
Python中reset_index()函数的使用
resert_index()函数
Series.reset_index(level=None, drop=False, name=NoDefault.no_default, inplace=False)
- drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False
- inplace: 是否在原DataFrame上改动,默认为False
- level: 如果索引(index)有多个列,仅从索引中删除level指定的列,默认删除所有列
- col_level: 如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级
- col_fill: 如果列名(columns)有多个级别,决定其他级别如何命名
- 作用: 用索引重置生成一个新的DataFrame或Series。当索引需要被视为列,或者索引没有意义,需要在另一个操作之前重置为默认值时。在机器学习中常常会对索引进行一定的处理,用于是否保留原有的索引。
返回:DataFrame or None。具有新索引的数据帧,如果inplace=True,则无索引。
例子:
import pandas as pd
df = pd.DataFrame(data={'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]})
print(df)
print('\n')
print(df.reset_index()) # 会将原来的索引index作为新的一列
print('\n')
print(df.reset_index(drop=True)) # 使用drop参数设置去掉原索引
print('\n')结果:
A B C
0 1 4 7
1 2 5 8
2 3 6 9
index A B C
0 0 1 4 7
1 1 2 5 8
2 2 3 6 9
A B C
0 1 4 7
1 2 5 8
2 3 6 9
读懂代码中resert_index():
def concat_detail(x):
return pd.Series({'备注':';'.join(x['detail'])})
df2=df1[['cwhxzqh','detail']].groupby('cwhxzqh').apply(concat_detail).reset_index()
df2将df1中原来的索引作为一个列,列名为 index
补:各参数的用法
示例
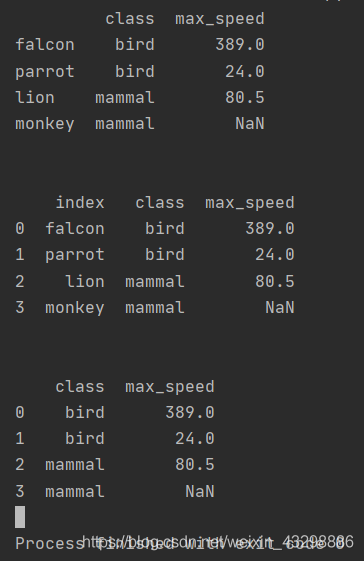
参数drop
False表示重新设置索引后将原索引作为新的一列并入DataFrame,True表示删除原索引
import pandas as pd
import numpy as np
df = pd.DataFrame([('bird', 389.0), ('bird', 24.0), ('mammal', 80.5), ('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'], columns=('class', 'max_speed'))
print(df)
print('\n')
df1 = df.reset_index()
print(df1)
print('\n')
df2 = df.reset_index(drop=True)
print(df2)输出:
参数inplace
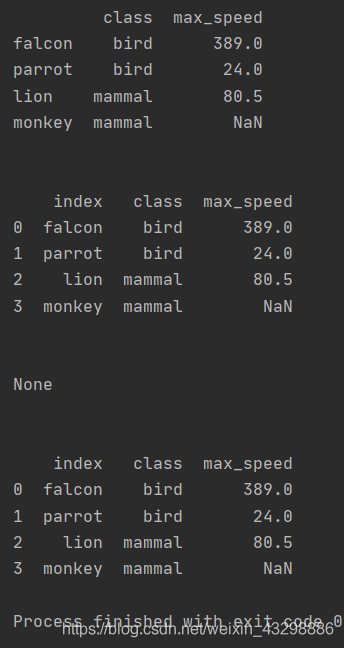
True表示在原DataFrame上修改,False将修改后的DataFrame作为新的对象返回
import pandas as pd
import numpy as np
df = pd.DataFrame([('bird', 389.0), ('bird', 24.0), ('mammal', 80.5), ('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'], columns=('class', 'max_speed'))
print(df)
print('\n')
df1 = df.reset_index()
print(df1)
print('\n')
df2 = df.reset_index(inplace=True)
print(df2)
print('\n')
print(df)输出:
参数level
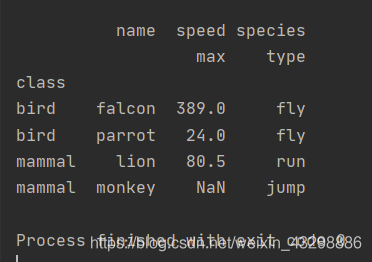
如果索引有多个列,仅从索引中删除由level指定的列,默认删除所有列。输入整数时表示将index的names中下标为level的索引删除;输入为字符串时表示将名字为level的索引删除
import pandas as pd
import numpy as np
index = pd.MultiIndex.from_tuples([('bird', 'falcon'), ('bird', 'parrot'), ('mammal', 'lion'), ('mammal', 'monkey')], names=['class', 'name'])
columns = pd.MultiIndex.from_tuples([('speed', 'max'), ('species', 'type')])
df = pd.DataFrame([(389.0, 'fly'), ( 24.0, 'fly'), ( 80.5, 'run'), (np.nan, 'jump')], index=index, columns=columns)
print(df)
print('\n')
df0 = df.reset_index()
print(df0)
print('\n')
df1 = df.reset_index(level=1)
print(df1)
print('\n')
df2 = df.reset_index(level='name')
print(df2)输出:

参数col_level
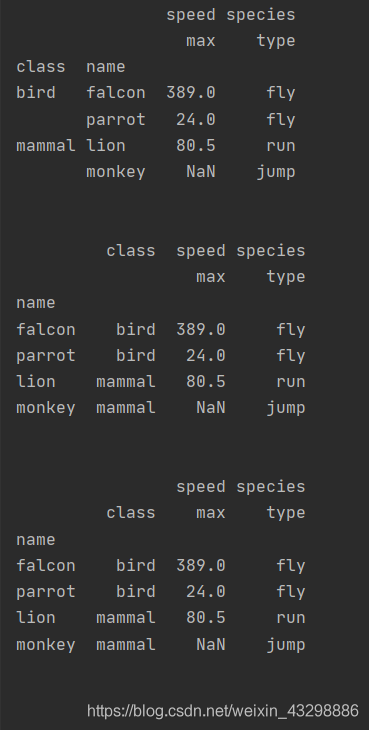
如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级(col_level=0)
import pandas as pd
import numpy as np
index = pd.MultiIndex.from_tuples([('bird', 'falcon'), ('bird', 'parrot'), ('mammal', 'lion'), ('mammal', 'monkey')], names=['class', 'name'])
columns = pd.MultiIndex.from_tuples([('speed', 'max'), ('species', 'type')])
df = pd.DataFrame([(389.0, 'fly'), ( 24.0, 'fly'), ( 80.5, 'run'), (np.nan, 'jump')], index=index, columns=columns)
print(df)
print('\n')
df1 = df.reset_index(level=0, col_level=0)
print(df1)
print('\n')
df2 = df.reset_index(level=0, col_level=1)
print(df2)
print('\n')输出:
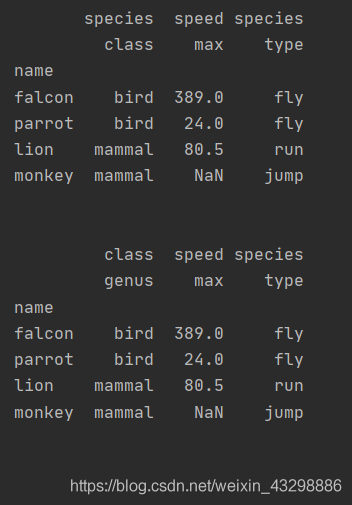
参数col_fill
重置索引时被删除的索引只能插入一个级别,如果列名(columns)有多个级别,那么这个列的列名的其他级别如何命名就由col_fill决定,默认不做填充,如果传入None则用被删除的索引的名字填充
import pandas as pd
import numpy as np
index = pd.MultiIndex.from_tuples([('bird', 'falcon'), ('bird', 'parrot'), ('mammal', 'lion'), ('mammal', 'monkey')], names=['class', 'name'])
columns = pd.MultiIndex.from_tuples([('speed', 'max'), ('species', 'type')])
df = pd.DataFrame([(389.0, 'fly'), ( 24.0, 'fly'), ( 80.5, 'run'), (np.nan, 'jump')], index=index, columns=columns)
print(df)
print('\n')
df0 = df.reset_index(level=0, col_level=0)
print(df0)
print('\n')
df1 = df.reset_index(level=0, col_level=0, col_fill=None)
print(df1)
print('\n')
df2 = df.reset_index(level=0, col_level=1, col_fill='species')
print(df2)
print('\n')
df3 = df.reset_index(level=0, col_level=0, col_fill='genus')
print(df3)
print('\n')输出: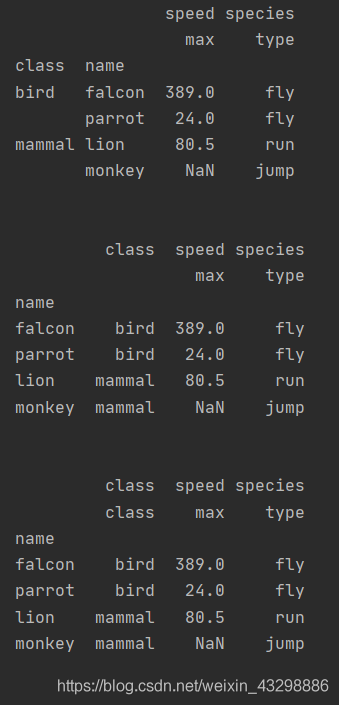
到此这篇关于Python中reset_index()函数的使用的文章就介绍到这了,更多相关Python reset_index()内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python MAX内置函数详细介绍的相关资料,需要的朋友可以参考下2016-11-11
这篇文章主要介绍了Python MAX内置函数详细介绍的相关资料,需要的朋友可以参考下2016-11-11
Python实现将通信达.day文件读取为DataFrame
今天小编就为大家分享一篇Python实现将通信达.day文件读取为DataFrame,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12 这篇文章主要介绍了Python 结合opencv实现图片截取和拼接代码实践,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-09-09
这篇文章主要介绍了Python 结合opencv实现图片截取和拼接代码实践,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-09-09 这篇文章主要为大家详细介绍了适合初学者学习的Python3银行账户登录系统,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-08-08
这篇文章主要为大家详细介绍了适合初学者学习的Python3银行账户登录系统,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-08-08
浅谈pytorch torch.backends.cudnn设置作用
今天小编就为大家分享一篇浅谈pytorch torch.backends.cudnn设置作用,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02 隐写术是在任何文件中隐藏秘密数据的艺术。隐写术的主要目的是隐藏任何文件中的预期信息,而不实际改变文件的外观,即文件外观看起来和以前一样。本文将利用Python实现隐藏图像中的数据,需要的可以参考一下2022-02-02
隐写术是在任何文件中隐藏秘密数据的艺术。隐写术的主要目的是隐藏任何文件中的预期信息,而不实际改变文件的外观,即文件外观看起来和以前一样。本文将利用Python实现隐藏图像中的数据,需要的可以参考一下2022-02-02
Matlab中的mat数据转成python中使用的npy数据遇到的坑及解决
这篇文章主要介绍了Matlab中的mat数据转成python中使用的npy数据遇到的坑及解决,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-12-12
pycharm中如何自定义设置通过“ctrl+滚轮”进行放大和缩小实现方法
这篇文章主要介绍了pycharm中如何自定义设置通过“ctrl+滚轮”进行放大和缩小实现方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-09-09 这篇文章主要介绍了Python中is和==的区别,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-03-03
这篇文章主要介绍了Python中is和==的区别,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-03-03 subeprocess模块是python自带的模块,无需安装,主要用来取代一些就的模块或方法,本文通过实例代码给大家分享Python执行外部命令subprocess及使用方法,感兴趣的朋友跟随小编一起看看吧2021-05-05
subeprocess模块是python自带的模块,无需安装,主要用来取代一些就的模块或方法,本文通过实例代码给大家分享Python执行外部命令subprocess及使用方法,感兴趣的朋友跟随小编一起看看吧2021-05-05










最新评论