
Python实现聚类K-means算法详解
K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差

注:为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若到达最大轮数或调整幅度小于阈值,则停止运行。
下面我们用python来实现一下K-means算法:我们先尝试手动实现这个算法,再用sklearn库中的KMeans类来实现。数据我们采用《机器学习》的西瓜数据(P202表9.1):
# 下面的内容保存在 melons.txt 中 # 第一列为西瓜的密度;第二列为西瓜的含糖率。我们要把这30个西瓜分为3类 0.697 0.460 0.774 0.376 0.634 0.264 0.608 0.318 0.556 0.215 0.403 0.237 0.481 0.149 0.437 0.211 0.666 0.091 0.243 0.267 0.245 0.057 0.343 0.099 0.639 0.161 0.657 0.198 0.360 0.370 0.593 0.042 0.719 0.103 0.359 0.188 0.339 0.241 0.282 0.257 0.748 0.232 0.714 0.346 0.483 0.312 0.478 0.437 0.525 0.369 0.751 0.489 0.532 0.472 0.473 0.376 0.725 0.445 0.446 0.459
手动实现
我们用到的库有matplotlib和numpy,如果没有需要先用pip安装一下。
import random import numpy as np import matplotlib.pyplot as plt
下面定义一些数据:
k = 3 # 要分的簇数 rnd = 0 # 轮次,用于控制迭代次数(见上文) ROUND_LIMIT = 100 # 轮次的上限 THRESHOLD = 1e-10 # 单轮改变距离的阈值,若改变幅度小于该阈值,算法终止 melons = [] # 西瓜的列表 clusters = [] # 簇的列表,clusters[i]表示第i簇包含的西瓜
从melons.txt读取数据,保存在列表中:
f = open('melons.txt', 'r')
for line in f:
# 把字符串转化为numpy中的float64类型
melons.append(np.array(line.split(' '), dtype = np.string_).astype(np.float64))从 m m m个数据中随机挑选出 k k k个,对应上面算法的第 1 1 1行:
# random的sample函数从列表中随机挑选出k个样本(不重复)。我们在这里把这些样本作为均值向量 mean_vectors = random.sample(melons, k)
下面是算法的主要部分。
# 这个while对应上面算法的2-17行
while True:
rnd += 1 # 轮次增加
change = 0 # 把改变幅度重置为0
# 清空对簇的划分,对应上面算法的第3行
clusters = []
for i in range(k):
clusters.append([])
# 这个for对应上面算法的4-8行
for melon in melons:
'''
argmin 函数找出容器中最小的下标,在这里这个目标容器是
list(map(lambda vec: np.linalg.norm(melon - vec, ord = 2), mean_vectors)),
它表示melon与mean_vectors中所有向量的距离列表。
(numpy.linalg.norm计算向量的范数,ord = 2即欧几里得范数,或模长)
'''
c = np.argmin(
list(map( lambda vec: np.linalg.norm(melon - vec, ord = 2), mean_vectors))
)
clusters[c].append(melon)
# 这个for对应上面算法的9-16行
for i in range(k):
# 求每个簇的新均值向量
new_vector = np.zeros((1,2))
for melon in clusters[i]:
new_vector += melon
new_vector /= len(clusters[i])
# 累加改变幅度并更新均值向量
change += np.linalg.norm(mean_vectors[i] - new_vector, ord = 2)
mean_vectors[i] = new_vector
# 若超过设定的轮次或者变化幅度<预先设定的阈值,结束算法
if rnd > ROUND_LIMIT or change < THRESHOLD:
break
print('最终迭代%d轮'%rnd)最后我们绘图来观察一下划分的结果:
colors = ['red', 'green', 'blue']
# 每个簇换一下颜色,同时迭代簇和颜色两个列表
for i, col in zip(range(k), colors):
for melon in clusters[i]:
# 绘制散点图
plt.scatter(melon[0], melon[1], color = col)
plt.show()划分结果(由于最开始的 k k k个均值向量随机选取,每次划分的结果可能会不同):

完整代码:
import random
import numpy as np
import matplotlib.pyplot as plt
k = 3
rnd = 0
ROUND_LIMIT = 10
THRESHOLD = 1e-10
melons = []
clusters = []
f = open('melons.txt', 'r')
for line in f:
melons.append(np.array(line.split(' '), dtype = np.string_).astype(np.float64))
mean_vectors = random.sample(melons, k)
while True:
rnd += 1
change = 0
clusters = []
for i in range(k):
clusters.append([])
for melon in melons:
c = np.argmin(
list(map( lambda vec: np.linalg.norm(melon - vec, ord = 2), mean_vectors))
)
clusters[c].append(melon)
for i in range(k):
new_vector = np.zeros((1,2))
for melon in clusters[i]:
new_vector += melon
new_vector /= len(clusters[i])
change += np.linalg.norm(mean_vectors[i] - new_vector, ord = 2)
mean_vectors[i] = new_vector
if rnd > ROUND_LIMIT or change < THRESHOLD:
break
print('最终迭代%d轮'%rnd)
colors = ['red', 'green', 'blue']
for i, col in zip(range(k), colors):
for melon in clusters[i]:
plt.scatter(melon[0], melon[1], color = col)
plt.show()sklearn库中的KMeans
这种经典算法显然不需要我们反复地造轮子,被广泛使用的python机器学习库sklearn已经提供了该算法的实现。sklearn的官方文档中给了我们一个示例:
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [10, 2], [10, 4], [10, 0]])
>>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
>>> kmeans.labels_
array([1, 1, 1, 0, 0, 0], dtype=int32)
>>> kmeans.predict([[0, 0], [12, 3]])
array([1, 0], dtype=int32)
>>> kmeans.cluster_centers_
array([[10., 2.],
[ 1., 2.]])可以看出,X即要聚类的数据(1,2),(1,4),(1,0)等。KMeans类的初始化参数n_clusters即簇数 k k k;random_state是用于初始化选取 k k k个向量的随机数种子;kmeans.labels_即每个点所属的簇;kmeans.predict方法预测新的数据属于哪个簇;kmeans.cluster_centers_返回每个簇的中心。
我们就改造一下这个简单的示例,完成对上面西瓜的聚类。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
X = []
f = open('melons.txt', 'r')
for line in f:
X.append(np.array(line.split(' '), dtype = np.string_).astype(np.float64))
kmeans = KMeans(n_clusters = 3, random_state = 0).fit(X)
colors = ['red', 'green', 'blue']
for i, cluster in enumerate(kmeans.labels_):
plt.scatter(X[i][0], X[i][1], color = colors[cluster])
plt.show()运行结果如下,可以看到和我们手写的聚类结果基本一致:
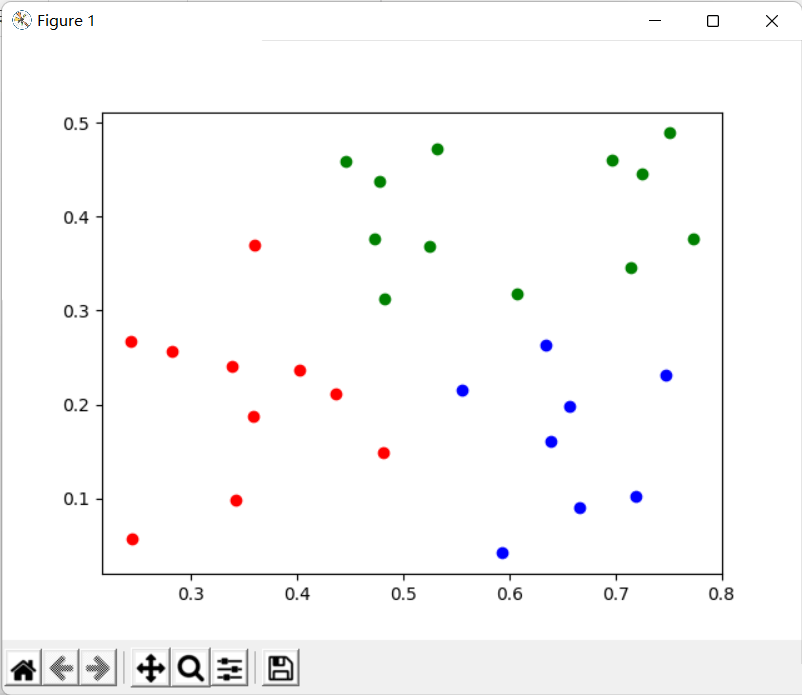
到此这篇关于Python实现聚类K-means算法详解的文章就介绍到这了,更多相关Python K-means算法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python实现CET查分的方法,实例分析了Python操作链接查询的技巧,需要的朋友可以参考下2015-03-03
这篇文章主要介绍了Python实现CET查分的方法,实例分析了Python操作链接查询的技巧,需要的朋友可以参考下2015-03-03 在Python编程中,with关键字用于简化文件操作流程,包括文件的打开、读取、写入和关闭,它是一个上下文管理器,确保即使在发生异常的情况下,文件也能被正确关闭,释放系统资源,本文给大家介绍Python中的with关键字和文件操作方法,感兴趣的朋友一起看看吧2024-10-10
在Python编程中,with关键字用于简化文件操作流程,包括文件的打开、读取、写入和关闭,它是一个上下文管理器,确保即使在发生异常的情况下,文件也能被正确关闭,释放系统资源,本文给大家介绍Python中的with关键字和文件操作方法,感兴趣的朋友一起看看吧2024-10-10 这篇文章主要介绍了Django中对数据查询结果进行排序的方法,利用Python代码代替SQL进行一些简单的操作,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了Django中对数据查询结果进行排序的方法,利用Python代码代替SQL进行一些简单的操作,需要的朋友可以参考下2015-07-07
浅谈配置OpenCV3 + Python3的简易方法(macOS)
下面小编就为大家分享一篇浅谈配置OpenCV3 + Python3的简易方法(macOS),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04 这篇文章主要为大家详细介绍了python实现随机漫步算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-08-08
这篇文章主要为大家详细介绍了python实现随机漫步算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-08-08 这篇文章主要介绍了python实现的分层随机抽样案例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02
这篇文章主要介绍了python实现的分层随机抽样案例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02 这篇文章主要为大家详细介绍了python smtplib发送带附件邮件小程序,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-05-05
这篇文章主要为大家详细介绍了python smtplib发送带附件邮件小程序,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-05-05
Mac在python3环境下安装virtualwrapper遇到的问题及解决方法
这篇文章主要介绍了Mac在python3环境下安装virtualwrapper遇到的问题及解决方法,我在使用mac安装virtualwrapper的时候遇到了问题,搞了好长时间,,在这里总结一下分享出来,供遇到相同的问题的朋友使用,少走些弯路,需要的朋友可以参考下2019-07-07 在本篇文章里小编给大家整理的是一篇关于python字典与json转换的方法总结内容,有需要的朋友们可以学习下。2020-12-12
在本篇文章里小编给大家整理的是一篇关于python字典与json转换的方法总结内容,有需要的朋友们可以学习下。2020-12-12 这篇文章主要介绍了jupyter运行时左边一直出现*号问题及解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09
这篇文章主要介绍了jupyter运行时左边一直出现*号问题及解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09










最新评论