
Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频。
一、实现登录账号
这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码。登录后,采用session保持登录。
1.获取验证码地址
第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608
颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此真正的验证码图片地址是:https://per.enetedu.com/Common/CreateImage

第二步:找出登录时提交的表单内容和POST地址。
(1) 不填写用户名密码和验证码,直接点击登录,使用Chrome浏览器的Network检查,找到POST地址:https://per.enetedu.com/AdminIndex/LoginDo
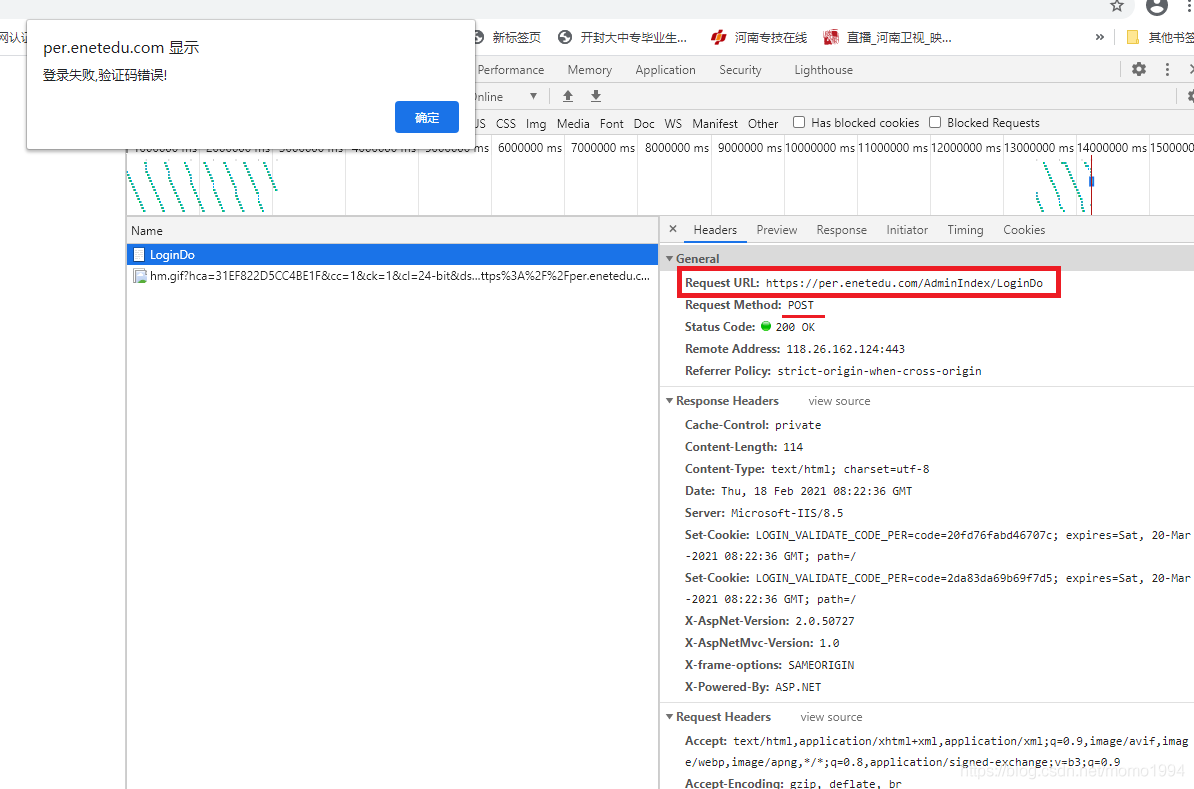
(2) 继续向下看,找到提交的表单 Form Data。
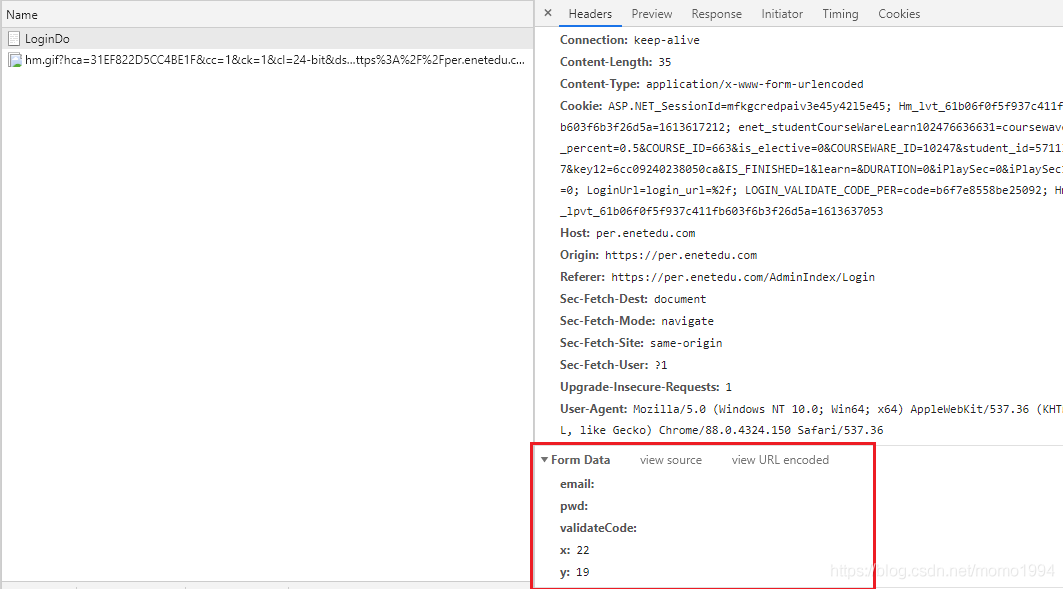
因此带有验证码的登录代码如下:
import requests
from PIL import Image
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '替换为自己的用户名'
password = '替换为自己的密码'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '22',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
二、实现ts碎片视频下载,并转换为mp4格式
1.分析视频下载地址
登录成功后,检查视频播放div对应的代码,企图找到视频地址直接保存至本地。结果,如下图所示,整个视频是被分割成一段一段的.ts文件,分段加载到页面中播放。GET每段视频的地址为右侧红框圈起来的部分。

百度后才知道,整个视频如何分段是由一个m3u8文件来决定的。m3u8文件中的内容如下所示,记录了每段视频start和end的编号。
#EXTM3U #EXT-X-VERSION:3 #EXT-X-ALLOW-CACHE:YES #EXT-X-TARGETDURATION:10 #EXTINF:10.000000, start_0-end_765064-record.gv.ts #EXTINF:10.000000, start_765064-end_1769567-record.gv.ts #EXTINF:10.000000, start_1769567-end_2600798-record.gv.ts #EXTINF:10.000000, start_2600798-end_3593502-record.gv.ts #EXTINF:10.000000, start_3593502-end_4500784-record.gv.ts #EXTINF:10.000000, start_4500784-end_5399861-record.gv.ts #EXTINF:10.000000, start_5399861-end_6288622-record.gv.ts #EXTINF:10.000000, start_6288622-end_7044459-record.gv.ts #EXTINF:10.000000, start_7044459-end_7878487-record.gv.ts #EXTINF:10.000000, start_7878487-end_8811793-record.gv.ts #EXTINF:10.000000,
因此,下载视频的关键是获取m3u8文件,通过这个视频的m3u8文件来分段下载视频。
我是人工找出m3u8的下载地址,暂时还没研究出来怎么通过视频地址自动解析出m3u8地址。找的方法很简单,还是在Chrome的Network控制台找。打开Network控制台,刷新页面,就可以找到如图所示的m3u8文件。查看m3u8文件的相关信息,可以看到红框圈起来的地址就是这个视频的m3u8下载地址。

对比两个地址,可以发现文件名前的地址相同,视频下载地址即为"标红地址"+"m3u8文件中列出的视频段文件名":
https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi/record.m3u8
https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi/start_643887-end_1083181-record.gv.ts
因此可以将这部分地址设为:urlroot = https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi
为了方便下载其他视频时动态修改,改为动态截取:
url = input("请输入m3u8文件地址:")
urlRoot=self.url[0:url.rindex('/')]
2.批量下载ts视频片段
这一步使用上一步拼接的地址循环下载ts视频即可。下载时,使用登录时创建的session下载。
session是会话的意思,它可以让服务器“认得”客户端。简单理解就是,把每一个客户端和服务器的互动当作一个“会话”。既然在同一个“会话”里,服务器自然就能知道这个客户端是否登录过。代码如下:
client = requests.Session() client.post(PostUrl,postData) #登录 resp = client.get(download_path) #下载
碎片拼接的方法:下载完第一个ts片段后,直接在该文件后面继续写第二个ts片段,以此类推。而不是新建一个文件写入。与验证码登录结合起来,完整代码如下:
import requests
from PIL import Image
import sys
import m3u8
import time
import os
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '526257482@qq.com'
password = 'dashuju_9514'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '56',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
#循环下载ts视频
class VideoCrawler():
def __init__(self,url):
super(VideoCrawler, self).__init__()
self.url=url
self.final_path=r"D:\Download\Film"
#下载并解析m3u8文件
def get_url_from_m3u8(self,readAdr):
print("正在解析真实下载地址...")
with open('temp.m3u8','wb') as file:
file.write(requests.get(readAdr).content)
m3u8Obj=m3u8.load('temp.m3u8')
print("解析完成")
return m3u8Obj.segments
def run(self):
print("Start!")
start_time=time.time()
realAdr = self.url #m3u8下载地址
urlList=self.get_url_from_m3u8(realAdr) #解析m3u8文件,获取下载地址
urlRoot=self.url[0:self.url.rindex('/')]
i=1
outputfile=open(os.path.join(self.final_path,'%s.ts'%self.fileName),'wb')#初始创建一个ts文件,之后每次循环将ts片段的文件流写入此文件中从而不需要在去合并ts文件
for url in urlList:
try:
download_path = "%s/%s" % (urlRoot, url.uri) #拼接地址
resp = client.get(download_path) #使用拼接地址去爬取数据
progess = i/len(urlList)#记录当前的爬取进度
outputfile.write(resp.content) #将爬取到ts片段的文件流写入刚开始创建的ts文件中
sys.stdout.write('\r正在下载:{},进度:{:.2%}'.format(self.fileName,progess))#通过百分比显示下载进度
sys.stdout.flush()#通过此方法将上一行代码刷新,控制台只保留一行
except Exception as e:
print("\n出现错误:%s",e.args)
continue#出现错误跳出当前循环,继续下次循环
i+=1
outputfile.close()
print("下载完成!总共耗时%d s"%(time.time()-start_time))
print("开始转换视频格式!")
success = os.system(r'copy /b D:\Download\Film\{0}.ts D:\Download\Film\{0}.mp4'.format(self.fileName)) #ts转成mp4格式
if (not success):
print("格式转换成功!")
os.remove(self.final_path+'\\'+self.fileName+".ts") #删除ts和m3u8临时文件
os.remove("temp.m3u8")
if __name__=='__main__':
m3u8_addr = input("输入m3u8文件下载地址:\n")
crawler=VideoCrawler(m3u8_addr)
crawler.fileName = input("输入文件名:\n")
crawler.run()
quitClick=input("请按Enter键确认退出!")
三、总结
代码可以实现分段加载视频的爬取功能,其中还有很多细节待完善如:
- 验证码可以通过图像识别的方法自动识别。
- 通过解析视频地址获取m3u8文件,非计算机专业人使用起来更加友好。
- 例子中的网站没有对m3u8文件进行加密,涉及到加密的m3u8还需要加一步解密的过程。
到此这篇关于Python爬虫爬取ts碎片视频+验证码登录功能的文章就介绍到这了,更多相关Python爬虫爬取视频内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 大家好,本篇文章主要讲的是Python函数装饰器的使用详解,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下2022-01-01
大家好,本篇文章主要讲的是Python函数装饰器的使用详解,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下2022-01-01
python使用fileinput模块实现逐行读取文件的方法
这篇文章主要介绍了python使用fileinput模块实现逐行读取文件的方法,涉及Python中fileinput模块操作文件的相关技巧,非常具有实用价值,需要的朋友可以参考下2015-04-04 在某些情况下,您可能希望将字符串动态转换为变量名,在本文中,我们将通过四个简单的示例来探索如何在Python中将字符串转换为变量名,需要的朋友可以参考下2024-10-10
在某些情况下,您可能希望将字符串动态转换为变量名,在本文中,我们将通过四个简单的示例来探索如何在Python中将字符串转换为变量名,需要的朋友可以参考下2024-10-10 这篇文章主要介绍了Python项目管理Git常用命令详图讲解,文中附含详细的图片讲解,建议收藏阅读,有需要的朋友可以借鉴参考下,希望能够有所帮助2021-09-09
这篇文章主要介绍了Python项目管理Git常用命令详图讲解,文中附含详细的图片讲解,建议收藏阅读,有需要的朋友可以借鉴参考下,希望能够有所帮助2021-09-09 这篇文章主要介绍了基于python分享极坐标下的几类典型曲线,极坐标系统是一套区别于笛卡尔直角坐标系的二维坐标系统,下面我们在python的基础上讲解及坐标及其下的几种曲线,需要的小伙伴可以参考一下2022-03-03
这篇文章主要介绍了基于python分享极坐标下的几类典型曲线,极坐标系统是一套区别于笛卡尔直角坐标系的二维坐标系统,下面我们在python的基础上讲解及坐标及其下的几种曲线,需要的小伙伴可以参考一下2022-03-03 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树。这篇文章将利用Prim算法实现迷宫的生成,感兴趣的可以了解一下2023-01-01
普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树。这篇文章将利用Prim算法实现迷宫的生成,感兴趣的可以了解一下2023-01-01 在开发过程当中时常需要使用 ChatGPT 来完成一些任务,但总是使用网页交互模式去 Web 端访问 ChatGPT 是很麻烦的,这时候我们可以使用代码来调用 ChatGPT 模型,本文将详细介绍在 Python 开发环境中调用 ChatGPT 模型过程,,需要的朋友可以参考下2023-05-05
在开发过程当中时常需要使用 ChatGPT 来完成一些任务,但总是使用网页交互模式去 Web 端访问 ChatGPT 是很麻烦的,这时候我们可以使用代码来调用 ChatGPT 模型,本文将详细介绍在 Python 开发环境中调用 ChatGPT 模型过程,,需要的朋友可以参考下2023-05-05 日常工作中总会遇到一些需要收集文件的情况,但往往最后收集回来的文件名称会五花八门,下面小编就来为大家讲讲如何使用Python实现批量重命名操作吧2025-02-02
日常工作中总会遇到一些需要收集文件的情况,但往往最后收集回来的文件名称会五花八门,下面小编就来为大家讲讲如何使用Python实现批量重命名操作吧2025-02-02 这篇文章主要为大家详细介绍了python版飞机大战的实现代码,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-11-11
这篇文章主要为大家详细介绍了python版飞机大战的实现代码,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-11-11 这篇文章主要介绍了python3 queue多线程通信,Queue 对象已经包含了必要的锁,所以你可以通过它在多个线程间多安全地共享数据,更多相关内容需要的朋友可以参考一下下文文章内容2022-07-07
这篇文章主要介绍了python3 queue多线程通信,Queue 对象已经包含了必要的锁,所以你可以通过它在多个线程间多安全地共享数据,更多相关内容需要的朋友可以参考一下下文文章内容2022-07-07










最新评论