

 Codapp 外卖点餐系统 v1.0.0
Codapp 外卖点餐系统 v1.0.012.6MB / 06-21
 FocusAny专注高效的AI工具条 v0.8.0
FocusAny专注高效的AI工具条 v0.8.02.4MB / 12-28
 LinkAndroid 全能手机连接助手 v0.6.0
LinkAndroid 全能手机连接助手 v0.6.024.6MB / 03-15
 PESCMS RENT房租管理系统 v1.0.0
PESCMS RENT房租管理系统 v1.0.0104KB / 11-16
 ECHO个人博客主题网页模板 v1.0
ECHO个人博客主题网页模板 v1.015.1MB / 08-25
 优雅草便民tools工具 v1.0.6
优雅草便民tools工具 v1.0.61.25MB / 05-01
 抖音热门短剧在线搜索引擎 v1.0
抖音热门短剧在线搜索引擎 v1.0911KB / 03-20
 名扬银河企业建站源码 v2.0.2
名扬银河企业建站源码 v2.0.26.7MB / 03-19
 AGECMS商业会云管理_电子名片 v1.0.1
AGECMS商业会云管理_电子名片 v1.0.194KB / 03-13
 帝国cms看雪时间轴博客趣静态模板 v1.0
帝国cms看雪时间轴博客趣静态模板 v1.04.23MB / 02-02










-
后端开发配合elementui组件实现后端功能 其它源码 / 10.6MB
-

NocoBase开源无代码开发平台 v1.8.0 其它源码 / 5.7MB
-
ionic HTML5 移动应用框架 v8.6.2 其它源码 / 75.79MB
-
FastAPI高性能Web框架 v0.115.14 其它源码 / 4.6MB
-
kubernetes生产级别的容器编排系统 v1.33.2 其它源码 / 23.2MB
-
Apache Superset数据探查与可视化平台 v5.0.0 其它源码 / 89.2MB
-
Django Web框架 v4.2.23 其它源码 / 7.8MB
-
Django Web框架 v5.2.3 其它源码 / 7.1MB
-
PeaZip源码包 v10.5.0 其它源码 / 41.4MB
-

Gogs轻量级git服务 v0.13.3 其它源码 / 11.2MB









详情介绍
Horovod是针对TensorFlow,Keras,PyTorch和Apache MXNet的分布式深度学习培训框架。Horovod的目标是使分布式深度学习快速且易于使用。
Horovod由LF AI和数据基金会(LF AI&Data)托管。如果您是一家致力于在人工智能,机器和深度学习中使用开源技术的公司,并希望在这些领域中支持开源项目的社区,请考虑加入LF AI和数据基金会。有关谁参与以及Horovod如何扮演角色的详细信息,请阅读Linux Foundation公告。
安装
要安装Horovod:
1、安装CMake
2、如果您已从PyPI安装TensorFlow ,请确保已安装g++-4.8.5或g++-4.9或更高版本。
如果您已从PyPI安装了PyTorch ,请确保已安装g++-4.9或更高版本。
如果您已经从Conda安装了任何一个软件包,请确保gxx_linux-64已安装Conda软件包。
3、安装horovodpip包。
要在CPU上运行:
$ pip install horovod
要在具有NCCL的GPU上运行:
$ HOROVOD_GPU_OPERATIONS = NCCL点安装horovod
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovod
用法
要使用Horovod,请在程序中添加以下内容:
1、运行hvd.init()以初始化Horovod。
2、将每个GPU固定到一个进程,以避免资源争用。
通常每个进程设置一个GPU,将其设置为local rank。服务器上的第一个进程将被分配第一个GPU,第二个进程将被分配第二个GPU,依此类推。
3、通过工人人数来衡量学习率。
同步分布式培训中的有效批处理规模是根据工人人数来衡量的。学习率的提高弥补了批量大小的增加。
4、将优化器包装在中hvd.DistributedOptimizer。
分布式优化器将梯度计算委托给原始优化器,使用allreduce或allgather对梯度求平均,然后应用这些平均梯度。
5、将等级0的初始变量状态广播到所有其他进程。
当使用随机权重开始训练或从检查点恢复训练时,这是确保所有工人进行一致初始化的必要步骤。
6、修改您的代码以仅在工作程序0上保存检查点,以防止其他工作程序破坏它们。
使用TensorFlow v1的示例(有关完整的培训示例,请参阅示例目录):
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
运行Horovod
下面的示例命令显示了如何运行分布式训练。有关更多详细信息,请参见Run Horovod,包括RoCE / InfiniBand调整和处理挂起的技巧。
1、要在具有4个GPU的计算机上运行:
$ horovodrun -np 4 -H localhost:4 python train.py
2、要在具有4个GPU的4台计算机上运行:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
3、要在不使用horovodrun包装的情况下使用Open MPI运行,请参阅使用Open MPI运行Horovod。
4、要在Docker中运行,请参阅Docker中的Horovod。
5、要在Kubernetes中运行,MPI运算符,Helm Chart,FfDL和Polyaxon。
6、要在Spark上运行。
7、要在Ray上运行。
8、在Singularity运行
9、要在LSF HPC集群(例如Summit)中运行
下载地址
人气源码



相关文章
-
Codapp 外卖点餐系统 v1.0.0
Codapp 外卖点餐系统是一款专为快餐店、奶茶店、咖啡店、糕点店等商户打造的 H5 移动点餐解决方案,支持自提与外卖两种模式,可快速部署上线使用,欢迎需要的朋友下载使用...
-
FocusAny专注高效的AI工具条 v0.8.0
FocusAny 是一个专注高效的AI工具条,可以使用 Alt / Option+空格 一键唤起,通过插件快速安装,可以扩展出非常多的功能,欢迎需要的朋友下载使用...
-
LinkAndroid 全能手机连接助手 v0.6.0
LinkAndroid是一个轻松连接安卓与电脑,畅享投屏、文件管理、应用管理、截屏、录屏、安装应用等一站式便捷体验,让工作更高效!欢迎需要的朋友下载使用...
-
PESCMS RENT房租管理系统 v1.0.0
PESCMS RENT(下称PR)是一款基于GPLv2协议发布的开源房租管理系统,程序基于Golang + VUE3编写,欢迎需要的朋友下载使用...
-
ECHO个人博客主题网页模板 v1.0
ECHO个人主题网页模板是一款适合个人图文写作与博客的主题。主题极简优雅,采用经典独特的三栏设计,保留线条和足够的留白,展现您文字、图片间的美...
-
优雅草便民tools工具 v1.0.6
优雅草便民工具--便民tools工具tools-前端已接数据,优雅草小工具-数据来自优雅草api赋能-优雅草便民工具是一款由成都市一颗优雅草科技有限公司打造的便民查询公益工具,欢...
-
抖音热门短剧在线搜索引擎 v1.0
一个非常哇塞的在线短剧搜索页面,接口已经对接好了,上传源码到服务器解压就能直接用,有能力的可以自己改接口自己写自己的接口...
-
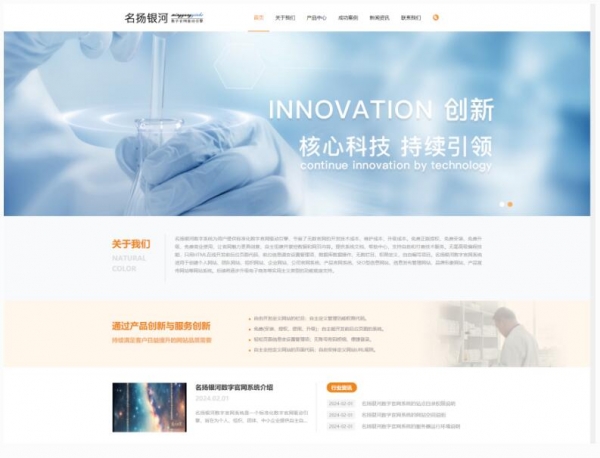
名扬银河企业建站源码 v2.0.2
名扬银河企业建站系统,适用于无代码基础的新手,快速搭建企业网站,程序内置了多项实用功能及插件,能够便捷的对网站进行修改、调整、优化等方面进行操作...
-
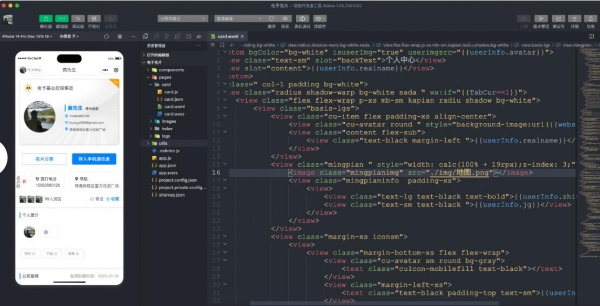
AGECMS商业会云管理_电子名片 v1.0.1
AGECMS商业会云管理电子名片是一款专为商务人士设计的全方位互动电子名片软件。它结合了现代商务交流的便捷性与高效性,通过数字化的方式,欢迎需要的朋友下载使用...
-
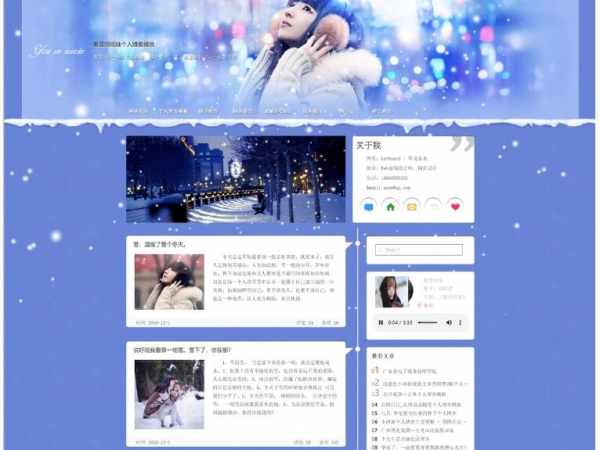
帝国cms看雪时间轴博客趣静态模板 v1.0
帝国cms看雪时间轴博客趣静态模板是一款女生唯美简洁个人博客静态页面模板,蓝色时间轴个人网页模板,下雪空间个人模板,喜欢的网友可以用开源程序帝国cms标签仿站建设...
下载声明
☉ 解压密码:www.jb51.net 就是本站主域名,希望大家看清楚,[ 分享码的获取方法 ]可以参考这篇文章
☉ 推荐使用 [ 迅雷 ] 下载,使用 [ WinRAR v5 ] 以上版本解压本站软件。
☉ 如果这个软件总是不能下载的请在评论中留言,我们会尽快修复,谢谢!
☉ 下载本站资源,如果服务器暂不能下载请过一段时间重试!或者多试试几个下载地址
☉ 如果遇到什么问题,请评论留言,我们定会解决问题,谢谢大家支持!
☉ 本站提供的一些商业软件是供学习研究之用,如用于商业用途,请购买正版。
☉ 本站提供的Horovod分布式深度学习框架 v0.28.1资源来源互联网,版权归该下载资源的合法拥有者所有。