
redis的常见用法和问题之缓存击穿、缓存穿透、缓存雪崩详解
本文为总结用于复习和查询
包含redis的常用操作和缓存相关问题
Redis定义
Redis存储的是key-value结构的数据,key生成字符串类型。
Redis的value的常用数据类型
字符串string
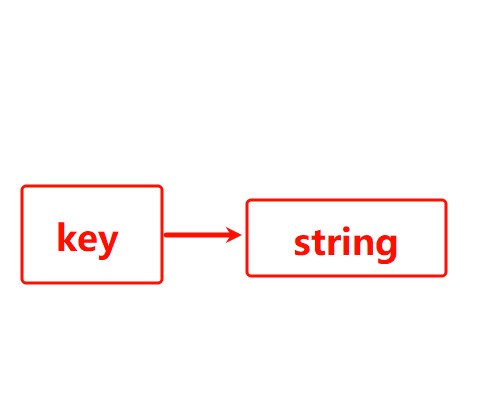
哈希hash:类似于java中的HashMap结构
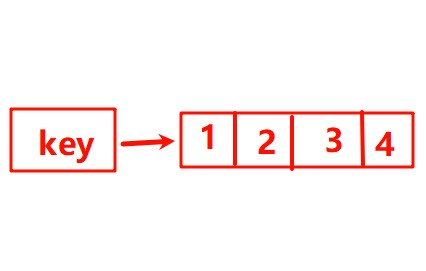
列表list:按照插入顺序排序,可以有重复元素,类似java中的LinkedList
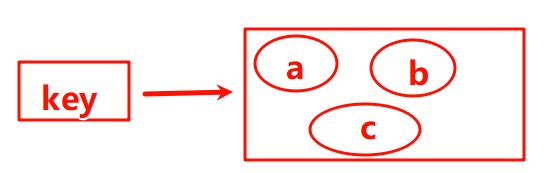
集合set:无序集合,没有重复元素,类似java中的HashSet
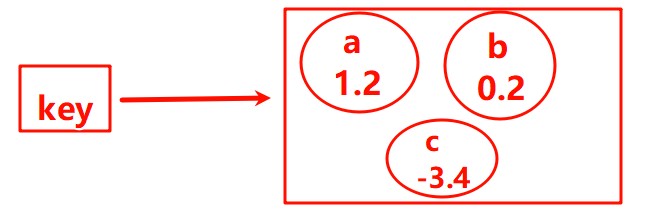
有序集合sorted set / zset:集合中每个元素关联一个score,根据score升序排列,没有重复元素。




Redis常用命令
通用命令
- keys pattern 查找所有符合给定模式pattern的key
- exists key 检查给定的key是否存在(返回1表示键存在,返回0表示键不存在)
- type key 返回指定key所存储的值的类型
- del key 用于在key存在是删除key
字符串操作命令
- set key value 设置指定key的值为value
- get key 获取指定key的值
- setex key seconds value 设置指定key的值,并将key的过期时间设置为seconds秒
- setnx key value 只有在key不存在时设置key的值
哈希操作命令
- hset key field value 将哈希表key中的字段field设为value
- hget key field 获取存储在哈希表key中的field字段的值
- hdel key field 删除存储在哈希表中的指定字段
- hkeys key 获取哈希表key中的所有字段
- hvals key 获取哈希表key中所有值
列表操作命令
- lpush/rpush key value1 [value2] 将一个或多个值插入到列表的头部/尾部
- lpop/rpop key 移除并获取列表头部/尾部元素
- lrange key start stop 获取列表指定范围内的元素
- start:区间起始位置(从 0 开始计数)。支持负数,表示从列表末尾倒数(例如 -1 表示最后一个元素)。
- stop:区间结束位置(包含在内)。同样支持负数。
- lrange mylist 0 -1 返回所有元素,等同于
- llen key 获取列表的长度
- lindex key index 用于获取列表key中指定索引位置index的元素
- lrem key count value 用于从列表key中移除元素的命令。该命令根据指定的值和数量,从列表的头部或尾部开始移除匹配的元素。
count:移除元素的数量,具体含义如下:
- count > 0:从列表头部开始,移除最多count个与value相等的元素。
- count < 0:从列表尾部开始,移除最多count的绝对值个与value相等的元素。
- count = 0:移除列表中所有与value相等的元素。
value:要移除的元素值。
集合操作命令
- sadd key member1 [member2] 向集合key添加一个或多个成员
- smembers key 获取集合key中的所有成员
- scard key 获取集合key中的成员的数量
- sinter key1 [key2] 返回给定所有集合的交集
- sunion key1 [key2] 返回给定所有集合的并集
- srem key member1 [member2] 删除集合key中的一个或多个成员
有序集合操作命令
- zadd key score 1 member1 [score2 member2] 向有序集合添加一个或多个成员
- zrange key start stop [withscores] 返回指定区间的成员,加上withscores显示成员对应的score
- zincrby key increment member 给有序集合key中指定成员的分数加increment
- zrem key member1 [member2…] 移除有序集合中的一个或多个成员
缓存穿透问题解决方案
什么是缓存穿透:指客户端请求的数据在缓存redis中和数据库中都不存在,导致大量请求到数据库,从而导致数据库压力骤增
解决方案
缓存空对象:对数据库查询结果为空的请求,返回空值,并缓存null到redis且设置ttl,即key:null
需设置好ttl,避免长期占用内存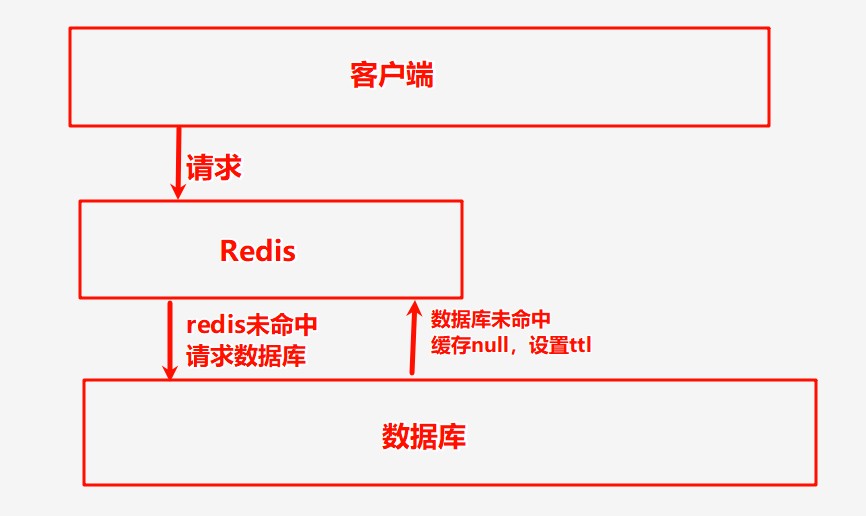
布隆过滤器:在缓存之前加一层布隆过滤器,预先将数据库中所有存在的 key 加载到布隆过滤器中。
什么是布隆过滤器过滤器:布隆过滤器是一种空间效率极高的概率型数据结构,用于判断一个元素是否存在于一个集合中。
核心特点:
高效省空间:相比哈希表,它用位数组 + 多个哈希函数实现,占用内存极小,适合海量数据场景。
概率性结果:
不存在则一定不存在(100% 准确);
存在则可能存在(有一定误判率,无法完全避免)。
不支持删除:元素加入后无法移除,否则会影响其他元素的判断(部分变种支持删除,但复杂度高)。
工作原理:
初始化一个长度为 m 的位数组,所有位初始化为 0;
选取 k 个独立的哈希函数;
添加元素:将元素通过 k 个哈希函数计算出 k 个索引,把位数组对应索引的位设为 1;
查询元素:将元素通过 k 个哈希函数计算索引,若所有对应位都是 1,则判断 “可能存在”;只要有一个位是 0,则判断 “一定不存在”。

拦截流程:
客户端发起请求,先经过布隆过滤器判断 key 是否存在; 若布隆过滤器判断 key 不存在 → 直接返回空结果,不访问缓存和数据库; 若布隆过滤器判断 key 可能存在 → 再走正常流程:查缓存 → 缓存未命中查数据库 → 数据库查到则回写缓存。
使用布隆过滤器的注意事项:
- 误判率处理:
布隆过滤器的误判会导致 “不存在的 key 被判断为可能存在”,此时请求仍会打到数据库,但这种情况概率低,且可以通过调整位数组长度 len 和哈希函数个数 k 降低误判率(len越大、k 适中,误判率越低)。 - 数据同步:
当数据库中新增 / 删除 key 时,需要同步更新布隆过滤器(删除操作需注意布隆过滤器不支持直接删除的问题,可通过定时重建布隆过滤器解决)。 - 适用场景:
适合海量数据、key 不常变动、可以容忍低误判率的场景(如:电商商品 ID、用户 ID 过滤)。
缓存击穿问题解决方案
什么是缓存击穿:指高并发场景下,某个热点数据的缓存突然失效(例如过期),导致大量请求直接穿透缓存层,直接请求到数据库,可能导致数据库短时间内承受巨大的压力。
解决方案:
- 互斥锁:当缓存失效时,只允许一个线程去查询数据库并重建缓存,其他线程等待。可以使用分布式锁(如Redis的setnx)实现互斥。
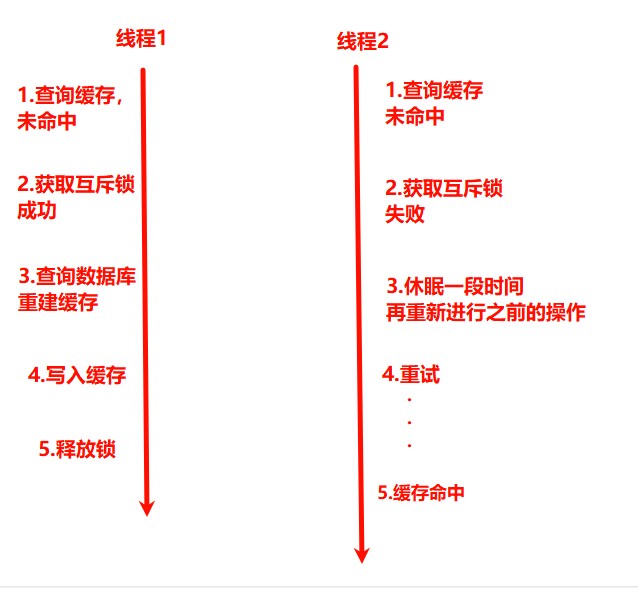

- 优点:没有额外的内存消耗;保证了一致性;实现简单;
- 缺点:线程需要等待;可能死锁
- 逻辑过期:为热点数据设置逻辑过期时间,而非物理过期。缓存本身不主动失效,但在缓存中存储一个过期时间字段。当发现数据过期时,异步触发缓存更新。
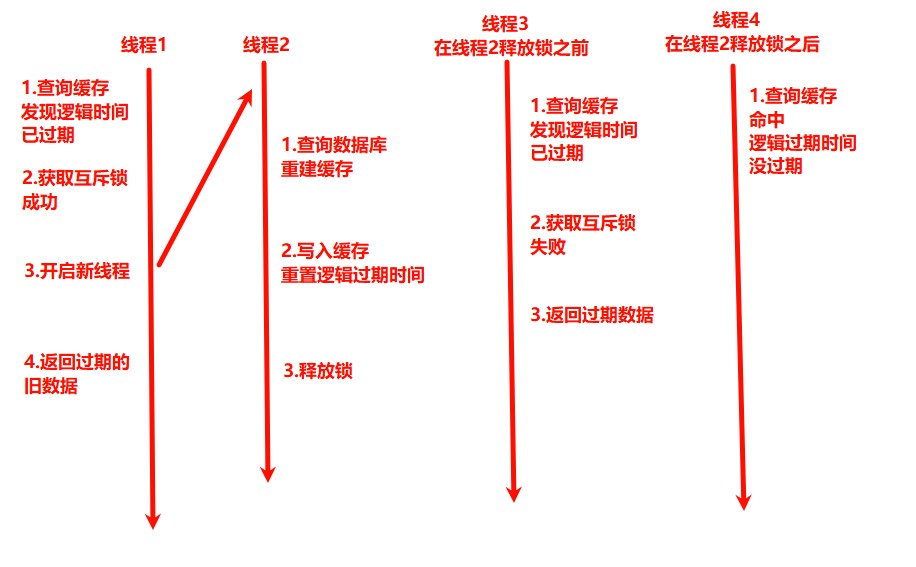

- 优点:线程无需等待,性能较好
- 缺点:不能保证一致性;有额外的内存消耗;实现较复杂
缓存雪崩问题解决方案
什么是缓存雪崩:指缓存系统在某一时刻出现大规模失效或宕机,导致大量请求直接涌向数据库,引发系统性能急剧下降甚至崩溃的现象。
解决方案:
- 给不同的key的ttl设置随机值
- 部署 Redis 集群或哨兵模式,确保单点故障时自动切换
- 给业务添加多级缓存
- 给缓存业务添加降级限流策略
BitMap
什么是BitMap:Bitmap是Redis中一种特殊的数据结构,基于字符串类型实现,但每个位可以单独操作。适用于需要高效存储和操作大量布尔值的场景。最大上限是512M,转换成bit是2^32个bit位
BitMap的常见用法
- setbit key offet value 向指定位置offet存入一个0或1
- getbit key offet 获取指定位置offet的bit值
- bitcount key [start end] 统计指定范围内bit为1的数量
- bitpos key bit [start] [end] 查询指定范围内第一个0或1出现的二进制位的位置
总结
到此这篇关于redis的常见用法和问题之缓存击穿、缓存穿透、缓存雪崩的文章就介绍到这了,更多相关redis缓存击穿、缓存穿透、缓存雪崩内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

springboot项目redis缓存异常实战案例详解(提供解决方案)
redis基本上是高并发场景上会用到的一个高性能的key-value数据库,属于nosql类型,一般用作于缓存,一般是结合数据库一块使用的,但是在使用的过程中可能会出现异常的问题,这篇文章主要介绍了springboot项目redis缓存异常实战案例详解(提供解决方案),需要的朋友可以参考下2025-05-05 Redis Streams是Redis 5.0引入的新功能,提供了一种类似于传统消息队列的机制,但具有更高的灵活性和可扩展性,本文给大家介绍Redis中Stream详解及应用小结,感兴趣的朋友一起看看吧2025-07-07
Redis Streams是Redis 5.0引入的新功能,提供了一种类似于传统消息队列的机制,但具有更高的灵活性和可扩展性,本文给大家介绍Redis中Stream详解及应用小结,感兴趣的朋友一起看看吧2025-07-07 在Redis的学习中,Lua脚本是一项强大的高级特性,它允许用户在Redis中执行复杂的操作,本文就来介绍一下Redis Lua,脚本的使用教程,感兴趣的可以了解一下2024-03-03
在Redis的学习中,Lua脚本是一项强大的高级特性,它允许用户在Redis中执行复杂的操作,本文就来介绍一下Redis Lua,脚本的使用教程,感兴趣的可以了解一下2024-03-03 这篇文章主要介绍了Redis中的过期策略和淘汰策略使用方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-06-06
这篇文章主要介绍了Redis中的过期策略和淘汰策略使用方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-06-06 这篇文章主要介绍了使用Redis控制表单重复提交和控制接口访问频率方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-06-06
这篇文章主要介绍了使用Redis控制表单重复提交和控制接口访问频率方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-06-06 这篇文章主要介绍了redis分布式锁的8大坑总结梳理,使用redis的分布式锁,我们首先想到的可能是setNx命令,文章围绕setNx命令展开详细的内容介绍,感兴趣的小伙伴可以参考一下2022-07-07
这篇文章主要介绍了redis分布式锁的8大坑总结梳理,使用redis的分布式锁,我们首先想到的可能是setNx命令,文章围绕setNx命令展开详细的内容介绍,感兴趣的小伙伴可以参考一下2022-07-07 Redis本地锁和分布式锁在设计目的、实现方式和应用场景上都有显著区别,下面就来介绍一下,具有一定的参考价值,感兴趣的可以了解一下2025-04-04
Redis本地锁和分布式锁在设计目的、实现方式和应用场景上都有显著区别,下面就来介绍一下,具有一定的参考价值,感兴趣的可以了解一下2025-04-04 这篇文章主要介绍了Redis+Caffeine如何构建高性能二级缓存问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-05-05
这篇文章主要介绍了Redis+Caffeine如何构建高性能二级缓存问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2025-05-05 这篇文章主要介绍了redis 实现登陆次数限制的思路详解,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了redis 实现登陆次数限制的思路详解,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-08-08 这篇文章主要为大家介绍了Redis源码与设计剖析之网络连接库详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-09-09
这篇文章主要为大家介绍了Redis源码与设计剖析之网络连接库详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-09-09










最新评论