
Python爬虫必备之Xpath简介及实例讲解
更新时间:2022年04月26日 10:42:03 作者:梦然网络
xpath是一种在XML文档中定位元素的语言,常用于xml、html文件解析,比css选择器使用方便,下面这篇文章主要给大家介绍了关于Python爬虫必备之Xpath简介及实例的相关资料,需要的朋友可以参考下
前言
网上已经有很多大佬发过Xpath,而且讲的都很好,我是因为刚开始学习网络爬虫,对这些基础重要知识不太了解,所以写一下来加深印象,本篇文章只是简单介绍一下Xpath及使用,总体来说比较基础。
一、Xpath简介
XPath(XML Path Language - XML路径语言),它是一种用来确定XML文档中某部分位置的语言。
Xpath以XML为基础,提供用户在数据结构树中寻找节点的能力,Xpath被很多开发者亲切的称为小型查询语言。
二、Xpath语法规则
xpath可以使用路径表达式在XML上选取节点,从而达到确认元素的目的,我们先来介绍以下语法规则。
语法规则
| 表达式 | 作用 |
|---|---|
| nodename | 选取此层级节点下的所有子节点 |
| / | 代表从根节点进行选取 |
| // | 可以理解为匹配,就是在所有节点中选取此节点,直到匹配为止 |
| . | 选取当前节点 |
| … | 选取当前节点上一层(上一级目录) |
| @ | 选取属性(也是匹配) |
标签定位
| 方式 | 效果 |
|---|---|
| /html/body/div | 表示从根节点开始寻找,标签与标签之间/表示一个层级 |
| /html//div | 表示多个层级 作用于两个标签之间(也可以理解为在html下进行匹配寻找标签div) |
| //div | 从任意节点开始寻找,也就是查找所有的div标签 |
| ./div | 表示从当前的标签开始寻找div |
属性定位
| 需求 | 格式 |
|---|---|
| 定位div中属性名为href,属性值为‘www.baidu.com’的div标签 | @属性名=属性值 |
| href为属性名 'www.baidu.com’为属性值 | /html/body/div[href=‘www.baidu.com’] |
索引定位
| 需求 | 格式 |
|---|---|
| 定位ul下第二个li标签(下图) | //ul/li[2] |
| 索引值开始位置为 | 1 |
取文本内容
| 方法 | 效果 |
|---|---|
| /text() | 获取标签下直系的标签内容 |
| //text() | 获取标签中所有的文本内容 |
| string() | 获取标签中所有的文本内容 |
在网页上获取Xpath其实很容易,直接找到标签后,右键复制就好了。
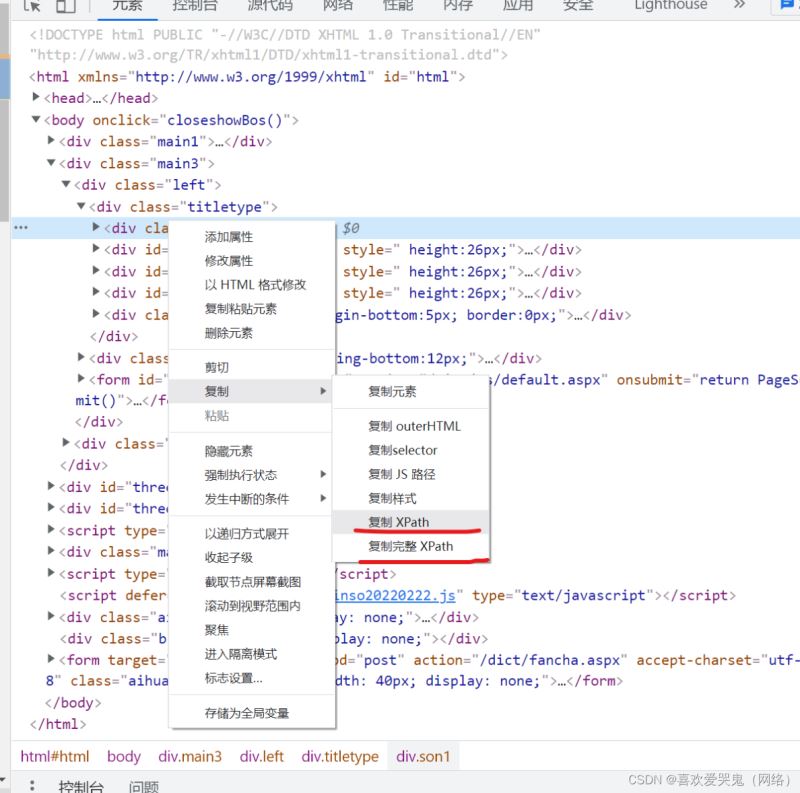
三、语法规则练习
接下来我们开始练习一下本地导入,加深一下理解,这个是一个比较简单的网页结构,我们先学会用法即可。
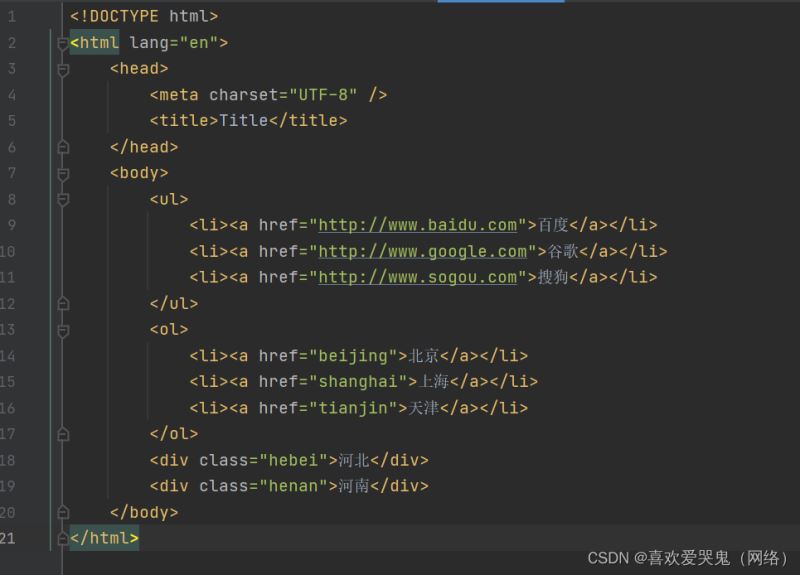
任务要求: 可以达到随心所欲的定位每一个元素
准备工作
#导入所需要的包
from lxml import etree
#采用本地源码获取方式并加载到etree内
tree = etree.parse('test.html')
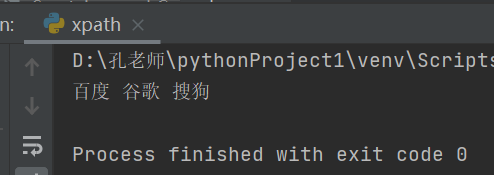
1.获取百度、谷歌、搜狗文本内容
#引用xpath方法并进行标签定位
#''.join是取字符串内的内容
text = ' '.join(tree.xpath('/html/body/ul/li/a/text()'))
print(text)
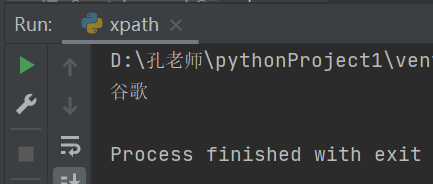
2.获取单个谷歌
text1 = tree.xpath("//ul/li[2]/a/text()")[0]
print(text1)
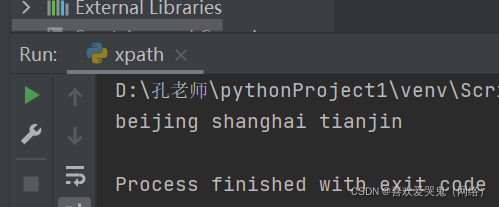
3.获取北京、上海、天津的属性值
text2 = ' '.join(tree.xpath("//ol/li/a/@href"))
print(text2)
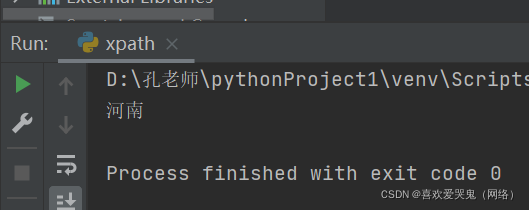
4.获取河南文本
#获取河南文本
text3 = tree.xpath("/html/body/div[2]/text()")[0]
print(text3)
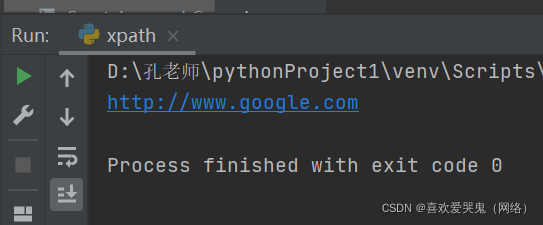
5.获取谷歌属性值
text4 = tree.xpath("//ul/li[2]/a/@href")[0]
print(text4)
至此我们已经可以随心定位任意标签 完成任务 收工
总结
到此这篇关于Python爬虫必备之Xpath简介及实例的文章就介绍到这了,更多相关Python爬虫Xpath实例内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 今天小编就为大家分享一篇Tensorflow的梯度异步更新示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01
今天小编就为大家分享一篇Tensorflow的梯度异步更新示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01
pytorch中的reshape()、view()、nn.flatten()和flatten()使用
这篇文章主要介绍了pytorch中的reshape()、view()、nn.flatten()和flatten()使用,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08 这篇文章主要为大家介绍了Scrapy爬虫Response它的子类(TextResponse、HtmlResponse、XmlResponse)在应用问题解析2023-05-05
这篇文章主要为大家介绍了Scrapy爬虫Response它的子类(TextResponse、HtmlResponse、XmlResponse)在应用问题解析2023-05-05 这篇文章主要介绍了Pytest allure 命令行参数的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-04-04
这篇文章主要介绍了Pytest allure 命令行参数的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-04-04 这篇文章主要介绍了Python数据分析--Pandas知识点,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-03-03
这篇文章主要介绍了Python数据分析--Pandas知识点,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-03-03 将PDF文件转换为Word文档的过程通常需要使用一些外部库来实现,因为Python本身并不直接支持这种转换,这篇文章主要介绍了Python PDF转化wolrd代码的写法小结,需要的朋友可以参考下2024-06-06
将PDF文件转换为Word文档的过程通常需要使用一些外部库来实现,因为Python本身并不直接支持这种转换,这篇文章主要介绍了Python PDF转化wolrd代码的写法小结,需要的朋友可以参考下2024-06-06
selenium+headless chrome爬虫的实现示例
这篇文章主要介绍了selenium+headless chrome爬虫的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-01-01 这篇文章主要介绍了pytorch常用函数之torch.randn()解读,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
这篇文章主要介绍了pytorch常用函数之torch.randn()解读,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 Tesseract 是一个开源的光学字符识别(OCR)引擎,它能够识别多种语言的文本,可将扫描文档、图像中的文字提取并转换为计算机可编辑的文本格式,本文给大家介绍了python使用tesseract实现字符识别功能,需要的朋友可以参考下2024-10-10
Tesseract 是一个开源的光学字符识别(OCR)引擎,它能够识别多种语言的文本,可将扫描文档、图像中的文字提取并转换为计算机可编辑的文本格式,本文给大家介绍了python使用tesseract实现字符识别功能,需要的朋友可以参考下2024-10-10
Python压缩包处理模块zipfile和py7zr操作代码
目前对文件的压缩和解压缩比较常用的格式就是zip格式和7z格式,这篇文章主要介绍了Python压缩包处理模块zipfile和py7zr,需要的朋友可以参考下2022-06-06










最新评论