
MySQL慢查询分析与优化全过程
摘要:慢查询是 MySQL 性能问题中最常见、影响最大的杀手。本文从慢查询日志的配置开启讲起,通过 pt-query-digest 定位 TOP 慢 SQL,结合 EXPLAIN 诊断执行计划,给出 5 个真实优化案例(从全表扫描到覆盖索引、从深分页到子查询改写),最后搭建 Prometheus + Grafana 监控体系,形成完整的慢查询优化闭环。全文包含实战命令和性能对比数据,建议收藏。
一、慢查询优化的完整闭环
慢查询优化不是一次性任务,而是一个持续迭代的 PDCA 闭环:
发现 → 定位 → 诊断 → 优化 → 验证 → 监控 → 再回到发现
MySQL 查询执行流程如下:客户端发送 SQL → 解析器解析 → 预处理器处理 → 查询优化器生成执行计划 → 查询执行引擎调用存储引擎 → 返回结果。
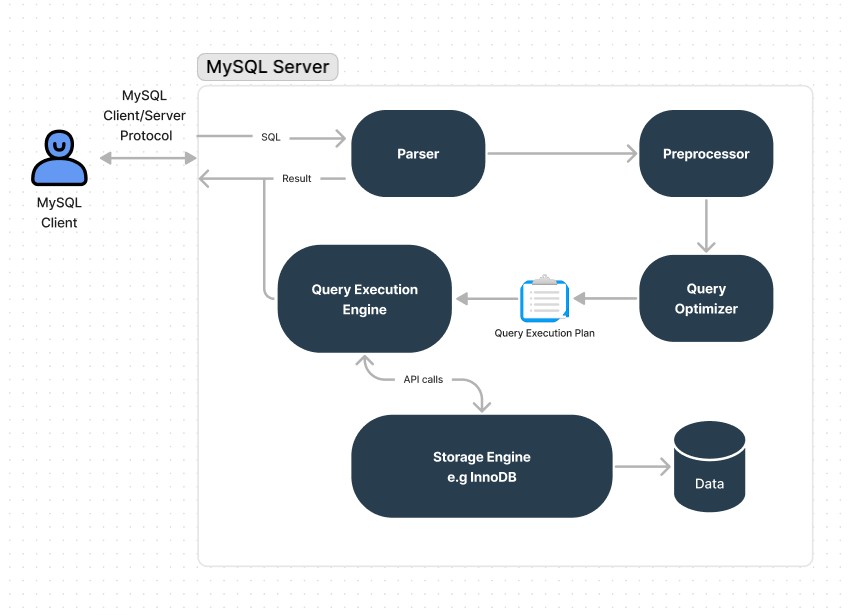
理解这个流程对诊断慢查询至关重要:优化器选择的执行计划直接决定了查询效率,而执行计划又依赖于索引统计信息和成本估算。
二、第一步:发现慢查询
2.1 开启慢查询日志(Slow Query Log)
慢查询日志是 MySQL 内置的慢 SQL 记录机制,建议生产环境必开。
-- 查看当前配置 SHOW VARIABLES LIKE 'slow_query%'; SHOW VARIABLES LIKE 'long_query_time'; -- 动态开启(无需重启,但重启后失效) SET GLOBAL slow_query_log = 'ON'; SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log'; SET GLOBAL long_query_time = 1; -- 超过 1 秒视为慢查询 -- 记录未使用索引的查询(强烈建议开启) SET GLOBAL log_queries_not_using_indexes = 'ON';
永久生效配置(my.cnf):
[mysqld] slow_query_log = 1 slow_query_log_file = /var/log/mysql/slow.log long_query_time = 1 log_queries_not_using_indexes = 1 log_output = FILE -- 或 TABLE,记录到 mysql.slow_log 表
2.2 使用 Performance Schema(MySQL 5.6+)
Performance Schema 提供更精细的语句级性能数据,无需写日志文件。
-- 开启 Statement 监控
UPDATE performance_schema.setup_consumers
SET ENABLED = 'YES' WHERE NAME LIKE '%statements%';
-- 查看耗时 TOP 10 的 SQL
SELECT
DIGEST_TEXT AS query,
COUNT_STAR AS exec_count,
ROUND(SUM_TIMER_WAIT/1000000000000, 2) AS total_latency_sec,
ROUND(AVG_TIMER_WAIT/1000000000000, 4) AS avg_latency_sec,
ROUND(MAX_TIMER_WAIT/1000000000000, 4) AS max_latency_sec
FROM performance_schema.events_statements_summary_by_digest
ORDER BY SUM_TIMER_WAIT DESC
LIMIT 10;
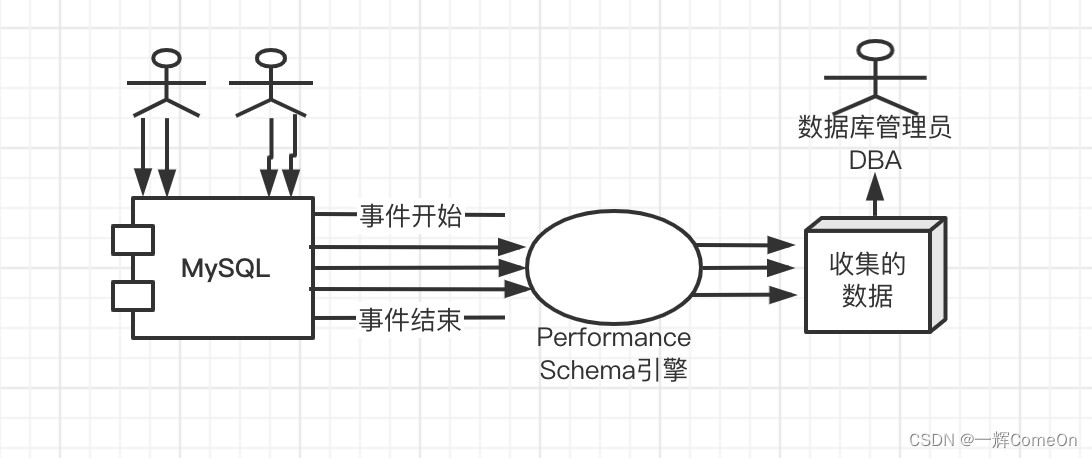
Performance Schema 的数据实时在内存中维护,适合需要即时分析的场景,但重启后数据会丢失。
2.3 使用 sys 系统库(MySQL 5.7+)
sys 库基于 Performance Schema 提供了更友好的视图:
-- 查看全表扫描次数最多的 SQL SELECT * FROM sys.statements_with_full_table_scans ORDER BY rows_examined DESC LIMIT 10; -- 查看执行次数最多且平均耗时高的 SQL SELECT * FROM sys.statements_with_runtimes_in_95th_percentile; -- 查看使用临时表和文件排序的 SQL SELECT * FROM sys.statements_with_sorting ORDER BY rows_sorted DESC LIMIT 10;
三、第二步:定位 TOP 慢 SQL
3.1 pt-query-digest:慢日志分析神器
pt-query-digest 是 Percona Toolkit 中的慢查询分析工具,能将混乱的慢日志整理成清晰的排名报告。
安装:
# Ubuntu/Debian apt-get install percona-toolkit # CentOS/RHEL yum install percona-toolkit # 或下载源码包 wget https://www.percona.com/downloads/percona-toolkit/3.5.5/binary/tarball/percona-toolkit-3.5.5_x86_64.tar.gz
基本用法:
# 分析慢查询日志,输出到文件
pt-query-digest /var/log/mysql/slow.log > slow_report.txt
# 只显示前 20 条(默认按总耗时排序)
pt-query-digest --limit 20 /var/log/mysql/slow.log
# 过滤只分析最近 1 小时的日志
pt-query-digest --since "1h" /var/log/mysql/slow.log
# 分析特定数据库的慢查询
pt-query-digest --filter '$event->{db} eq "mydb"' /var/log/mysql/slow.log
# 直接分析 Processlist(实时分析)
pt-query-digest --processlist h=localhost,u=root,p=password3.2 pt-query-digest 报告核心指标解读
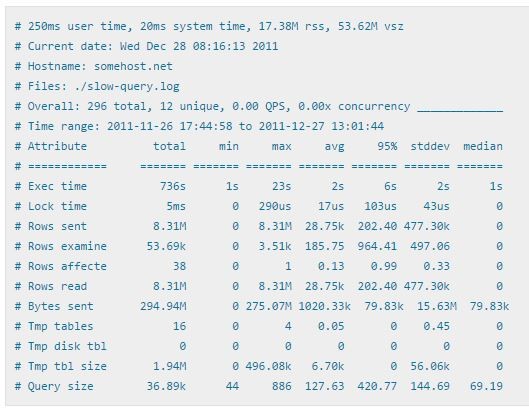
报告头部 Overall statistics 汇总了日志整体情况:
| 指标 | 含义 | 优化意义 |
|---|---|---|
| Exec time | SQL 总执行时间 | 找出时间杀手 |
| Lock time | 等待锁的时间 | 高说明有锁竞争 |
| Rows sent | 返回客户端的行数 | 高说明可能 SELECT * |
| Rows examine | 扫描的行数 | 对比 Rows sent,比值越大效率越低 |
| Rows affected | 变更的行数 | DML 语句的影响面 |
| Tmp tables | 创建临时表次数 | 高说明需要优化 GROUP BY / ORDER BY |
| Tmp disk tbl | 磁盘临时表次数 | 高说明内存不足,性能急剧下降 |
排名部分关键字段:
| 字段 | 含义 | 判断标准 |
|---|---|---|
| Response time | 该 SQL 总耗时及占比 | 占比 > 10% 必须优化 |
| Calls | 执行次数 | 高频慢查询影响面更大 |
| R/Call | 平均每次耗时 | > 1s 必须优化,> 100ms 建议优化 |
| V/M | 响应时间方差均值比 | > 0.1 说明执行时间波动大,可能存在锁竞争 |
分析口诀:先看 Response time 占比找元凶 → 再看 Calls 确认影响面 → 最后看 R/Call 评估单次伤害。
四、第三步:诊断执行计划
找到 TOP 慢 SQL 后,用 EXPLAIN 诊断其执行计划。
4.1 EXPLAIN 关键字段速查
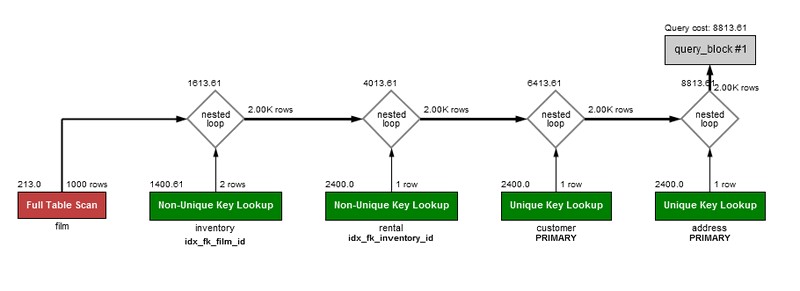
上图展示了 MySQL Workbench 的可视化执行计划,能直观看到:
- 全表扫描(Full Table Scan)的代价
- 嵌套循环连接(Nested Loop Join)的过程
- 索引查找(Key Lookup)的效率对比
核心字段诊断:
| 字段 | 正常值 | 危险值 | 优化方向 |
|---|---|---|---|
| type | ref/range/eq_ref | ALL/index | 创建/调整索引 |
| key | 有具体索引名 | NULL | 检查 WHERE 条件是否命中索引 |
| rows | 远小于表总行数 | 接近表总行数 | 增加过滤条件或优化索引 |
| Extra | Using index | Using filesort/Using temporary | 利用覆盖索引、简化排序分组 |
4.2 常见执行计划问题诊断
-- 案例:检查一个慢查询的执行计划 EXPLAIN ANALYZE SELECT o.*, u.name FROM orders o JOIN user u ON o.user_id = u.id WHERE o.status = 'pending' AND o.create_time > '2024-01-01' ORDER BY o.create_time DESC LIMIT 100;
常见问题排查:
- type = ALL:全表扫描。检查是否有合适索引、是否索引失效、是否数据量过大导致优化器放弃索引。
- Extra = Using filesort:需要额外排序。尝试将 ORDER BY 列加入索引,或利用覆盖索引避免回表后排序。
- Extra = Using temporary:需要创建临时表。常见于复杂 GROUP BY,尝试简化查询或调整 GROUP BY 顺序匹配索引。
- rows 远大于实际返回数:说明扫描了大量无效数据。检查索引选择性,或增加更精确的过滤条件。
五、第四步:优化实战
案例 1:SELECT * 导致的回表灾难
场景:订单查询页面加载缓慢,用户反馈卡顿。
-- 原始慢查询 (平均 2.3s) SELECT * FROM orders WHERE user_id = 12345 AND status = 'completed' ORDER BY create_time DESC LIMIT 10;
诊断:
EXPLAIN SELECT * FROM orders WHERE user_id = 12345 AND status = 'completed' ... -- 结果: type=ref, key=idx_user_id, rows=15000, Extra=Using where; Using filesort
问题分析:
- 索引
idx_user_id只包含user_id,过滤后仍有 15000 行 SELECT *导致回表 15000 次ORDER BY create_time需要额外排序(filesort)
优化方案:
-- 创建覆盖索引,包含 WHERE、ORDER BY、SELECT 需要的所有列 CREATE INDEX idx_user_status_time ON orders(user_id, status, create_time, order_no, amount, pay_time); -- 改写查询,只取必要字段(利用覆盖索引) SELECT order_no, amount, status, create_time, pay_time FROM orders WHERE user_id = 12345 AND status = 'completed' ORDER BY create_time DESC LIMIT 10;
优化后 EXPLAIN:
type=ref, key=idx_user_status_time, rows=120, Extra=Using index
效果:查询耗时从 2.3s → 12ms,提升 190 倍。
案例 2:深分页 LIMIT 100000, 10 的性能陷阱
场景:后台管理系统翻页到第 10000 页后,页面加载超过 5 秒。
-- 原始慢查询 (平均 4.8s) SELECT * FROM orders WHERE status = 'completed' ORDER BY create_time DESC LIMIT 100000, 10;
诊断:
type=index, key=idx_status_time, rows=100010, Extra=Using where
问题分析:MySQL 的 LIMIT 实现是「先扫描 100010 行,再丢弃前 100000 行」,越往后越慢。
优化方案 1:延迟关联(Deferred Join)
-- 先查主键,再回表取数据
SELECT o.*
FROM orders o
JOIN (
SELECT id
FROM orders
WHERE status = 'completed'
ORDER BY create_time DESC
LIMIT 100000, 10
) tmp ON o.id = tmp.id;
优化方案 2:基于游标的分页(推荐)
-- 上一页最后一条记录的 create_time 为 '2024-03-15 14:30:00' SELECT * FROM orders WHERE status = 'completed' AND create_time < '2024-03-15 14:30:00' ORDER BY create_time DESC LIMIT 10;
效果:方案 2 从 4.8s → 15ms,且性能不随页码增加而下降。
案例 3:隐式类型转换导致索引失效
场景:手机号查询接口偶发卡顿,有时 50ms,有时 3s。
-- 表结构
CREATE TABLE user (
id INT PRIMARY KEY,
phone VARCHAR(20), -- 注意是 VARCHAR
INDEX idx_phone (phone)
);
-- 原始查询(Java 代码传入 long 类型)
SELECT * FROM user WHERE phone = 13800138000;
诊断:
EXPLAIN SELECT * FROM user WHERE phone = 13800138000; -- 结果: type=ALL, key=NULL, rows=5000000
问题分析:phone 是 VARCHAR,传入数字时 MySQL 隐式将 phone 列转换为数字再比较,相当于对索引列做了函数处理,导致索引失效。
优化方案:
// 修改 Java 代码,确保传入字符串
String phone = "13800138000"; // 原来是 Long phone = 13800138000L;
jdbcTemplate.query("SELECT * FROM user WHERE phone = ?", phone);效果:查询耗时从 3s → 5ms。
案例 4:OR 条件导致的全表扫描
场景:订单搜索功能支持按订单号或手机号查询,慢查询日志中该 SQL 频繁出现。
-- 原始慢查询 (平均 1.5s) SELECT * FROM orders WHERE order_no = 'ORD2024001' OR user_phone = '13800138000';
诊断:
type=ALL, key=NULL, rows=10000000
问题分析:OR 两边条件分别适合不同索引(idx_order_no 和 idx_user_phone),但优化器选择全表扫描。
优化方案:拆分为 UNION ALL
-- 优化后查询 (平均 15ms) SELECT * FROM orders WHERE order_no = 'ORD2024001' UNION ALL SELECT * FROM orders WHERE user_phone = '13800138000' AND order_no <> 'ORD2024001'; -- 避免重复
效果:从 1.5s → 15ms,提升 100 倍。
案例 5:统计查询的索引优化与缓存策略
场景:首页 Dashboard 需要实时统计今日订单金额和数量,每刷新一次就查一次数据库。
-- 原始慢查询 (平均 800ms,并发高时更慢)
SELECT
COUNT(*) AS order_count,
SUM(amount) AS total_amount,
AVG(amount) AS avg_amount
FROM orders
WHERE create_time >= CURDATE();
诊断:
type=range, key=idx_create_time, rows=50000, Extra=Using index condition
问题分析:虽然走了索引,但扫描行数多,且是聚合计算,CPU 开销大。高并发时成为瓶颈。
优化方案 1:覆盖索引
-- 创建覆盖索引(只包含查询需要的列) CREATE INDEX idx_create_time_amount ON orders(create_time, amount); -- 查询变为覆盖索引扫描 SELECT COUNT(*), SUM(amount), AVG(amount) FROM orders WHERE create_time >= CURDATE();
优化方案 2:冗余统计表(最终采用)
-- 创建统计表
CREATE TABLE order_daily_stats (
stat_date DATE PRIMARY KEY,
order_count INT,
total_amount DECIMAL(18,2),
avg_amount DECIMAL(18,2),
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- 通过定时任务或触发器更新(每 5 分钟)
INSERT INTO order_daily_stats (stat_date, order_count, total_amount, avg_amount)
SELECT CURDATE(), COUNT(*), SUM(amount), AVG(amount)
FROM orders
WHERE create_time >= CURDATE()
ON DUPLICATE KEY UPDATE
order_count = VALUES(order_count),
total_amount = VALUES(total_amount),
avg_amount = VALUES(avg_amount);
-- 查询变为毫秒级
SELECT * FROM order_daily_stats WHERE stat_date = CURDATE();
效果:从 800ms → 2ms,且不受并发影响。
六、第五步:验证优化效果
优化后必须验证,避免引入新问题。
6.1 EXPLAIN 对比验证
-- 优化前保存执行计划 EXPLAIN SELECT ... \G -- 保存输出 -- 优化后对比 EXPLAIN SELECT ... \G -- 确认 type、rows、Extra 改善
6.2 性能测试
# 使用 mysqlslap 压测 mysqlslap --concurrency=50 --iterations=10 \ --query="SELECT order_no, amount FROM orders WHERE user_id = 12345 AND status = 'completed' ORDER BY create_time DESC LIMIT 10" \ --create-schema=mydb --delimiter=";" \ --engine=innodb --number-of-queries=1000 # 或使用 sysbench sysbench oltp_read_only --mysql-host=localhost --mysql-user=root \ --mysql-password=xxx --mysql-db=mydb --tables=10 --table-size=1000000 \ --threads=64 --time=60 --report-interval=10 run
6.3 生产灰度验证
-- 使用 MySQL 8.0 的 Query Rewrite 插件,先对部分流量生效
INSTALL PLUGIN query_rewrite SONAME 'rewriter.so';
-- 添加重写规则(先对 10% 流量生效,验证无误后再全量)
INSERT INTO query_rewrite.rewrite_rules (pattern, replacement, enabled)
VALUES (
'SELECT * FROM orders WHERE user_id = ? AND status = ? ORDER BY create_time DESC LIMIT ?',
'SELECT order_no, amount, status, create_time, pay_time FROM orders WHERE user_id = ? AND status = ? ORDER BY create_time DESC LIMIT ?',
'YES'
);
CALL query_rewrite.flush_rewrite_rules();
七、第六步:搭建监控体系
7.1 Prometheus + mysqld_exporter 监控
# docker-compose.yml
version: '3'
services:
prometheus:
image: prom/prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
mysqld_exporter:
image: prom/mysqld-exporter
environment:
- DATA_SOURCE_NAME=root:password@(mysql:3306)/
ports:
- "9104:9104"
grafana:
image: grafana/grafana
ports:
- "3000:3000"关键监控指标:
| 指标 | PromQL | 告警阈值 |
|---|---|---|
| 慢查询速率 | rate(mysql_global_status_slow_queries[5m]) | > 10/min |
| 平均查询耗时 | mysql_global_status_slow_queries / mysql_global_status_queries | > 1% |
| 全表扫描次数 | rate(mysql_global_status_select_scan[5m]) | > 100/min |
| 活跃连接数 | mysql_global_status_threads_running | > 80% max_connections |
| 锁等待时间 | mysql_global_status_innodb_row_lock_waits | > 50/min |
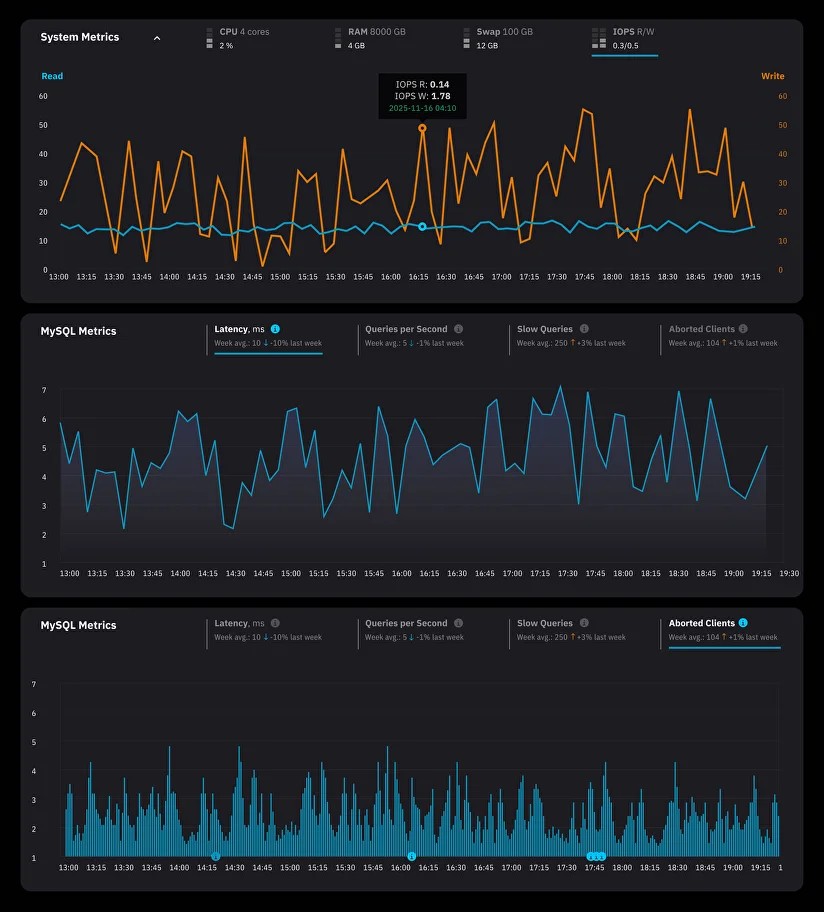
上图展示了 Grafana 中 MySQL 监控看板的典型布局,可以直观看到:
- 系统指标(CPU、内存、磁盘 IO)
- MySQL 指标(延迟、QPS、慢查询数、活跃连接数)
- 异常客户端连接预警
7.2 慢查询自动巡检脚本
#!/bin/bash
# slow_query_check.sh - 每日慢查询巡检
LOG_FILE="/var/log/mysql/slow.log"
REPORT_FILE="/tmp/slow_report_$(date +%Y%m%d).txt"
THRESHOLD=10 # 慢查询数量阈值
# 生成报告
pt-query-digest --limit 20 $LOG_FILE > $REPORT_FILE
# 提取 TOP 1 的耗时占比
TOP_PCT=$(grep -A 1 "Rank Query ID" $REPORT_FILE | head -3 | tail -1 | awk '{print $3}')
# 发送告警
if [ $(echo "$TOP_PCT > $THRESHOLD" | bc) -eq 1 ]; then
curl -X POST "https://oapi.dingtalk.com/robot/send?access_token=xxx" \
-H "Content-Type: application/json" \
-d "{"msgtype": "markdown", "markdown": {"title": "MySQL慢查询告警", "text": "### MySQL 慢查询告警\nTOP 1 慢查询占比: ${TOP_PCT}%\n请查看报告: ${REPORT_FILE}"}}"
fi
# 归档日志(可选)
mv $LOG_FILE /var/log/mysql/slow_$(date +%Y%m%d).log
mysqladmin -uroot -p flush-logs slow八、慢查询优化总结:决策矩阵
| 问题类型 | 诊断特征 | 优化手段 | 预期效果 |
|---|---|---|---|
| 全表扫描 | type=ALL, rows≈总行数 | 创建索引、调整 WHERE 条件 | 10~1000 倍提升 |
| 回表过多 | Extra=Using where, key 有值 | 覆盖索引、减少 SELECT 字段 | 5~50 倍提升 |
| 文件排序 | Extra=Using filesort | 索引包含 ORDER BY 列、利用覆盖索引 | 3~20 倍提升 |
| 深分页 | LIMIT 100000+, rows 巨大 | 延迟关联、游标分页、ES 替代 | 100~1000 倍提升 |
| 隐式转换 | key=NULL, 列类型与传入值不匹配 | 保持类型一致、代码层面修复 | 10~1000 倍提升 |
| OR 失效 | type=ALL, 多个 OR 条件 | UNION ALL 拆分、分别走索引 | 10~100 倍提升 |
| 聚合统计 | 大表 COUNT/SUM/AVG | 覆盖索引、冗余统计表、缓存 | 10~500 倍提升 |
| 锁竞争 | Lock time 高, V/M > 0.1 | 减少事务范围、调整隔离级别、优化索引 | 2~10 倍提升 |
九、面试高频考点速记
Q1:如何定位生产环境的慢查询?
- 开启 slow_query_log 和 log_queries_not_using_indexes
- 使用 pt-query-digest 分析慢日志,按 Response time 排序找 TOP SQL
- 结合 Performance Schema 的 events_statements_summary_by_digest 查看实时数据
- 使用 sys 库的 statements_with_full_table_scans 等视图快速定位问题
Q2:pt-query-digest 报告中的 V/M 是什么意思?
V/M 是响应时间的方差均值比(Variance-to-Mean ratio)。值越大说明 SQL 执行时间波动越大,可能存在锁竞争、数据分布不均或缓存命中率低的问题。V/M > 0.1 需要关注。
Q3:LIMIT 100000, 10 为什么慢?如何优化?
MySQL 的 LIMIT 实现是先扫描 offset + limit 行,再丢弃 offset 行。深分页时扫描量巨大。
优化方案:1)延迟关联先查主键再回表;2)基于上一页最后记录的游标分页(推荐);3)使用搜索引擎(ES)替代。
Q4:SELECT * 为什么不好?
- 增加网络 IO,返回无用数据;2. 无法使用覆盖索引,必须回表;3. 增加内存消耗;4. 表结构变更可能导致应用报错。应只查询需要的字段。
Q5:优化后如何验证效果?
- EXPLAIN 对比执行计划(type、rows、Extra 改善);2. mysqlslap / sysbench 压测对比 QPS/TPS;3. 生产灰度发布,观察慢查询日志和监控指标;4. 关注业务指标(页面加载时间、接口成功率)。
结语
慢查询优化是一个系统工程:从日志配置到工具分析,从执行计划诊断到 SQL 改写,从索引设计到架构调整,最后通过监控体系持续闭环。
记住三个核心原则:
- 先定位再优化:用数据说话,不要凭感觉改 SQL
- 索引是银弹但不是万能:覆盖索引能解决 80% 的查询性能问题,但深分页、聚合统计需要架构层面解决
- 监控是闭环的关键:没有监控的优化等于没优化,问题会反复出现
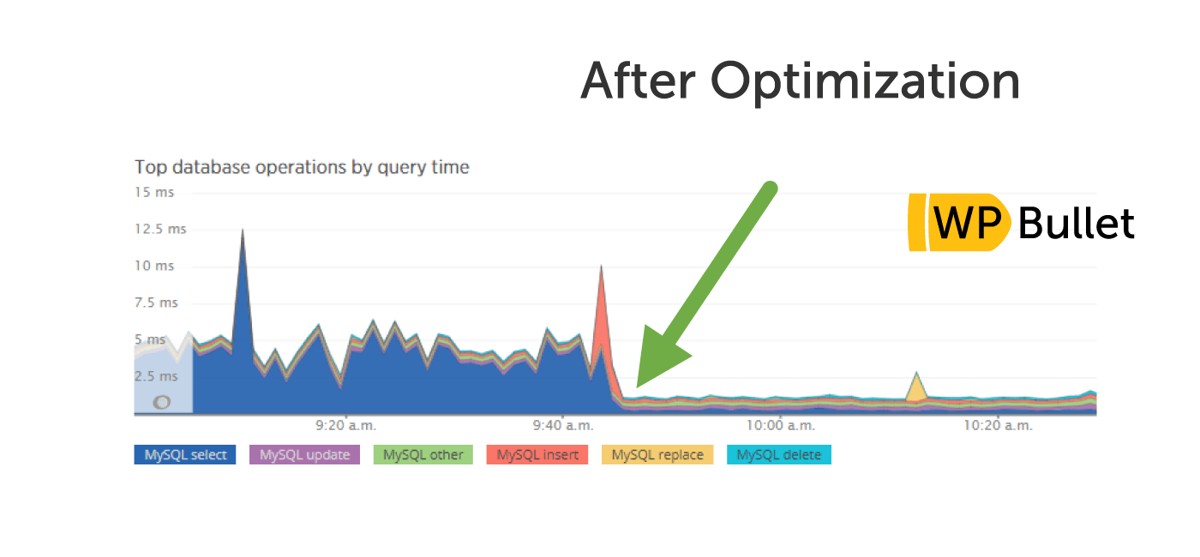
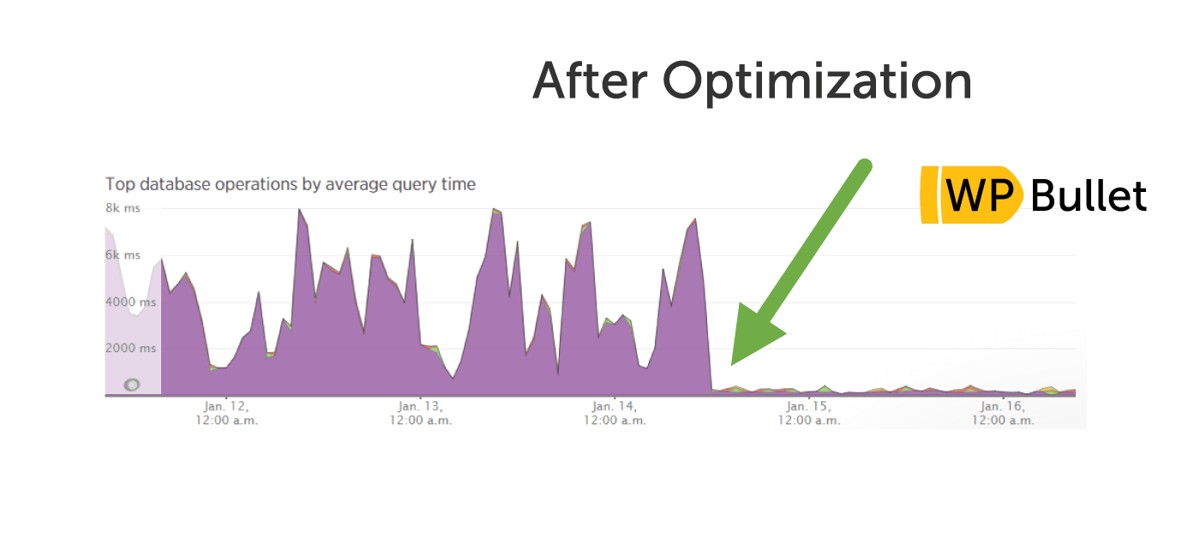
上图展示了真实的优化效果对比:优化前数据库操作耗时波动剧烈(峰值 6s+),优化后趋于平稳(<1s)。这正是慢查询优化带来的直接业务价值。
以上就是MySQL慢查询分析与优化全过程的详细内容,更多关于MySQL慢查询分析与优化的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要介绍了Mysql更新varchar存储Json数据的操作方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2023-12-12
这篇文章主要介绍了Mysql更新varchar存储Json数据的操作方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2023-12-12 MySQL 5.7.7 labs版本开始InnoDB存储引擎已经原生支持JSON格式,该格式不是简单的BLOB类似的替换。下面我们来详细探讨下吧2017-01-01
MySQL 5.7.7 labs版本开始InnoDB存储引擎已经原生支持JSON格式,该格式不是简单的BLOB类似的替换。下面我们来详细探讨下吧2017-01-01
mysql实现将date字段默认值设置为CURRENT_DATE
这篇文章主要介绍了mysql实现将date字段默认值设置为CURRENT_DATE问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-07-07 在很多时候我们并不会直接利用mysql的root用户进行项目的开发,一般我们都会创建一个具有部分权限的用户,下面这篇文章主要给大家介绍了关于如何添加一个mysql用户并给予权限的相关资料,需要的朋友可以参考下2023-03-03
在很多时候我们并不会直接利用mysql的root用户进行项目的开发,一般我们都会创建一个具有部分权限的用户,下面这篇文章主要给大家介绍了关于如何添加一个mysql用户并给予权限的相关资料,需要的朋友可以参考下2023-03-03
mysql-8.0.30压缩包版安装和配置MySQL环境过程
该文章介绍了如何在Windows系统中下载、安装和配置MySQL数据库,包括下载地址、解压文件、创建和配置my.ini文件、设置环境变量、初始化MySQL服务、启动服务以及修改root用户密码等步骤2025-01-01 数据库是指长期储存在计算机中的有组织的、可共享的数据集合,数据具有三大基本特点,永久存储,有组织,可共享,是数据库系统的核心,本文给大家分享MySQL关系型数据库基础概念,需要的朋友参考下吧2021-07-07
数据库是指长期储存在计算机中的有组织的、可共享的数据集合,数据具有三大基本特点,永久存储,有组织,可共享,是数据库系统的核心,本文给大家分享MySQL关系型数据库基础概念,需要的朋友参考下吧2021-07-07
MySQL的两种分页方式之Offset/Limit分页和游标分页详解
这篇文章主要对比了MySQL的Offset/Limit分页与游标分页,指出前者简单但存在数据漂移和性能缺陷,后者通过游标避免这些问题且更高效,建议根据业务场景选择分页方式,深度分页或动态数据宜用游标分页,而延迟联结可优化Offset/Limit性能,需要的朋友可以参考下2025-09-09 MySQL数据库事务是指一组数据库操作,要么全部执行成功,要么全部回滚。事务可以确保数据的一致性和完整性,避免了多个用户同时对同一数据进行修改所带来的问题。MySQL通过事务日志记录事务的操作,支持事务的回滚和提交等操作2023-04-04
MySQL数据库事务是指一组数据库操作,要么全部执行成功,要么全部回滚。事务可以确保数据的一致性和完整性,避免了多个用户同时对同一数据进行修改所带来的问题。MySQL通过事务日志记录事务的操作,支持事务的回滚和提交等操作2023-04-04 今天小编就为大家分享一篇关于Mysql逻辑架构详解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-01-01
今天小编就为大家分享一篇关于Mysql逻辑架构详解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-01-01 在MySQL中窗口函数是一类非常强大的函数,它们允许你在不改变表数据的情况下,对数据进行复杂的分析和计算,这篇文章主要介绍了Mysql开窗函数的相关资料,文中通过代码介绍的非常详细,需要的朋友可以参考下2025-09-09
在MySQL中窗口函数是一类非常强大的函数,它们允许你在不改变表数据的情况下,对数据进行复杂的分析和计算,这篇文章主要介绍了Mysql开窗函数的相关资料,文中通过代码介绍的非常详细,需要的朋友可以参考下2025-09-09










最新评论