
Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip
环境:python3.8+pycharm
库:requests,lxml
浏览器:谷歌
IP地址:http://www.xiladaili.com/gaoni/
分析网页源码:

选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath
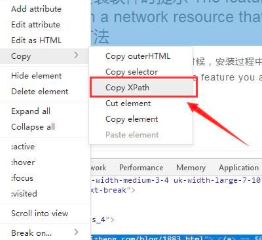
我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1]
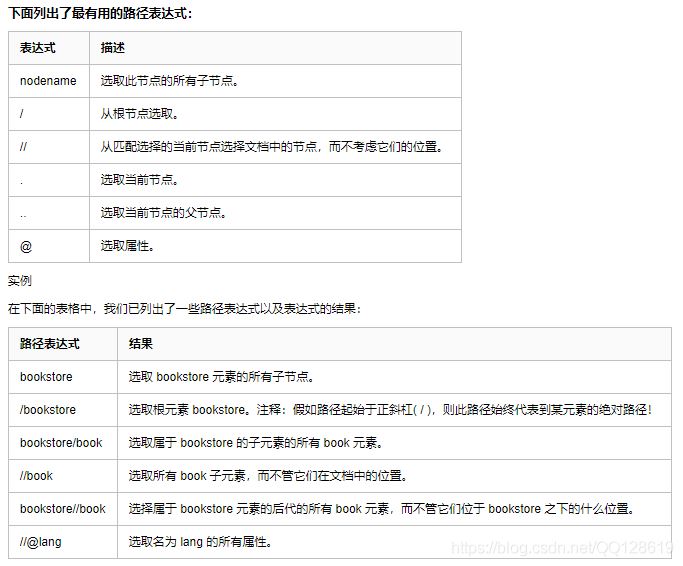
虽然可以查出来ip,但不利于程序自动爬取所有IP,利用谷歌XpathHelp测试一下

从上图可以看出,只匹配到了一个Ip,我们稍作修改,即可达到目的
,有关xpath规则,可以参考下表;


经过上面的规则学习后,我们修改为://*[@class=‘mt-0 mb-2 table-responsive']/table/tbody/tr/td[1],再利用xpthhelp工具验证一下:

这样我们就可以爬取整个页面的Ip地址了,为了方便爬取更多的IP,我们继续往下翻页,找到翻页按钮:
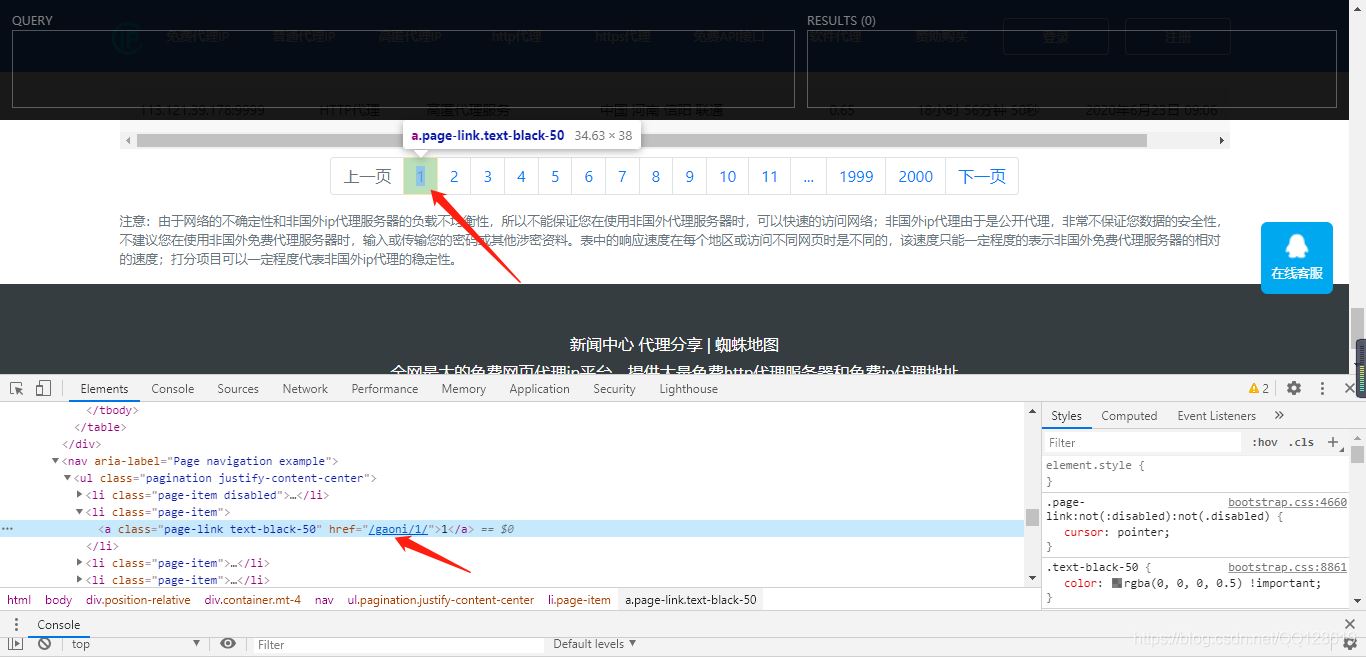
找规律,发现每翻一页,a标签下的href连接地址加1即可,python程序可以利用for循环解决翻页问题即可。
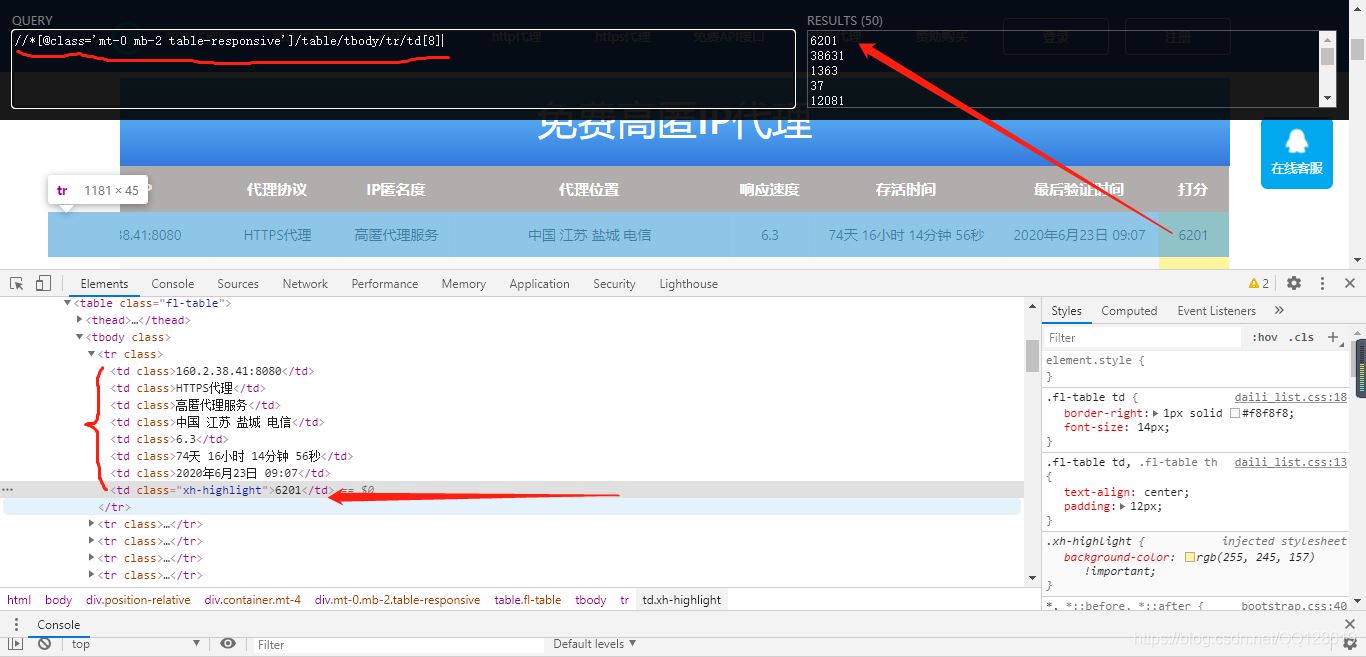
为了提高IP代理的质量,我们爬取评分高的IP来使用。找到评分栏下的Xpath路径,这里不再做详细介绍,思路参考上面找IP地址的思路,及XPath规则,过程参考下图:
Python代码实现
代码可复制粘贴直接使用,如果出现报错,修改一下cookie。这里使用代理ip爬取,防止IP被封。当然这里的代码还是基础的,有空可以写成代理池,多任务去爬。当然还可以使用其它思路去实现,这里只做入门介绍。当有了这些代理IP后,我们可以用文件保存,或者保存到数据库中,根据实际使用情况而定,这里不做保存,只放到列表变量中保存。
import requests
from lxml import etree
import time
class XiLaIp_Spider:
def __init__(self):
self.url = 'http://www.xiladaili.com/gaoni/'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'cookie': 'td_cookie=1539882751; csrftoken=lymOXQp49maLMeKXS1byEMMmsavQPtOCOUwy6WIbfMNazZW80xKKA8RW2Zuo6ssy; Hm_lvt_31dfac66a938040b9bf68ee2294f9fa9=1592547159; Hm_lvt_9bfa8deaeafc6083c5e4683d7892f23d=1592535959,1592539254,1592612217; Hm_lpvt_9bfa8deaeafc6083c5e4683d7892f23d=1592612332',
}
self.proxy = '116.196.85.150:3128'
self.proxies = {
"http": "http://%(proxy)s/" % {'proxy': self.proxy},
"https": "http://%(proxy)s/" % {'proxy': self.proxy}
}
self.list1 = []
def get_url(self):
file = open('Ip_Proxy.txt', 'a', encoding='utf-8')
ok_file = open('OkIp_Proxy.txt', 'a', encoding='utf-8')
for index in range(50):
time.sleep(3)
try:
res = requests.get(url=self.url if index == 0 else self.url + str(index) + "/", headers=self.headers,
proxies=self.proxies, timeout=10).text
except:
continue
data = etree.HTML(res).xpath("//*[@class='mt-0 mb-2 table-responsive']/table/tbody/tr/td[1]")
# '//*[@id="scroll"]/table/tbody/tr/td[1]'
score_data = etree.HTML(res).xpath("//*[@class='mt-0 mb-2 table-responsive']/table/tbody/tr/td[8]")
for i, j in zip(data, score_data):
# file.write(i.text + '\n')
score = int(j.text)
# 追加评分率大于十万的ip
if score > 100000:
self.list1.append(i.text)
set(self.list1)
file.close()
ok_ip = []
for i in self.list1:
try:
# 验证代理ip是否有效
res = requests.get(url='https://www.baidu.com', headers=self.headers, proxies={'http': 'http://' + i},
timeout=10)
if res.status_code == 200:
# ok_file.write(i + '\n')
ok_ip.append(i)
except:
continue
ok_file.close()
return ok_ip
def run(self):
return self.get_url()
dl = XiLaIp_Spider()
dl.run()
到此这篇关于Python爬虫简单运用爬取代理IP的实现的文章就介绍到这了,更多相关Python 爬取代理IP内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python中以函数作为参数(回调函数)的实现方法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-01-01
这篇文章主要介绍了python中以函数作为参数(回调函数)的实现方法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-01-01 这篇文章介绍了Python中的基本数据类型,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-07-07
这篇文章介绍了Python中的基本数据类型,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-07-07 这篇文章主要介绍了python numpy数组中的复制知识解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了python numpy数组中的复制知识解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了Python编译过程和执行原理解析,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-07-07
这篇文章主要介绍了Python编译过程和执行原理解析,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-07-07 这篇文章主要介绍了pandas 颠倒列顺序的两种解决方案,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-03-03
这篇文章主要介绍了pandas 颠倒列顺序的两种解决方案,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-03-03 这篇文章主要为大家详细介绍了Python echarts实现数据可视化,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-03-03
这篇文章主要为大家详细介绍了Python echarts实现数据可视化,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-03-03 这篇文章主要介绍了python中enumerate函数用法,以实例形式较为详细的分析了enumerate函数的功能、定义及使用技巧,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了python中enumerate函数用法,以实例形式较为详细的分析了enumerate函数的功能、定义及使用技巧,需要的朋友可以参考下2015-05-05
python库JsonSchema验证JSON数据结构使用详解
这篇文章主要为大家介绍了python库JsonSchema验证JSON数据结构的使用详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05 这篇文章主要介绍了python 中sys.getsizeof的用法说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05
这篇文章主要介绍了python 中sys.getsizeof的用法说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05 这篇文章主要介绍了django 中QuerySet特性功能详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了django 中QuerySet特性功能详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-07-07










最新评论