
 桌面开发环境Docker Desktop 4.28-4.30.0 汉化包 中文免费版(附
桌面开发环境Docker Desktop 4.28-4.30.0 汉化包 中文免费版(附13.8MB / 06-07
 GB Studio 游戏开发工具 v4.2.2 绿色中文版
GB Studio 游戏开发工具 v4.2.2 绿色中文版123.3MB / 02-25
 程序重新打包工具 Infopulse PACE Suite Enterprise v6.0.0.30
程序重新打包工具 Infopulse PACE Suite Enterprise v6.0.0.30 180MB / 10-07
 安装程序制作工具 NSIS v3.09.0.0 中文绿色增强破解版
安装程序制作工具 NSIS v3.09.0.0 中文绿色增强破解版12.2MB / 07-08
 MassCert(数字签名工具) v2.1.1.20 官方安装版
MassCert(数字签名工具) v2.1.1.20 官方安装版3.27MB / 06-30
 guinget(软件包管理软件) v0.3.0.2 免费安装版
guinget(软件包管理软件) v0.3.0.2 免费安装版4.71MB / 06-30
 ZipInstaller(压缩包安装软件) v1.21 绿色免费版
ZipInstaller(压缩包安装软件) v1.21 绿色免费版96.3KB / 06-27
 NSIS插件教程合集 2023.06.14 免费版
NSIS插件教程合集 2023.06.14 免费版342MB / 06-16
 本地容器管理工具 Podman Desktop v1.25.1 官方安装包+绿色解压
本地容器管理工具 Podman Desktop v1.25.1 官方安装包+绿色解压269MB / 02-10
 NSIS 脚本安装程序制作系统 v3.08 中文增强版(附打包教程)
NSIS 脚本安装程序制作系统 v3.08 中文增强版(附打包教程)21.8MB / 01-17










-
-

-

-

JProfiler v16.1 64位 免费版(附安装教程) 安装制作 / 177MB
-

-

-

软件安装程序制作工具(Advanced Installer Architect) v23.5 英 安装制作 / 212MB
-

Inno Setup 安装包制作软件 v6.7.1 汉化定制免费版 安装制作 / 13.94MB
-
-
GB Studio 游戏开发工具 v4.2.2 绿色中文版 安装制作 / 123.3MB







详情介绍
tesseract ocr是一款由惠普开发的图像识别类库,后面成为Open source,据说曾经的图像识别能力排名第三,为大家提供的版本是3.02.02 for windows,喜欢的朋友欢迎前来下载使用。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。 数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。 Tesseract目前已作为开源项目发布在Google Project,其项目主页在这里查看,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具。
使用方法
下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:
附录:
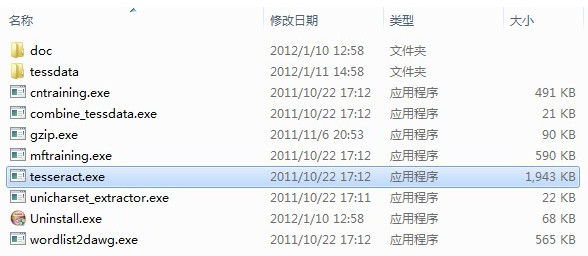
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
使用Tessract-OCR引擎识别验证码
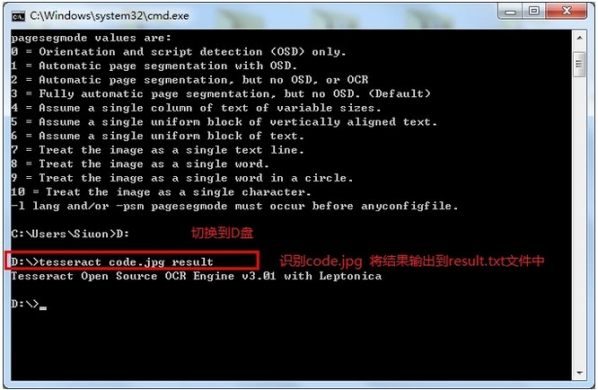
打开DOS界面,输入tesseract:
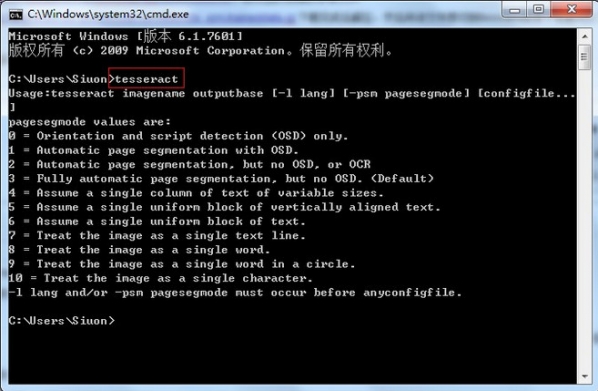
如果出现如上输出,表示安装正常。
我准备了一张验证码 放在D盘根目录下,上图:
放在D盘根目录下,上图:
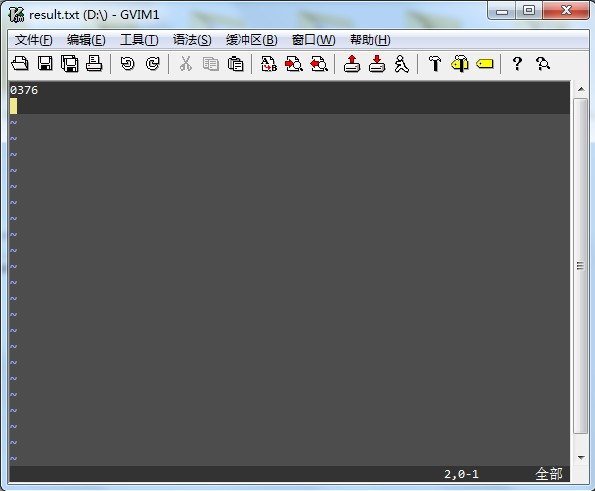
结果为:
附录:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
下载地址
人气软件
桌面开发环境Docker Desktop V4.74.0 官方正式版(附安装教程)
桌面开发环境Docker Desktop 4.28-4.30.0 汉化包 中文免费版(附
绿色单文件封装工具 3.2.3.9 中文免费绿色版
jprofiler(Java性能分析工具) v9.2.1 64位 官方免费版(附注册码)
rpg maker mz(RPG制作大师MZ) 中文破解版(附使用教程)
安装制作工具 Inno Setup v6.4.3 汉化增强安装版
JProfiler v16.1 64位 免费版(附安装教程)
脚本安装系统 Nullsoft Scriptable Install System V2.45 英文
Indigo Rose Setup Factory(安装程序制作工具) v9.5.2.0 安装特
安装程序打包工具Installshield 2021 R1 v27.0.0.58 破解版(附安






相关文章
-
桌面开发环境Docker Desktop 4.28-4.30.0 汉化包 中文免费版(附安装教程)
Docker Desktop中文版是一款支持 Windows 和 MAC 系统的完整桌面开发环境,开发人员工具,Kubernetes 以及与最新版本的 Docker 引擎,这里提供Docker Desktop汉化包下载...
-
GB Studio 游戏开发工具 v4.2.2 绿色中文版
GB Studio(GB游戏制作软件)是一款非常快速、且简单易用的拖拽式复古游戏创建器,为您最喜爱的手持式视频游戏系统提供了一个快速、简单的拖拽式复古游戏创建器,欢迎需要此...
-
程序重新打包工具 Infopulse PACE Suite Enterprise v6.0.0.30 免费安装版
Infopulse PACE Suite Enterprise是一种智能、简单的应用程序包装工具,具有许多应用程序包装任务的特点,它提供了创建软件包和管理未来更新的必要工具,直观的界面和一些有用...
-
安装程序制作工具 NSIS v3.09.0.0 中文绿色增强破解版
NSIS中文绿色增强破解版是一款免费的安装程序制作工具,提供脚本语言支持变量,函数,字串处理支持,为安装程序所单独设计提供了安装,卸载,系统设置,文件解压缩等功能.Nullsoft...
-
MassCert(数字签名工具) v2.1.1.20 官方安装版
MassCert是一款专业可靠的数字签名软件,功能包括自动验证执行命名、时间戳设计、使用SignTool自动批量签名等,可以帮助用户快速完成数字签名...
-
guinget(软件包管理软件) v0.3.0.2 免费安装版
guinget是一款软件包管理器,适用于Windows系统,功能上有点像Synaptic,但两者并没有关系,软件对与刚接触的用户而言上手难度会比较大,不过工作原理以及使用方式与Synapt...
下载声明
☉ 解压密码:www.jb51.net 就是本站主域名,希望大家看清楚,[ 分享码的获取方法 ]可以参考这篇文章
☉ 推荐使用 [ 迅雷 ] 下载,使用 [ WinRAR v5 ] 以上版本解压本站软件。
☉ 如果这个软件总是不能下载的请在评论中留言,我们会尽快修复,谢谢!
☉ 下载本站资源,如果服务器暂不能下载请过一段时间重试!或者多试试几个下载地址
☉ 如果遇到什么问题,请评论留言,我们定会解决问题,谢谢大家支持!
☉ 本站提供的一些商业软件是供学习研究之用,如用于商业用途,请购买正版。
☉ 本站提供的tesseract ocr(图像识别类库) v4.0.0.20181030 官方安装免费版资源来源互联网,版权归该下载资源的合法拥有者所有。