
在本地部署大模型ollama的保姆级教程
发布时间:2026-05-25 11:55:45 作者:Alson_Code  我要评论
我要评论
这段文章详细介绍了Ollama、LMStudio、TextGenerationWebUI和vLLM四种部署方式,适合不同模型的本地和企业环境部署,文章还提供了Ollama的下载指南和免费开源大模型的推荐版本,适合不同硬件配置的用户,最后,介绍了SpringAI框架的项目集成方法,需要的朋友可以参考下
一、部署方式选择
| 部署方式 | 上手难度 | 核心特点 | 适用场景 |
|---|---|---|---|
| Ollama | ⭐ | 命令极简,自动适配环境,自带 API 接口 | 新手日常本地调用、快速测试 |
| LM Studio | ⭐ | 图形化操作,无需敲代码,兼容 OpenAI 接口 | 不想使用命令行、纯可视化使用 |
| Text Generation WebUI | ⭐⭐⭐ | 功能齐全,支持模型微调、多种量化格式 | 深度调试模型、个性化参数配置 |
| vLLM | ⭐⭐⭐⭐ | 推理速度快,高并发性能强 | 搭建对外服务、生产环境部署 |
大家可以按需自我选择,我的推荐是本地自己玩使用ollama,在企业使用最好用vLLM
二、ollama下载(windows电脑为例)
如果官网能下载就用官网,不能就镜像地址,懂得都懂
- 官网地址:https://ollama.com/download
- 镜像地址:https://cnb.cool/hex/ollama/-/releases/latest/download/OllamaSetup.exe
注意:后续下载模型一般都好几个G,可以在setting中设置模型下载地址
三、免费开源大模型选择
| 模型名称 | 推荐版本 | 中文友好 | 商用权限 | Ollama 下载命令 | 最低显存 | 推荐显存 | 最低内存 | 推荐内存 | 硬件适配选型 |
|---|---|---|---|---|---|---|---|---|---|
| 通义千问 Qwen | Qwen2:7b/14b | ★★★★★ | 免费可商用 | ollama run qwen2:7b ollama run qwen2:14b | 6G 10G | 8-16G 16G+ | 16G 32G | 32G 64G | 16G 内存选 7b,32G 及以上内存选 14b |
| 智谱 ChatGLM | chatglm3:6b | ★★★★★ | 免费可商用 | ollama run chatglm3:6b | 5G | 6-8G | 16G | 32G | 常规家用内存均可流畅运行 |
| Llama3 | llama3:8b | ★★★☆☆ | 个人免费商用受限 | ollama run llama3:8b | 6G | 8-16G | 16G | 32G | 16G 标准内存适配日常使用 |
| DeepSeek | deepseek:7b | ★★★★☆ | 个人免费商用受限 | ollama run deepseek:7b | 6G | 8-16G | 16G | 32G | 代码推理场景,16G 内存够用 |
| Mixtral | mixtral:8x7b | ★★★☆☆ | 免费可商用 | ollama run mixtral | 10G | 16G+ | 32G | 64G | 大内存机型专属,长文本处理优选 |
| Gemma | gemma2:9b | ★★★☆☆ | 个人免费商用受限 | ollama run gemma2:9b | 8G | 12-16G | 16G | 32G | 主流内存配置均可稳定运行 |
| Phi-3 | phi3:mini | ★★★☆☆ | 免费可商用 | ollama run phi3:mini | 3G | 4-6G | 8G | 16G | 低配小内存笔记本首选 |
我是16G内存,下载的是Qwen2:7b,直接在powershell上运行ollama run qwen2:7b
四、使用
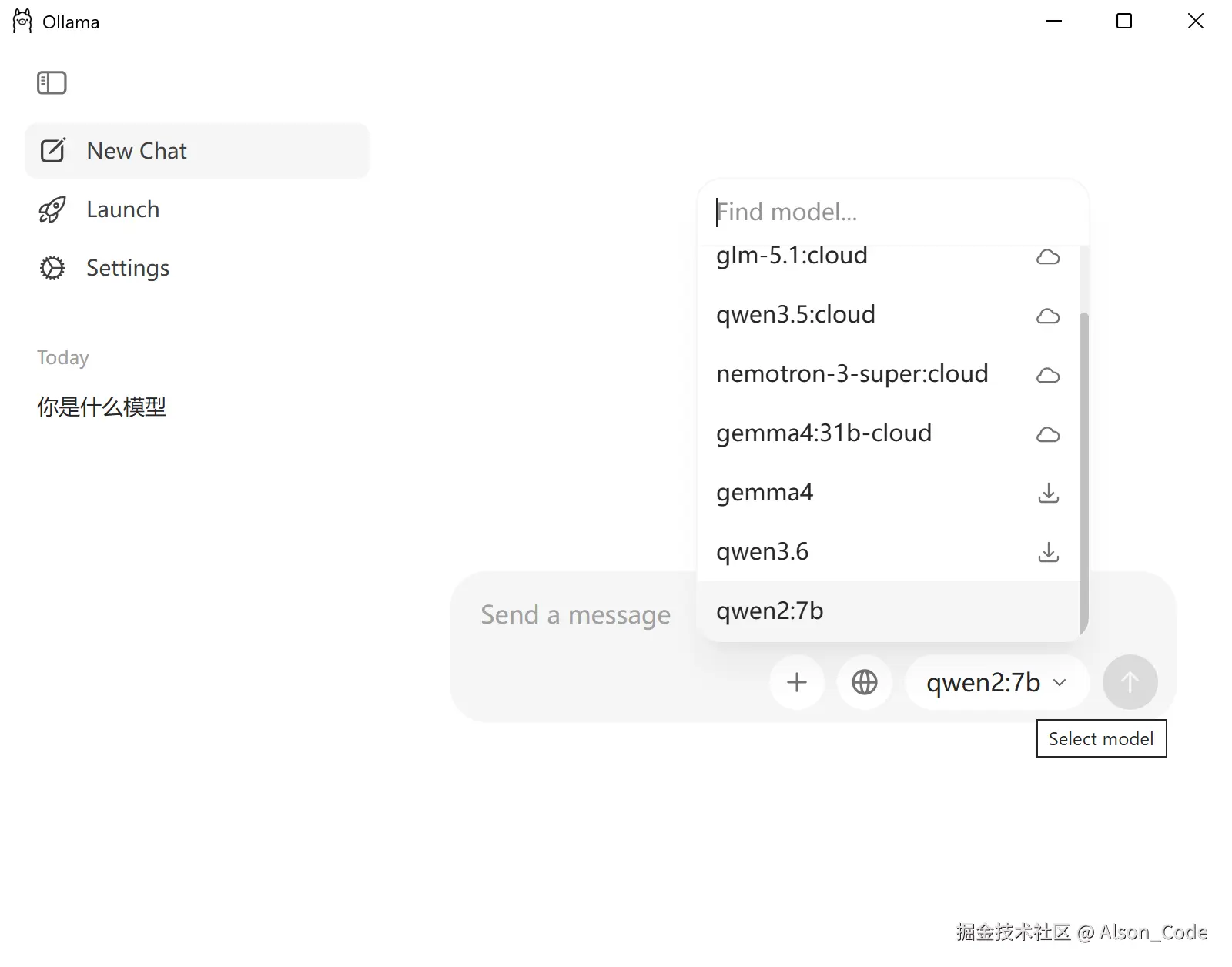
选中模型直接对话即可,就可以使用了!!!
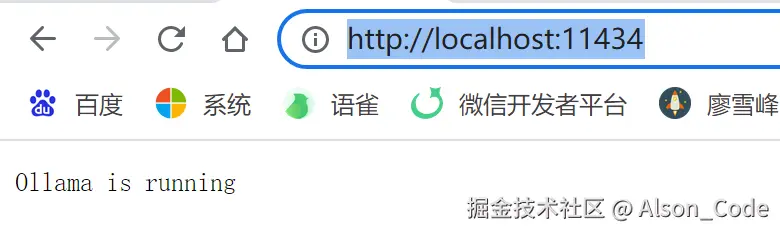
地址验证:http://localhost:11434/
五、项目集成(Spring AI框架为例)
- pom依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI Ollama 依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies>- yaml配置
spring:
application:
name: spring-ai-demo
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen2:7b- 测试运行
package com.example.springaidemo.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class AiController {
private final ChatClient chatClient;
// 自动注入 Ollama
public AiController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
// 测试接口
@GetMapping("/ai")
public String ask(String question) {
return chatClient.prompt()
.user(question)
.call()
.content();
}
}
到此这篇关于在本地部署大模型ollama的保姆级教程的文章就介绍到这了,更多相关本地部署大模型ollama内容请搜索脚本之家以前的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!
相关文章

2026最新Linux本地部署Ollama安装全流程(含离线/开机自启/远程访问)
本文记录在 CentOS 7+ / Ubuntu 20.04+ 上部署 Ollama 的实操笔记,覆盖 一键在线安装 与 离线 tar 包安装 两种方式,并补充 systemd 开机自启、qwen2 / deepseek-r1 等模2026-05-19 本文主要介绍了在Ollama平台下载和安装AI模型的方法,包括点击按钮安装和使用指令下载两种方式,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价2026-04-29
本文主要介绍了在Ollama平台下载和安装AI模型的方法,包括点击按钮安装和使用指令下载两种方式,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价2026-04-29 本文详细介绍了Ollama本地大模型运行框架的安装配置方法,特别是如何实现远程访问,文章从基础安装、配置优化、网络设置、远程访问、服务验证到常见问题解决,逐层深入,为开发2026-04-12
本文详细介绍了Ollama本地大模型运行框架的安装配置方法,特别是如何实现远程访问,文章从基础安装、配置优化、网络设置、远程访问、服务验证到常见问题解决,逐层深入,为开发2026-04-12 本文主要介绍如何在 Windows 系统快速部署 Ollama 开源大语言模型运行工具,并安装 Open WebUI 结合 cpolar 内网穿透软件,实现在公网环境也能访问你在本地内网搭建的 llam2026-04-07
本文主要介绍如何在 Windows 系统快速部署 Ollama 开源大语言模型运行工具,并安装 Open WebUI 结合 cpolar 内网穿透软件,实现在公网环境也能访问你在本地内网搭建的 llam2026-04-07 本文主要介绍如何使用ollama本地部署deepseek大模型,以及使用WebUI工具界面进行交互,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需2026-03-31
本文主要介绍如何使用ollama本地部署deepseek大模型,以及使用WebUI工具界面进行交互,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需2026-03-31 本文介绍如何通过Docker+Ollama搭建本地AI开发环境,解决云端API调用成本高、延迟大的问题,帮助开发者快速实现本地AI应用开发,无需担心API调用限制和费用问题,感兴趣的可2026-03-30
本文介绍如何通过Docker+Ollama搭建本地AI开发环境,解决云端API调用成本高、延迟大的问题,帮助开发者快速实现本地AI应用开发,无需担心API调用限制和费用问题,感兴趣的可2026-03-30






最新评论