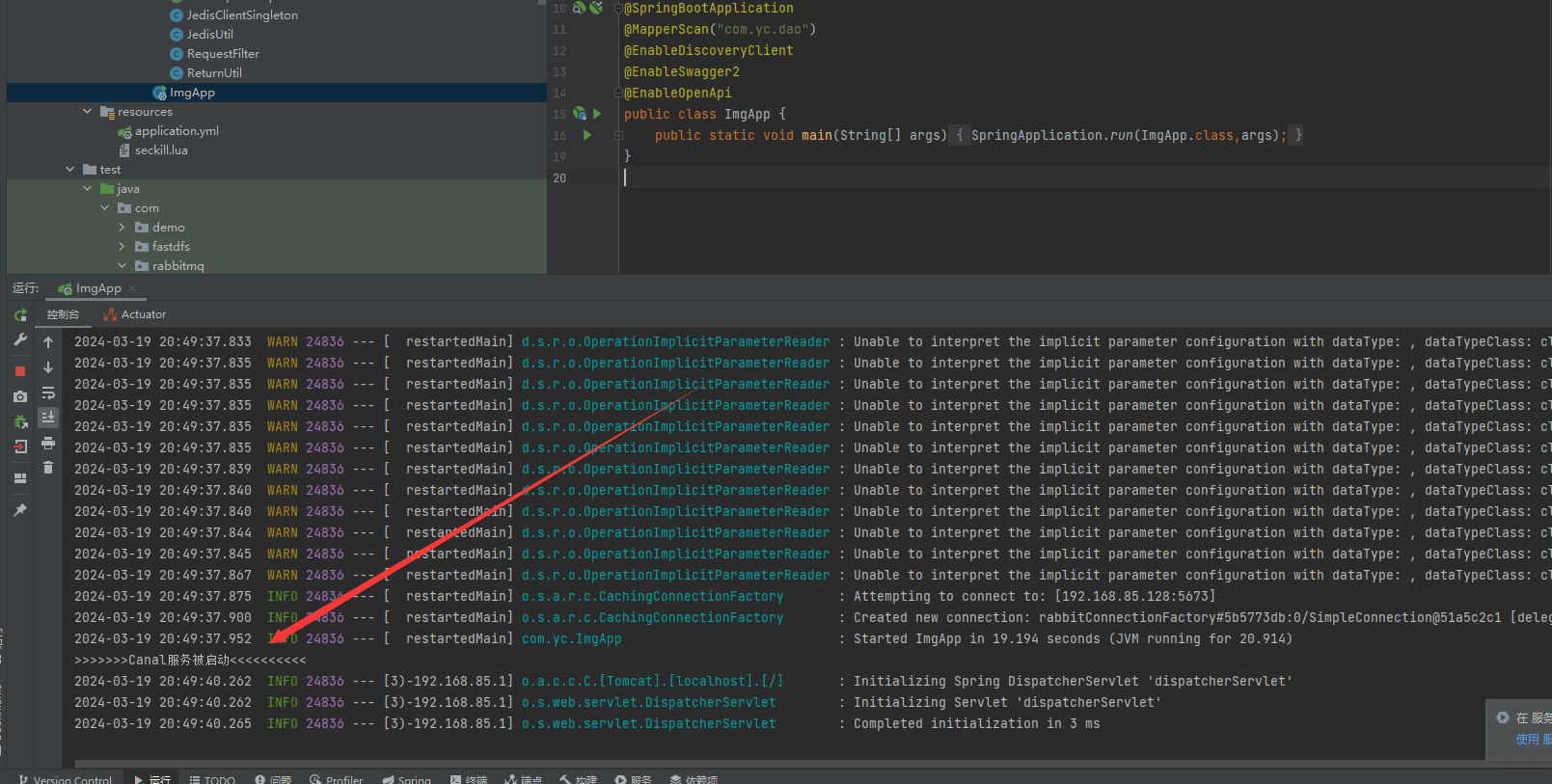
⭐具体实现
那么Canal类的代码如上图所示,因为他是监听功能,那么就要一直启动保持运行,目前是将Canal类放在页面访问服务实例中,那么在SpringBoot的Application启动时应该也要将Canal启动。Spring提供两种方式实现CommandLineRunner接口或@PostConstruct注解来实现。
此处以实现CommandLineRunner接口为例,只适合类似于初始化一些数据
💡此处不适合使用上面的类,应为其中使用了while(true)中写了个死循环一直运行,这样就会导致启动类启动后执行这个类而导致一直阻塞在这里。如果要使用那么应该是在一个单独的服务模块中就可以这样使用。
/**Canal监听类
* @author 12547
* @version 1.0
* @Date 2024/3/19 20:44
*/
@Component
public class CanalRunner implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println(">>>>>>>此处并不适用Canal的运行方式<<<<<<<<<<");
System.out.println(">>>>>>>应该是单独起一个线程<<<<<<<<<<");
}
}可以看到在启动SpringBoot实例后,执行了该方法。
💡bug解决
但在编写其他测试类的时候发现其一直阻塞在这里而不执行测试代码,推测其一直阻塞线程(因为有死循环)。
解决方案
将其改为异步形式执行。将其改为@Async异步执行。
⭐@Async的使用
应为Async用到线程池相关,所以先自定义一个用于异步的线程池
/** 自定义线程池 bean 用于Async异步调用
* @author 12547
* @version 1.0
* @Date 2024/3/20 15:45
*/
@Configuration
@EnableAsync
public class AsyncConfig {
/**
* 自定义线程
* @return
*/
@Bean("asyncPoll")
public ThreadPoolTaskExecutor asyncOperationExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 设置核心线程数
executor.setCorePoolSize(8);
// 设置最大线程数
executor.setMaxPoolSize(20);
// 设置队列大小
executor.setQueueCapacity(Integer.MAX_VALUE);
// 设置线程活跃时间(秒)
executor.setKeepAliveSeconds(60);
// 设置线程名前缀+分组名称
executor.setThreadNamePrefix("AsyncOperationThread-");
executor.setThreadGroupName("AsyncOperationGroup");
// 所有任务结束后关闭线程池
executor.setWaitForTasksToCompleteOnShutdown(true);
// 初始化
executor.initialize();
return executor;
}
}将Canal的运行代码改为异步执行
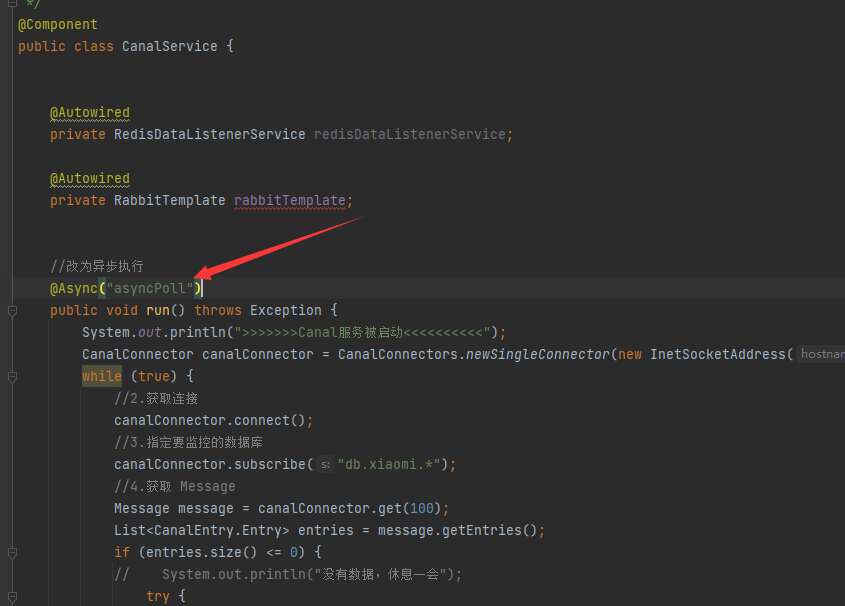
在启动类后通过调用使其异步执行即可。并经过测试后不再影响测试类的使用。
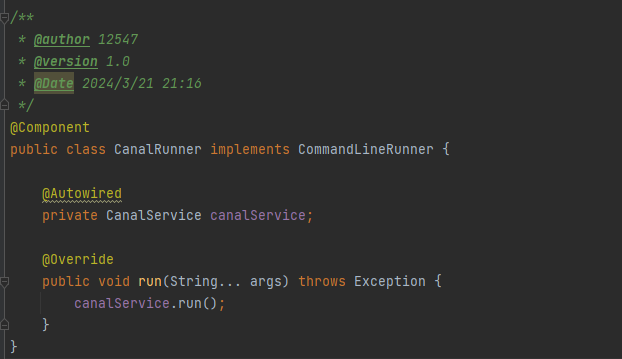
那么在Canal监听类中,当监听到数据变化后,将变化发送给MQ消息
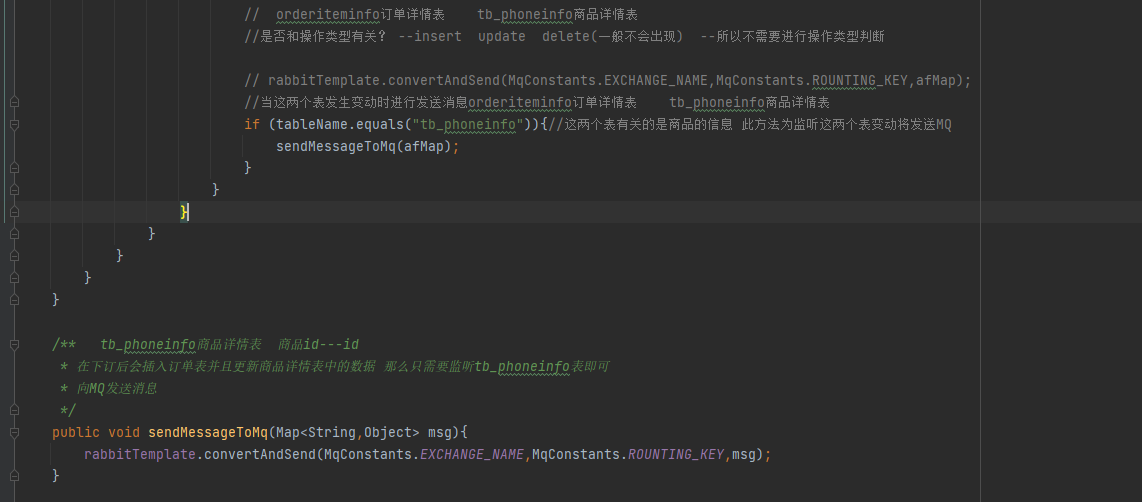
消费者监听类
/**异步数据更新Redis类
* @author 12547
* @version 1.0
* @Date 2024/3/20 15:49
*/
@Component
public class RedisDataListenerService {
@Autowired
private CacheService cacheService;
@Autowired
private StringRedisTemplate redisTemplate;
/**
* Redis数据更新消费者监听方法
*/
@RabbitListener(queues = MqConstants.QUEUE_NAME)
public void updateRedisDataByAsync(Map<String,Object> msg){
System.out.println("监听到数据变化:");
System.out.println("数据变化商品id:"+msg.get("id")); //正常情况Redis应该每个商品id一个key TODO 需要改造详情缓存查询将List<phone>改为单独的一个phone对象
redisTemplate.opsForHash().putAll(msg.get("id").toString(),msg);
System.out.println(msg.get("id").toString());
System.out.println(cacheService.getHashCache(msg.get("id").toString(), "num"));
}
}
与Redis实现数据同步基本demo到这差不多了已经,后续可以结合项目进一步优化
到此这篇关于Redis和数据库的一致性(Canal+MQ)的文章就介绍到这了,更多相关Redis和数据库一致性内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
- 使用Canal实现MySQL数据同步的完整指南
- canal实现mysql数据同步的详细过程
- 两个windows服务器使用canal实现mysql实时同步
- Canal实现MYSQL实时数据同步的示例代码
- Canal进行MySQL到MySQL数据库全量+增量同步踩坑指南
- 基于Docker结合Canal实现MySQL实时增量数据传输功能
- MySQL数据实时同步Redis的方案全解析
- 保证MySQL与Redis数据一致性的6种实现方案
- Redis与MySQL数据一致性问题的策略模式及解决方案
- 详解让MySQL和Redis数据保持一致的四种策略
- Java使用Canal同步MySQL数据到Redis
- Linux宝塔面板使用Canal实现Mysql和Redis数据同步(图文教程)
相关文章
 单节点的 Redis 并发能力有限,要进一步提高 Redis 的并发能力,就需要搭建主从集群,实现读写分离,这篇文章主要给大家介绍了Redis搭建主从集群的操作指南,需要的朋友可以参考下2023-08-08
单节点的 Redis 并发能力有限,要进一步提高 Redis 的并发能力,就需要搭建主从集群,实现读写分离,这篇文章主要给大家介绍了Redis搭建主从集群的操作指南,需要的朋友可以参考下2023-08-08 为了保证我们线上服务的并发性和安全性,目前我们的服务一般抛弃了单体应用,采用的都是扩展性很强的分布式架构,这篇文章主要介绍了使用Redis实现分布式锁的方法,需要的朋友可以参考下2022-06-06
为了保证我们线上服务的并发性和安全性,目前我们的服务一般抛弃了单体应用,采用的都是扩展性很强的分布式架构,这篇文章主要介绍了使用Redis实现分布式锁的方法,需要的朋友可以参考下2022-06-06
CentOS 7下安装 redis 3.0.6并配置集群的过程详解
这篇文章主要给大家介绍了CentOS 7下安装 redis 3.0.6并配置集群的过程,文中通过示例代码和详细的步骤介绍的很相信,对大家具有一定的参考价值,有需要的朋友们下面来一起看看吧。2017-01-01 这篇文章主要介绍了Redis教程(十一):虚拟内存介绍,本文讲解了虚拟内存简介、应用场景和配置方法等内容,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Redis教程(十一):虚拟内存介绍,本文讲解了虚拟内存简介、应用场景和配置方法等内容,需要的朋友可以参考下2015-04-04 这篇文章主要介绍了Redis 分布式锁遇到的序列化问题,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
这篇文章主要介绍了Redis 分布式锁遇到的序列化问题,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03 缓存穿透是指查询一个根本不存在的数据,由于缓存不命中,请求会穿透缓存层直接访问数据库,本文整理了6个Redis预防缓存穿透的方法,希望对大家有一定的帮助2025-04-04
缓存穿透是指查询一个根本不存在的数据,由于缓存不命中,请求会穿透缓存层直接访问数据库,本文整理了6个Redis预防缓存穿透的方法,希望对大家有一定的帮助2025-04-04
Redis02 使用Redis数据库(String类型)全面解析
这篇文章主要介绍了Redis02 使用Redis数据库(String类型)全面解析的相关资料,非常不错,具有参考借鉴价值,需要的朋友可以参考下2016-07-07 这篇文章主要介绍了Redis使用ZSET实现消息队列使用总结,本文通过实例代码给大家介绍的非常详细,需要的朋友可以参考下2023-03-03
这篇文章主要介绍了Redis使用ZSET实现消息队列使用总结,本文通过实例代码给大家介绍的非常详细,需要的朋友可以参考下2023-03-03 这篇文章主要介绍了kubernetes环境部署单节点redis数据库的方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01
这篇文章主要介绍了kubernetes环境部署单节点redis数据库的方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01
Redis报错“NOAUTH Authentication required”两种解决方案
Redis提供了一个命令行工具redis-cli,它允许你直接连接到Redis服务器,如果你知道Redis服务器的密码,你可以在连接时直接提供它,本文给大家介绍连接了Redis报错“NOAUTH Authentication required”两种解决方案2024-05-05










最新评论