
解读pandas交叉表与透视表pd.crosstab()和pd.pivot_table()函数
更新时间:2023年09月13日 09:25:13 作者:learning-striving
这篇文章主要介绍了pandas交叉表与透视表pd.crosstab()和pd.pivot_table()函数的用法,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
一、交叉表
交叉表:用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表),pd.crosstab(value1, value2)
pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False)
计算两个(或多个)因子的简单交叉制表。 默认情况下, 计算因子的频率表,除非传递值数组和聚合函数
index:类似数组、系列或数组/系列值的列表,行中分组依据的值columns:类似数组、系列或数组/系列值的列表,列中要作为分组依据的值values:类似数组,可选,要根据因素聚合的值数组,需要指定 aggfuncrownames:序列,默认 None ,如果传递,必须匹配传递的行数组的数量colnames:序列,默认 None ,如果传递,必须匹配传递的列数组的数量aggfunc:function,可选,如果指定,则还需要指定值margins:bool, 默认False 添加行/列边距(小计)margins_name:str,默认为“All”,当边距为 True 时将包含总计的行/列的名称dropna:bool, 默认为True,不包含条目均为 NaN 的列normalize:bool, {‘all’, ‘index’, ‘columns’}, or {0,1}, 默认为False,通过将所有值除以值的总和来归一化
“all”或 True:将对所有值进行归一化
index:将对每一行进行归一化
columns:将对每一列进行归一化
若margins 为 True,也将标准化边距值
- 返回:数据的 DataFrame 交叉表
传递的任何 Series 都将使用其名称属性,除非指定了交叉表的行或列名称。
传递的任何包含分类数据的输入都将在交叉表中包含其所有类别,即使实际数据不包含特定类别的任何实例也是如此。
如果没有重叠索引,将返回一个空的 DataFrame
a = np.array(["foo", "foo", "foo", "foo", "bar", "bar", "bar", "bar", "foo", "foo", "foo"], dtype=object) b = np.array(["one", "one", "one", "two", "one", "one", "one", "two", "two", "two", "one"], dtype=object) c = np.array(["dull", "dull", "shiny", "dull", "dull", "shiny", "shiny", "dull", "shiny", "shiny", "dull"], dtype=object) pd.crosstab(a, [b, c], rownames=['a'], colnames=['b', 'c']) ----------------------------------------------------------------------------------------- # 算数运算,先求和 sum = count.sum(axis=1) sum ------------------------------------- # 进行相除操作,得出比例 pro = count.div(sum, axis=0) pro ------------------------------------- import matplotlib.pyplot as plt pro.plot(kind='bar', stacked=True) plt.show()
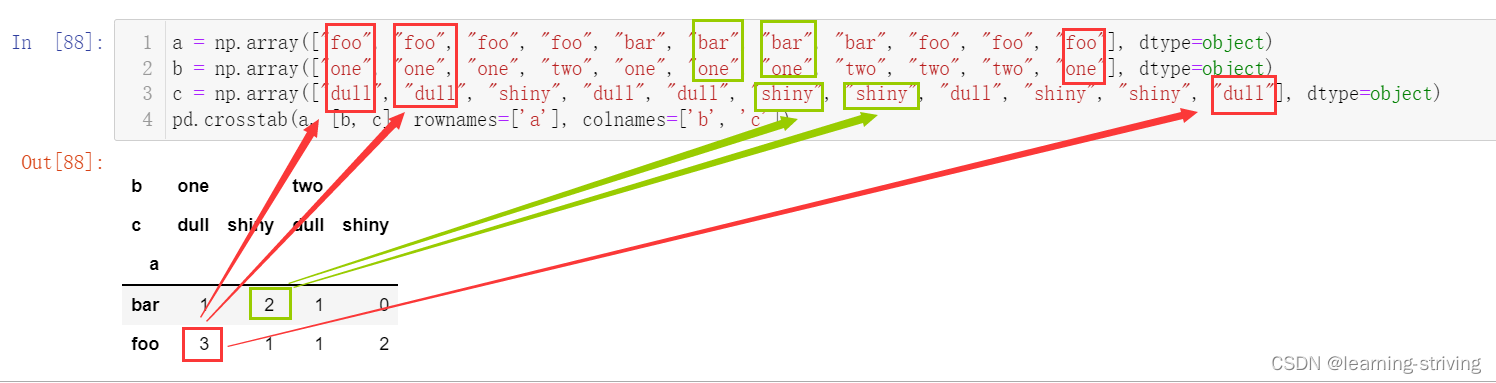
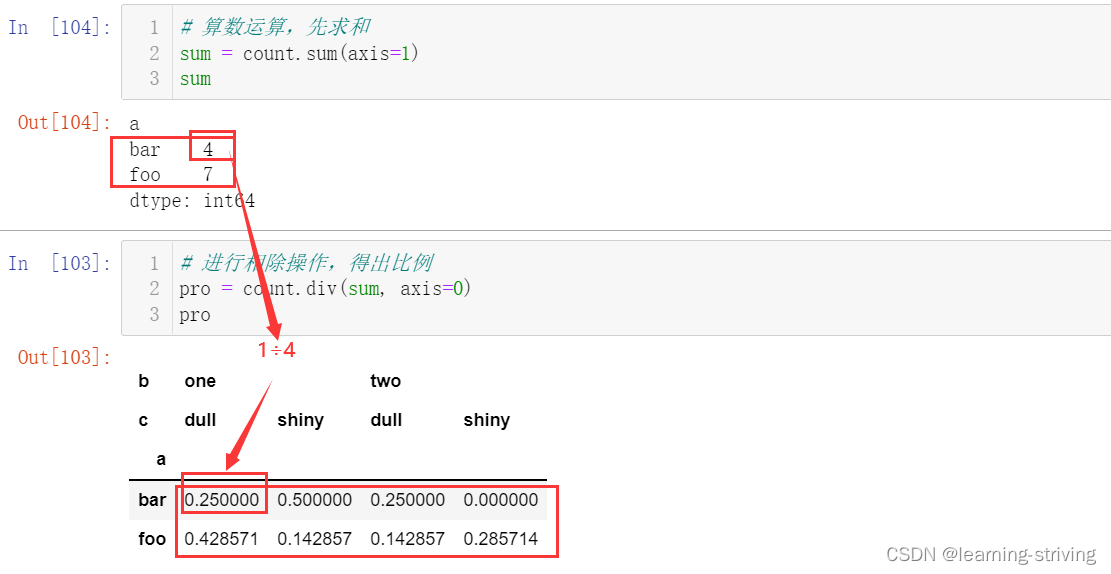
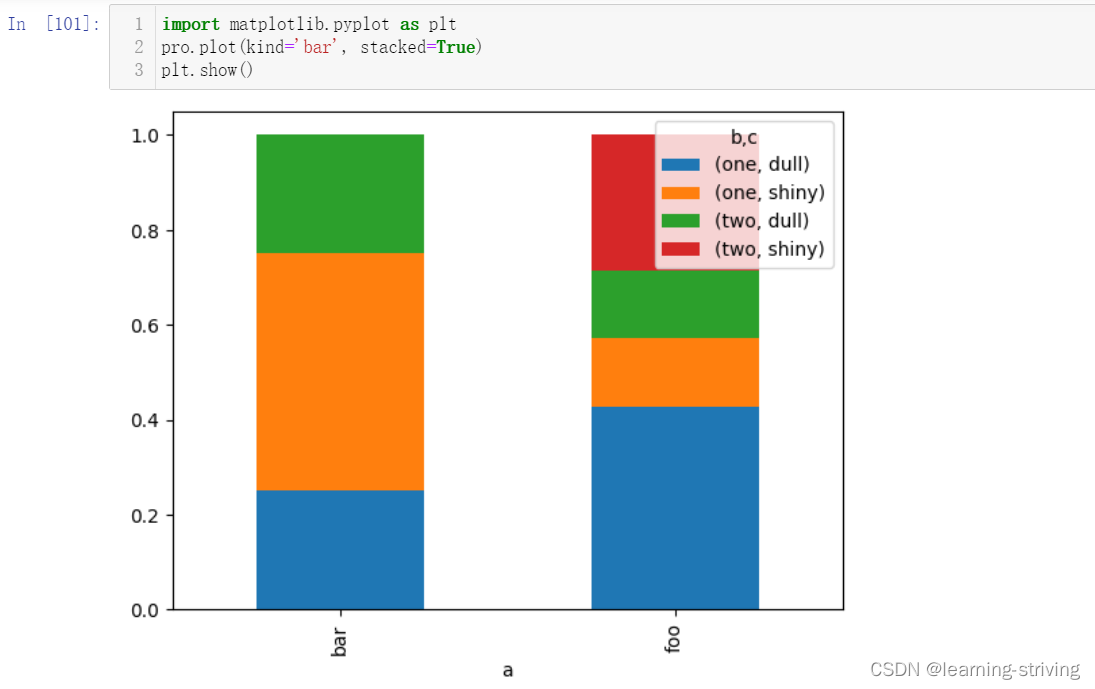
二、透视表
透视表:透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数,是一种可以对数据动态排布并且分类汇总的表格格式
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
创建一个电子表格样式的数据透视表作为 DataFrame。数据透视表中的级别将存储在结果 DataFrame 的索引和列上的 MultiIndex 对象(分层索引)中
values:要聚合的列,可选,默认对所有列操作index:column, Grouper, array, or list of the previous 如果传递数组,它必须与数据的长度相同。该列表可以包含任何其他类型(列表除外)。在数据透视表索引上分组的键。如果传递一个数组,它的使用方式与列值相同column:column, Grouper, array, or list of the previous 如果传递一个数组,它必须和数据一样长。该列表可以包含任何其他类型(列表除外)。在数据透视表列上分组的键。如果传递一个数组,它的使用方式与列值相同aggfunc:function, list of functions, dict, 默认为numpy.mean 如果传递函数列表,则生成的数据透视表将具有分层列,其顶层是函数名称(从函数对象本身推断)如果传递dict,则键是列聚合和值是函数或函数列表fill_value:scalar,默认 None 用于替换缺失值的值(在聚合后的结果数据透视表中)margins:bool, 默认False 添加所有行/列(例如小计/总计)dropna:bool, 默认为True,不包含条目均为 NaN 的列。如果为 True,则在计算边距之前将忽略任何列中具有 NaN 值的行margins_name:str,默认为“All” 当边距为 True 时将包含总计的行/列的名称observed:bool,默认为 False 这仅适用于任何groupers 是分类的。若为True:仅显示分类groupers 的观察值。否则显示分类groupers 的所有值。sort:bool, default True 指定结果是否应该排序- 返回 DataFrame:Excel 样式的数据透视表
代码如下
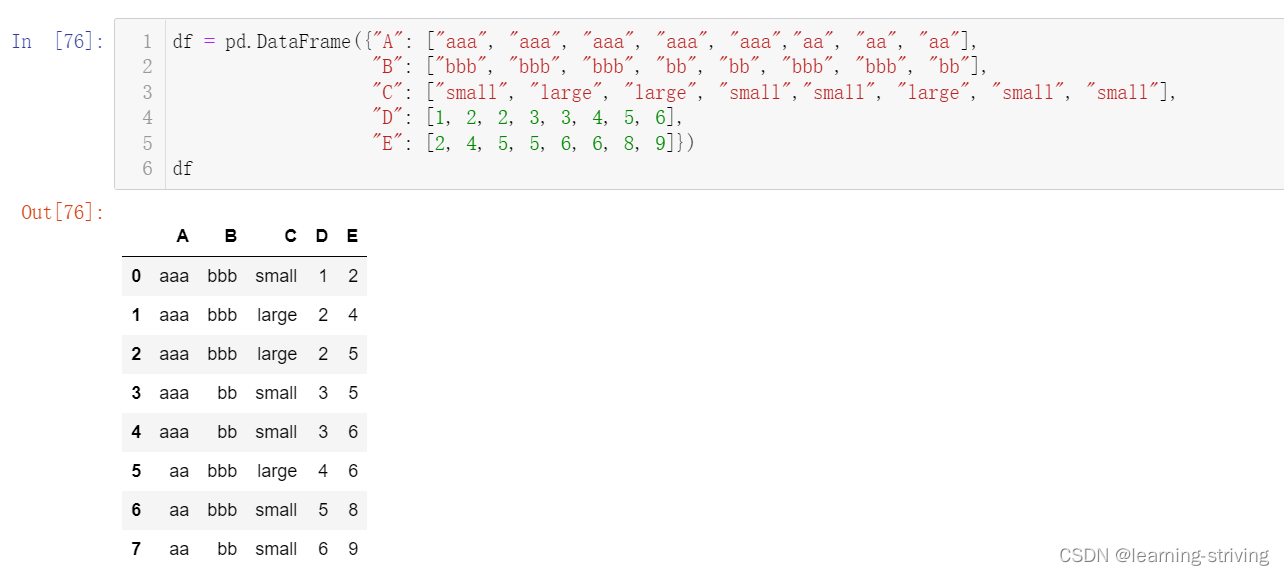
df = pd.DataFrame({"A": ["aaa", "aaa", "aaa", "aaa", "aaa","aa", "aa", "aa"],
"B": ["bbb", "bbb", "bbb", "bb", "bb", "bbb", "bbb", "bb"],
"C": ["small", "large", "large", "small","small", "large", "small", "small"],
"D": [1, 2, 2, 3, 3, 4, 5, 6],
"E": [2, 4, 5, 5, 6, 6, 8, 9]})
df
---------------------------------------------------------------------------------------
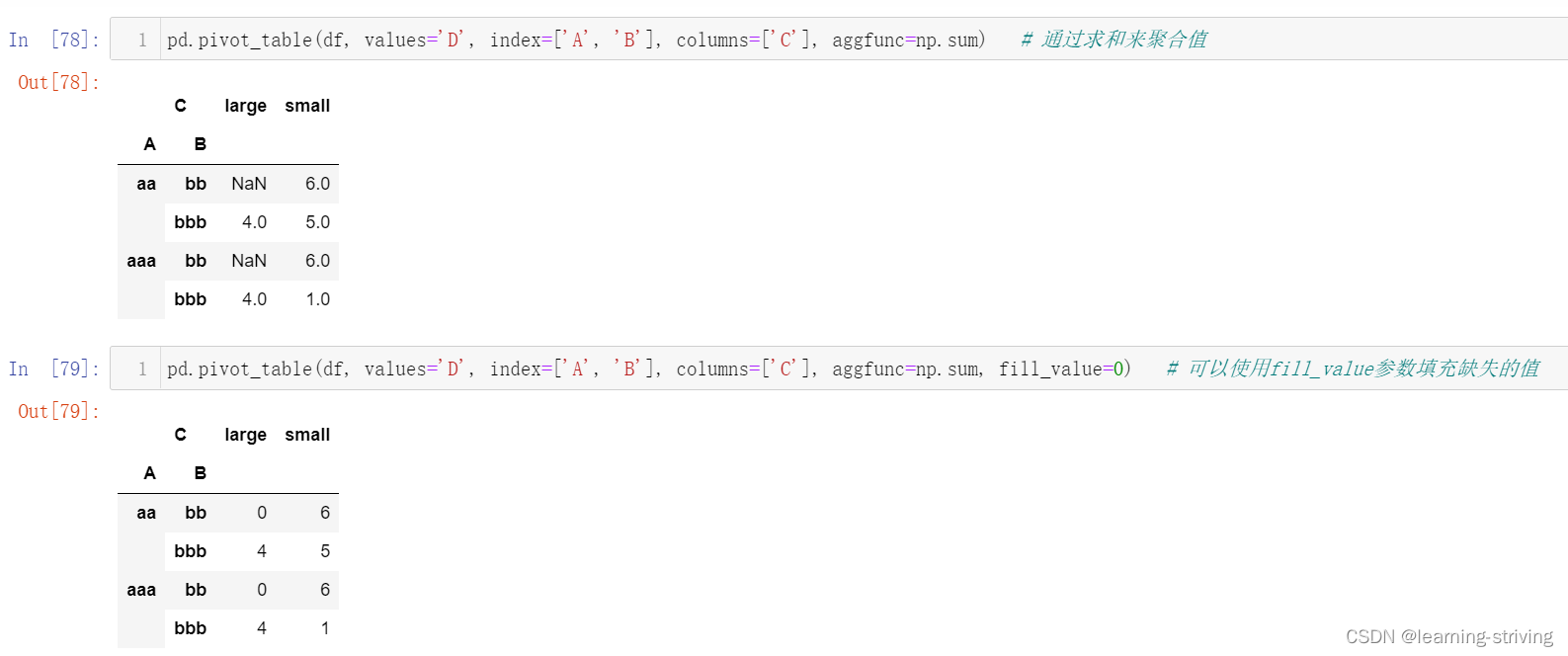
pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum) # 通过求和来聚合值
pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum, fill_value=0) # 可以使用fill_value参数填充缺失的值
pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'], aggfunc={'D': np.mean, 'E': np.mean}) # 通过对多个列取平均值进行聚合
pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'], aggfunc={'D': np.mean, 'E': [min, max, np.mean]}) # 可以为任何给定值列计算多种类型的聚合操作演示如下

总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章

解决Jupyter Notebook开始菜单栏Anaconda下消失的问题
这篇文章主要介绍了解决Jupyter Notebook开始菜单栏Anaconda下消失的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-04-04 这篇文章主要介绍了Python numpy数组转置与轴变换,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了Python numpy数组转置与轴变换,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11 本文主要介绍了numpy中轴处理的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03
本文主要介绍了numpy中轴处理的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03 这篇文章主要介绍了Python爬取并下载《电影天堂》3千多部电影,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-04-04
这篇文章主要介绍了Python爬取并下载《电影天堂》3千多部电影,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-04-04 这篇文章主要介绍了python中如何让输出不换行问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
这篇文章主要介绍了python中如何让输出不换行问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05 本文通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地,需要的朋友可以参考下2015-10-10
本文通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地,需要的朋友可以参考下2015-10-10 OpenCV(Open Source Computer Vision Library)作为一个强大的计算机视觉库,提供了丰富的图像处理和计算机视觉功能,本文将带领读者使用Python编程语言,通过简单的代码示例,初步掌握OpenCV的图像处理技术,需要的朋友可以参考下2024-09-09
OpenCV(Open Source Computer Vision Library)作为一个强大的计算机视觉库,提供了丰富的图像处理和计算机视觉功能,本文将带领读者使用Python编程语言,通过简单的代码示例,初步掌握OpenCV的图像处理技术,需要的朋友可以参考下2024-09-09 本文介绍了一个用于Windows系统设置文件默认打开程序的Python工具,通过命令行和注册表两种方式修改关联,适用于Windows7/10/11,代码包括设置默认程序、兼容性处理和验证功能,并提供了使用示例,需要的朋友可以参考下2026-01-01
本文介绍了一个用于Windows系统设置文件默认打开程序的Python工具,通过命令行和注册表两种方式修改关联,适用于Windows7/10/11,代码包括设置默认程序、兼容性处理和验证功能,并提供了使用示例,需要的朋友可以参考下2026-01-01 本文是一个简单教程,主要介绍了如何使用OCR进行文档解析以及使用Layoutpars软件包进行了整个检测和提取过程,感兴趣的可以了解一下2022-09-09
本文是一个简单教程,主要介绍了如何使用OCR进行文档解析以及使用Layoutpars软件包进行了整个检测和提取过程,感兴趣的可以了解一下2022-09-09 这篇文章主要介绍了pymongo给mongodb创建索引的简单实现方法,涉及Python使用pymongo模块操作mongodb的技巧,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了pymongo给mongodb创建索引的简单实现方法,涉及Python使用pymongo模块操作mongodb的技巧,需要的朋友可以参考下2015-05-05










最新评论