
Spark SQL 2.4.8 操作 Dataframe的两种方式
一、测试数据
7369,SMITH,CLERK,7902,1980/12/17,800,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,20
7839,KING,PRESIDENT,1981/11/17,5000,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,20
7900,JAMES,CLERK,7698,1981/12/3,9500,30
7902,FORD,ANALYST,7566,1981/12/3,3000,20
7934,MILLER,CLERK,7782,1982/1/23,1300,10
二、创建DataFrame
方式一:DSL方式操作
- 实例化SparkContext和SparkSession对象
- 利用StructType类型构建schema,用于定义数据的结构信息
- 通过SparkContext对象读取文件,生成RDD
- 将RDD[String]转换成RDD[Row]
- 通过SparkSession对象创建dataframe
- 完整代码如下:
package com.scala.demo.sql
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
object Demo01 {
def main(args: Array[String]): Unit = {
// 1.创建SparkContext和SparkSession对象
val sc = new SparkContext(new SparkConf().setAppName("Demo01").setMaster("local[2]"))
val sparkSession = SparkSession.builder().getOrCreate()
// 2. 使用StructType来定义Schema
val mySchema = StructType(List(
StructField("empno", DataTypes.IntegerType, false),
StructField("ename", DataTypes.StringType, false),
StructField("job", DataTypes.StringType, false),
StructField("mgr", DataTypes.StringType, false),
StructField("hiredate", DataTypes.StringType, false),
StructField("sal", DataTypes.IntegerType, false),
StructField("comm", DataTypes.StringType, false),
StructField("deptno", DataTypes.IntegerType, false)
))
// 3. 读取数据
val empRDD = sc.textFile("file:///D:\\TestDatas\\emp.csv")
// 4. 将其映射成ROW对象
val rowRDD = empRDD.map(line => {
val strings = line.split(",")
Row(strings(0).toInt, strings(1), strings(2), strings(3), strings(4), strings(5).toInt,strings(6), strings(7).toInt)
})
// 5. 创建DataFrame
val dataFrame = sparkSession.createDataFrame(rowRDD, mySchema)
// 6. 展示内容 DSL
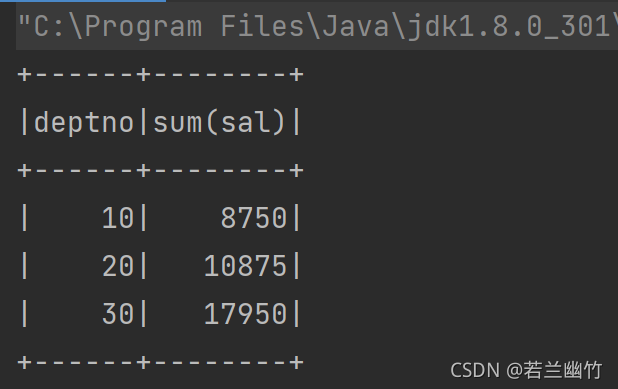
dataFrame.groupBy("deptno").sum("sal").as("result").sort("sum(sal)").show()
}
}
结果如下:
方式二:SQL方式操作
- 实例化SparkContext和SparkSession对象
- 创建case class Emp样例类,用于定义数据的结构信息
- 通过SparkContext对象读取文件,生成RDD[String]
- 将RDD[String]转换成RDD[Emp]
- 引入spark隐式转换函数(必须引入)
- 将RDD[Emp]转换成DataFrame
- 将DataFrame注册成一张视图或者临时表
- 通过调用SparkSession对象的sql函数,编写sql语句
- 停止资源
- 具体代码如下:
package com.scala.demo.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
// 0. 数据分析
// 7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
// 1. 定义Emp样例类
case class Emp(empNo:Int,empName:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptNo:Int)
object Demo02 {
def main(args: Array[String]): Unit = {
// 2. 读取数据将其映射成Row对象
val sc = new SparkContext(new SparkConf().setMaster("local[2]").setAppName("Demo02"))
val mapRdd = sc.textFile("file:///D:\\TestDatas\\emp.csv")
.map(_.split(","))
val rowRDD:RDD[Emp] = mapRdd.map(line => Emp(line(0).toInt, line(1), line(2), line(3), line(4), line(5).toInt, line(6), line(7).toInt))
// 3。创建dataframe
val spark = SparkSession.builder().getOrCreate()
// 引入spark隐式转换函数
import spark.implicits._
// 将RDD转成Dataframe
val dataFrame = rowRDD.toDF
// 4.2 sql语句操作
// 1、将dataframe注册成一张临时表
dataFrame.createOrReplaceTempView("emp")
// 2. 编写sql语句进行操作
spark.sql("select deptNo,sum(sal) as total from emp group by deptNo order by total desc").show()
// 关闭资源
spark.stop()
sc.stop()
}
}
结果如下:

到此这篇关于Spark SQL 2.4.8 操作 Dataframe的两种方式的文章就介绍到这了,更多相关Spark SQL 操作 Dataframe内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 查询语句大家用的很多,但是知道语句执行的顺序和各各阶段的作用的人却很少。这里给大家简单介绍一下2011-10-10
查询语句大家用的很多,但是知道语句执行的顺序和各各阶段的作用的人却很少。这里给大家简单介绍一下2011-10-10 在SQL Server中可以使用dtexec命令运行SSIS包(2005以上版本),当然也可以通过系统过程:xp_cmdshell调用dtexec运行SSIS包2013-09-09
在SQL Server中可以使用dtexec命令运行SSIS包(2005以上版本),当然也可以通过系统过程:xp_cmdshell调用dtexec运行SSIS包2013-09-09
SQLServer2016 sa登录失败(错误代码18456)
18456错误是因密码或用户名错误而使身份验证失败并导致连接尝试被拒或者账户被锁定无法sa登录,本文就来介绍一下解决方法,感兴趣的可以了解一下2023-09-09 MSSQL经典语句...2006-10-10
MSSQL经典语句...2006-10-10 这篇文章主要介绍了使用SQL语句将相同名的多行字段内容拼接起来,可以使用GROUP_CONCAT函数来实现相同名称的多行字段内容拼接,本文给大家介绍的非常详细,需要的朋友可以参考下2023-05-05
这篇文章主要介绍了使用SQL语句将相同名的多行字段内容拼接起来,可以使用GROUP_CONCAT函数来实现相同名称的多行字段内容拼接,本文给大家介绍的非常详细,需要的朋友可以参考下2023-05-05 数据类型在精度,范围上有较大的差别。选择合适的类型可以减少table和index的大小,进而减少IO的开销,提高效率。本文介绍基本的数值类型及其之间的细小差别。2009-07-07
数据类型在精度,范围上有较大的差别。选择合适的类型可以减少table和index的大小,进而减少IO的开销,提高效率。本文介绍基本的数值类型及其之间的细小差别。2009-07-07 在日常的数据库管理中,数据的误删操作是难以避免的,为了确保数据的安全性和完整性,我们必须采取一些措施来进行数据的备份和恢复,本文将详细介绍如何在 SQL Server 中进行数据的备份和恢复操作,特别是在发生数据误删的情况下,需要的朋友可以参考下2024-07-07
在日常的数据库管理中,数据的误删操作是难以避免的,为了确保数据的安全性和完整性,我们必须采取一些措施来进行数据的备份和恢复,本文将详细介绍如何在 SQL Server 中进行数据的备份和恢复操作,特别是在发生数据误删的情况下,需要的朋友可以参考下2024-07-07 SQL Server中处理日期和时间的常用方法有三种:FORMAT、CONVERT和DATEADD,这篇文章主要介绍了SQL Server时间转换的3种方法,文中通过代码介绍的非常详细,需要的朋友可以参考下2024-09-09
SQL Server中处理日期和时间的常用方法有三种:FORMAT、CONVERT和DATEADD,这篇文章主要介绍了SQL Server时间转换的3种方法,文中通过代码介绍的非常详细,需要的朋友可以参考下2024-09-09 SQL SERVER 利用存储过程查看角色(服务器/数据库)和用户信息,感兴趣的朋友可以了解下,或许对你有所帮助2013-01-01
SQL SERVER 利用存储过程查看角色(服务器/数据库)和用户信息,感兴趣的朋友可以了解下,或许对你有所帮助2013-01-01 这篇文章主要介绍了SQL 在自增列插入指定数据的操作方法,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2018-05-05
这篇文章主要介绍了SQL 在自增列插入指定数据的操作方法,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2018-05-05










最新评论