
scrapy-splash简单使用详解
更新时间:2021年02月21日 08:53:12 作者:zhu6201976-朱华龙
这篇文章主要介绍了scrapy-splash简单使用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
1.scrapy_splash是scrapy的一个组件
scrapy_splash加载js数据基于Splash来实现的
Splash是一个Javascrapy渲染服务,它是一个实现HTTP API的轻量级浏览器,Splash是用Python和Lua语言实现的,基于Twisted和QT等模块构建
使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后的网页源代码
2.scrapy_splash的作用
scrpay_splash能够模拟浏览器加载js,并返回js运行后的数据
3.scrapy_splash的环境安装
3.1 使用splash的docker镜像
docker info 查看docker信息
docker images 查看所有镜像
docker pull scrapinghub/splash 安装scrapinghub/splash
docker run -p 8050:8050 scrapinghub/splash & 指定8050端口运行
3.2.pip install scrapy-splash
3.3.scrapy 配置:
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
3.4.scrapy 使用
from scrapy_splash import SplashRequest
yield SplashRequest(self.start_urls[0], callback=self.parse, args={'wait': 0.5})
4.测试代码:
import datetime
import os
import scrapy
from scrapy_splash import SplashRequest
from ..settings import LOG_DIR
class SplashSpider(scrapy.Spider):
name = 'splash'
allowed_domains = ['biqugedu.com']
start_urls = ['http://www.biqugedu.com/0_25/']
custom_settings = {
'LOG_FILE': os.path.join(LOG_DIR, '%s_%s.log' % (name, datetime.date.today().strftime('%Y-%m-%d'))),
'LOG_LEVEL': 'INFO',
'CONCURRENT_REQUESTS': 8,
'AUTOTHROTTLE_ENABLED': True,
'AUTOTHROTTLE_TARGET_CONCURRENCY': 8,
'SPLASH_URL': 'http://localhost:8050',
'DOWNLOADER_MIDDLEWARES': {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
},
'SPIDER_MIDDLEWARES': {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
},
'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter',
'HTTPCACHE_STORAGE': 'scrapy_splash.SplashAwareFSCacheStorage',
}
def start_requests(self):
yield SplashRequest(self.start_urls[0], callback=self.parse, args={'wait': 0.5})
def parse(self, response):
"""
:param response:
:return:
"""
response_str = response.body.decode('utf-8', 'ignore')
self.logger.info(response_str)
self.logger.info(response_str.find('http://www.biqugedu.com/files/article/image/0/25/25s.jpg'))
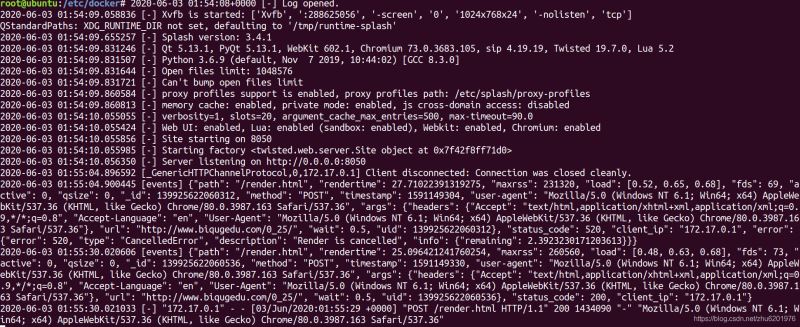
scrapy-splash接收到js请求:
到此这篇关于scrapy-splash简单使用详解的文章就介绍到这了,更多相关scrapy-splash 使用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
相关文章
 在日常学习和工作中,我们经常会遇到需要爬取网页内容的需求,今天就如何基于Python实现web网页内容爬取进行讲解,感兴趣的朋友一起看看吧2024-12-12
在日常学习和工作中,我们经常会遇到需要爬取网页内容的需求,今天就如何基于Python实现web网页内容爬取进行讲解,感兴趣的朋友一起看看吧2024-12-12 这篇文章主要介绍了Python在字符串中处理html和xml的方法,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-07-07
这篇文章主要介绍了Python在字符串中处理html和xml的方法,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-07-07 这篇文章主要介绍了python解析参数的三种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2022-07-07
这篇文章主要介绍了python解析参数的三种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2022-07-07 Python中有很多时间和日期处理的库,有time、datetime等,本文主要介绍了一下arrow,arrow是一个专门处理时间和日期的轻量级Python库,感兴趣的可以了解一下2021-09-09
Python中有很多时间和日期处理的库,有time、datetime等,本文主要介绍了一下arrow,arrow是一个专门处理时间和日期的轻量级Python库,感兴趣的可以了解一下2021-09-09 这篇文章主要介绍了python使用numpy计算两个框的iou方法示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-08-08
这篇文章主要介绍了python使用numpy计算两个框的iou方法示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-08-08 这篇文章主要介绍了pytorch快速搭建神经网络_Sequential操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06
这篇文章主要介绍了pytorch快速搭建神经网络_Sequential操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 这篇文章主要介绍了解析Python中while true的使用,while true即用来制造一个无限循环,需要的朋友可以参考下2015-10-10
这篇文章主要介绍了解析Python中while true的使用,while true即用来制造一个无限循环,需要的朋友可以参考下2015-10-10 在python中,它的time模块功能十分强大,我们今天就来学习下,废话少说,我们来看下实际的效果,下面贴出代码:2013-03-03
在python中,它的time模块功能十分强大,我们今天就来学习下,废话少说,我们来看下实际的效果,下面贴出代码:2013-03-03 本篇文章主要介绍了详解Django 中是否使用时区的区别,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-06-06
本篇文章主要介绍了详解Django 中是否使用时区的区别,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-06-06 Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,今天通过本文给大家介绍Python Pandas的简单使用教程,感兴趣的朋友一起看看吧2021-08-08
Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,今天通过本文给大家介绍Python Pandas的简单使用教程,感兴趣的朋友一起看看吧2021-08-08










最新评论