
Python实战之疫苗研发情况可视化
更新时间:2021年05月18日 15:50:54 作者:Real&Love
2020年底以来,欧美,印度,中国,俄罗斯等多国得制药公司纷纷推出了针对新冠/肺炎的疫苗,这部分主要分析了2020年以来全球疫情形势,各类疫苗在全球的地理分布,疫苗在各国的接种进度进行可视化展示,需要的朋友可以参考下
一、安装plotly库
因为这部分内容主要是用plotly库进行数据动态展示,所以要先安装plotly库
pip install plotly
除此之外,我们对数据的处理还用了numpy和pandas库,如果你没有安装的话,可以用以下命令一行安装
pip install plotly numpy pandas
#导入所需库 import pandas as pd import numpy as np import plotly.express as px import plotly.graph_objects as go
二、疫苗研发情况
各国采用的疫苗品牌概览
通过对各国卫生部门确认备案的疫苗品牌,展示各厂商的疫苗在全球的分布
#读取数据 locations=pd.read_csv(r'data/locations.csv')
locations
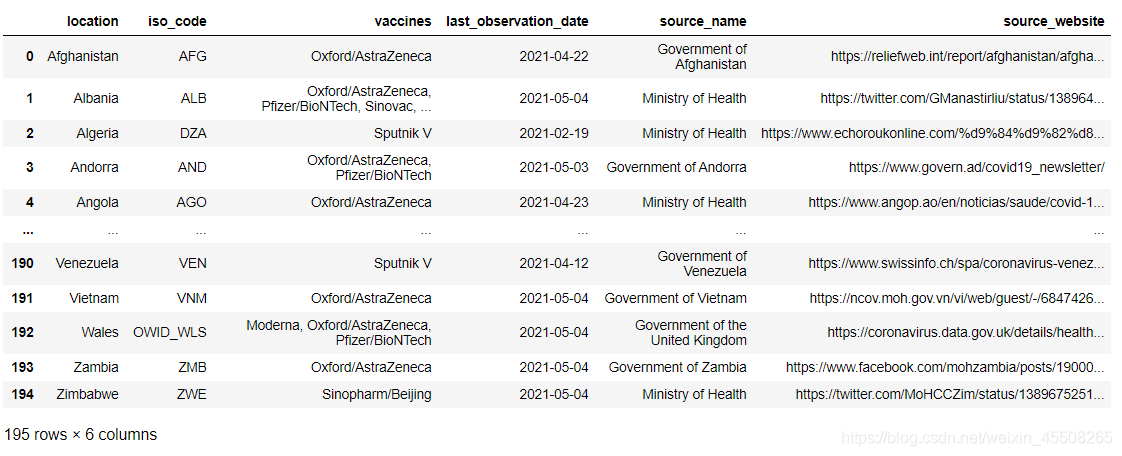
这里我们的loacation中可以看到各个地方的疫苗和数据的来源与数据来源的网页
三、数据处理
#发现数据中vaccines列中包含了多个品牌的情况,将这类数拆为多条
vaccines_by_country=pd.DataFrame()
for i in locations.iterrows():
df=pd.DataFrame({'Country':i[1].location,'vaccines':i[1].vaccines.split(',')})
vaccines_by_country=pd.concat([vaccines_by_country,df])
vaccines_by_country['vaccines']=vaccines_by_country.vaccines.str.strip()# 去掉空格
vaccines_by_country.vaccines.unique() # 查看疫苗的种类

四、可视化疫苗的分布情况
#绘图
fig=px.choropleth(vaccines_by_country,
locations='Country',
locationmode='country names',
color='vaccines',
facet_col='vaccines',
facet_col_wrap=3)
fig.update_layout(width=1200, height=1000)
fig.show()
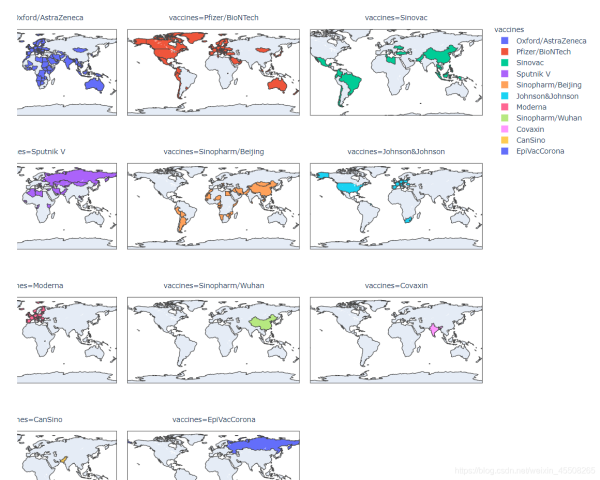
各品牌分布:
- Pfizer/BioNTech 主要分布于北美,南美的智利、厄瓜多尔,欧洲、沙特
- Sputnik V 主要分布于俄罗斯、伊朗、巴基斯坦、非洲的阿尔及利亚以及南美的玻利维亚、阿根廷
- Oxford/AstraZeneca 主要分布于欧洲、南亚、巴西
- Moderna 主要分布在北美和欧洲
- Sinopharm/Beijing 主要分布在中国、北非部分国家和南美的秘鲁
- Sinovac 主要分布在中国、南亚、土耳其和南美
- Sinopharm/Wuhan 主要仅分布于中国
- Covaxin 主要分布于印度
综上可以发现,全球采用最广的仍是Pfizer/BioNTech,国产疫苗中Sinovac(北京科兴疫苗)输出到了较多国家
五、各品牌疫苗上市情况(仅部分国家)
根据数据集中提供的部分国家20年12月以来各品牌疫苗接种情况,分析各品牌上市时间及市场占有情况
#读取数据 vacc_by_manu=pd.read_csv(r'data/vaccinations-by-manufacturer.csv')
#定义函数,用于从原始数据中组织宽表
def query(df,country,date,vaccine):
try:
result=df.loc[(df.location==country)&(df.date==date)&(df.vaccine==vaccine)].total_vaccinations.iloc[0]
except:
result=np.nan
return result
vacc_by_manu

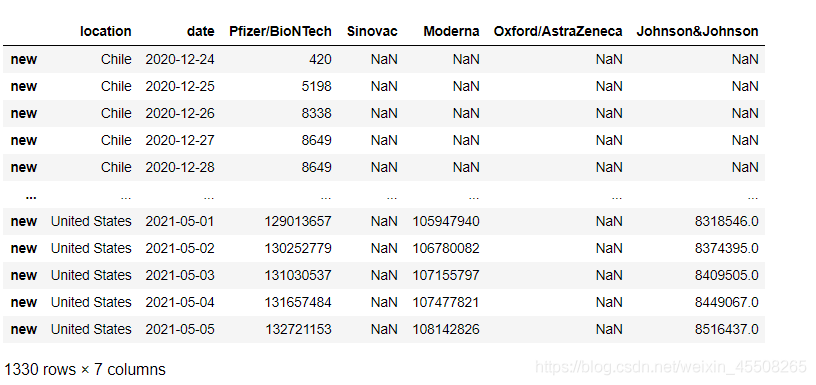
六、组织宽表
#组织宽表
vacc_combined=pd.DataFrame(columns=['location','date','Pfizer/BioNTech', 'Sinovac', 'Moderna', 'Oxford/AstraZeneca'])
for i in vacc_by_manu.location.unique():
for j in vacc_by_manu.date.unique():
for z in vacc_by_manu.vaccine.unique():
result=query(vacc_by_manu,i,j,z)
if vacc_combined.loc[(vacc_combined.location==i)&(vacc_combined.date==j)].empty:
result_df=pd.DataFrame({'location':i,'date':j,z:result},index=['new'])
vacc_combined=pd.concat([vacc_combined,result_df])
else:
vacc_combined.loc[(vacc_combined.location==i)&(vacc_combined.date==j),z]=result
vacc_combined
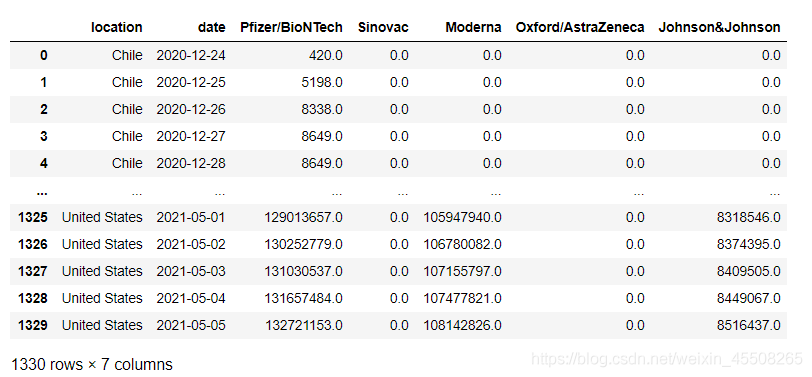
七、补全缺失数据
#补全缺失数据
temp=pd.DataFrame()
for i in vacc_combined.location.unique():#按国家进行不全
r=vacc_combined.loc[vacc_combined.location==i]
r=r.fillna(method='ffill',axis=0)#先按最近一次的数据进行补全
temp=pd.concat([temp,r])#若没有最近的数据,认为该项为0
temp=temp.fillna(0).reset_index(drop=True)
temp
八、绘制堆叠柱状图
#绘制堆叠柱状图
fig=px.bar(temp,
x='location',
y=vacc_by_manu.vaccine.unique(),
animation_frame='date',
color_discrete_sequence=['#636efa','#19d3f3','#ab63fa','#00cc96']#为了查看方便,品牌颜色与前一部分对应
)
fig.show()
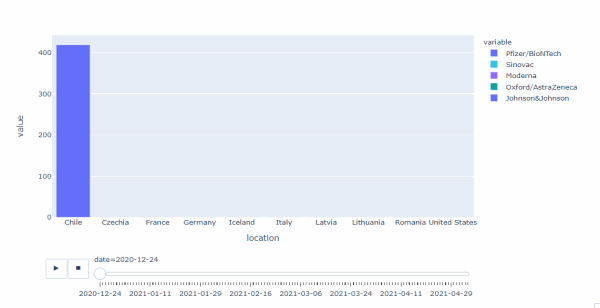
数据中主要涉及Pfizer/BioNTech、Sinovac、Moderna、Oxford/AstraZeneca 4个品牌,其中:
- Pfizer/BioNTech 上市时间最早,20年12月24日时即已经开始在智利接种了,之后在12月底开始在欧洲接种,21年1月12日开始在美国接种
- Sinovac 21年2月2日开始在智利接种Moderna 21年1月8日先在意大利开始接种,随后12日即开始在美国大量接种,最终在欧洲及美国均大量接种
- Oxford/AstraZeneca 21年2月2日先在意大利开始接种,随后即在欧洲开始接种
- 整体上看,Pfizer/BioNTech上市最早,且在全球占有份额最大,Moderna 随后上市,主要占据美国和欧洲市场,Sinovac、Oxford/AstraZeneca上市均较晚,其中Sinovac占据了智利的大部分市场份额,而Oxford/AstraZeneca主要分布于欧洲,且占份额很小
到此这篇关于Python实战之疫苗研发情况可视化的文章就介绍到这了,更多相关Python疫苗研发情况可视化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
- Python利用folium实现地图可视化
- Python编写可视化界面的全过程(Python+PyCharm+PyQt)
- Python实现K-means聚类算法并可视化生成动图步骤详解
- python开发实时可视化仪表盘的示例
- python数据分析之员工个人信息可视化
- 使用python实现三维图可视化
- 关于Python可视化Dash工具之plotly基本图形示例详解
- python用pyecharts实现地图数据可视化
- Python绘制K线图之可视化神器pyecharts的使用
- Python绘制词云图之可视化神器pyecharts的方法
- Python实现疫情地图可视化
- python 可视化库PyG2Plot的使用
- python使用Streamlit库制作Web可视化页面
相关文章
 这篇文章主要介绍了如何搭建pytorch环境的方法步骤,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-05-05
这篇文章主要介绍了如何搭建pytorch环境的方法步骤,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-05-05 这篇文章主要介绍了python selenium循环登陆网站的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-11-11
这篇文章主要介绍了python selenium循环登陆网站的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-11-11 这篇文章主要介绍了Apache,wsgi,django 程序部署配置方法,结合实例形式详细分析了Linux环境下Apache,wsgi,django程序部署配置的相关操作技巧与注意事项,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了Apache,wsgi,django 程序部署配置方法,结合实例形式详细分析了Linux环境下Apache,wsgi,django程序部署配置的相关操作技巧与注意事项,需要的朋友可以参考下2019-07-07
python3+django2开发一个简单的人员管理系统过程详解
这篇文章主要介绍了python3+django2开发一个简单的人员管理系统过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-07-07 本文介绍了Python中多进程实现数据共享的方法,包括使用multiprocessing模块和manager模块这两种方法,具有一定的参考价值,感兴趣的可以了解一下2025-01-01
本文介绍了Python中多进程实现数据共享的方法,包括使用multiprocessing模块和manager模块这两种方法,具有一定的参考价值,感兴趣的可以了解一下2025-01-01 Python因为具有超多的第三方库而被大家喜欢,下面这篇文章主要给大家介绍了关于如何查看python脚本所依赖三方包及其版本的相关资料,文中通过图文介绍的非常详细,需要的朋友可以参考下2023-03-03
Python因为具有超多的第三方库而被大家喜欢,下面这篇文章主要给大家介绍了关于如何查看python脚本所依赖三方包及其版本的相关资料,文中通过图文介绍的非常详细,需要的朋友可以参考下2023-03-03 今天小编就为大家分享一篇python通过txt文件批量安装依赖包的实现步骤,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08
今天小编就为大家分享一篇python通过txt文件批量安装依赖包的实现步骤,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08 这篇文章主要介绍了使用python+Pyqt5实现串口调试助手,串口通讯程序首先要对串口进行设置,如波特率、数据位、停止位、校验位等,需要的朋友可以参考下2022-04-04
这篇文章主要介绍了使用python+Pyqt5实现串口调试助手,串口通讯程序首先要对串口进行设置,如波特率、数据位、停止位、校验位等,需要的朋友可以参考下2022-04-04 这篇文章主要介绍了使用Python快速写一个小游戏,本次开发的小游戏叫alien invasion,具体实现过程大家参考下本文2018-04-04
这篇文章主要介绍了使用Python快速写一个小游戏,本次开发的小游戏叫alien invasion,具体实现过程大家参考下本文2018-04-04 这篇文章主要介绍了Python selenium一定要会用selenium的等待,三种等待方式解读的相关资料,需要的朋友可以参考下2016-09-09
这篇文章主要介绍了Python selenium一定要会用selenium的等待,三种等待方式解读的相关资料,需要的朋友可以参考下2016-09-09










最新评论