
python pandas最常用透视表实现应用案例
pandas包实现透视表的功能
透视表是一种可以对数据动态排布并且分类汇总的表格格式,它在数据分析中有着重要的作用和地位。在本文中,我将为你介绍python中如何使用pandas包实现透视表的功能,以及一些常见的应用案例。
导入pandas包
首先需要导入pandas包,它是一个提供了高性能数据结构和数据分析工具的python库,还需要导入numpy包,它是一个支持多维数组和矩阵运算的python库。可以使用以下代码来导入这两个包:
import pandas as pd import numpy as np
pandas读取一个excel文件中的数据
接下来,准备一些数据来演示透视表的功能,可以使用pandas的read_excel函数来读取一个excel文件中的数据,也可以使用DataFrame函数来创建一个数据框对象。例如,可以使用以下代码来创建一个包含了商品名称、代理商、价格和时间的数据框:
data = pd.DataFrame({
'商品名称': ['苹果', '香蕉', '橘子', '苹果', '香蕉', '橘子', '苹果', '香蕉', '橘子'],
'代理商': ['张三', '李四', '王五', '张三', '李四', '王五', '张三', '李四', '王五'],
'价格': [10, 5, 8, 12, 6, 9, 11, 7, 10],
'时间': ['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04', '2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08', '2021-01-09']
})我们可以使用data.head()函数来查看数据框的前五行:
data.head()
| | 商品名称 | 代理商 | 价格 | 时间 |
| - | ------- | ----- | --- | --------- |
| 0 | 苹果 | 张三 | 10 | 2021-01-01 |
| 1 | 香蕉 | 李四 | 5 | 2021-01-02 |
| 2 | 橘子 | 王五 | 8 | 2021-01-03 |
| 3 | 苹果 | 张三 | 12 | 2021-01-04 |
| 4 | 香蕉 | 李四 | 6 | 2021-01-05 |
pivot_table函数的语法
现在,我们可以使用pandas的pivot_table函数来创建一个透视表。pivot_table函数的基本语法如下:
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
其中,data是要进行透视表操作的数据框对象,values是要进行聚合运算的列名,index是要作为行索引的列名,columns是要作为列索引的列名,aggfunc是要进行聚合运算的函数,默认为求均值,切记,对于aggfunc,操作的是values后面的值,而不是columns后面的值。fill_value是要填充缺失值的值,默认为None,margins是是否添加行列汇总,默认为False,dropna是是否删除缺失值,默认为True,margins_name是汇总项的名称,默认为'All'。
pd.pivot_table(data, values='价格', index='商品名称', columns='代理商', aggfunc='mean', margins=True)
结果如下:
| | 张三 | 李四 | 王五 | All |
| ----- | ----- | ----- | ----- | ----- |
| 商品名称 | | | | |
| 苹果 | 11.00 | NaN | NaN | 11.00 |
| 香蕉 | NaN | 6.00 | NaN | 6.00 |
| 橘子 | NaN | NaN | 9.00 | 9.00 |
| All | 10.33 | 6.00 | 9.00 | 8.33 |
我们可以看到,透视表的行索引是商品名称,列索引是代理商,单元格的值是价格的均值,缺失值用NaN表示,行列汇总用All表示。
我们还可以使用其他的聚合函数,例如求和、计数、最大值、最小值等。我们也可以使用自定义的函数,例如求标准差、中位数等。我们只需要将aggfunc参数的值改为相应的函数即可。例如,如果我们想要按照商品名称和代理商分组,计算每组的价格总和,并且添加行列汇总,我们可以使用以下代码:
pd.pivot_table(data, values='价格', index='商品名称', columns='代理商', aggfunc='sum', margins=True)
结果如下:
| | 张三 | 李四 | 王五 | All |
| ----- | ----- | ----- | ----- | ----- |
| 商品名称 | | | | |
| 苹果 | 33 | NaN | NaN | 33 |
| 香蕉 | NaN | 18 | NaN | 18 |
| 橘子 | NaN | NaN | 27 | 27 |
| All | 33 | 18 | 27 | 78 |
我们可以看到,透视表的行索引是商品名称,列索引是代理商,单元格的值是价格的总和,缺失值用NaN表示,行列汇总用All表示。
应用案例
案例一:使用多个值和多个索引
使用以下代码来创建一个透视表,显示每个性别和年龄段的身高和体重的最大值,最小值和平均值:
import pandas as pd
import numpy as np
df = pd.DataFrame({
"name": ["Alice", "Bob", "Charlie", "David", "Eve", "Frank", "Grace", "Harry"],
"gender": ["F", "M", "M", "M", "F", "M", "F", "M"],
"age": [16, 30, 12, 32, 27, 29, 15, 31],
"height": [165, 175, 180, 170, 160, 182, 168, 178],
"weight": [55, 70, 75, 68, 50, 72, 54, 69]
})
df_pivot = pd.pivot_table(df, values=["height","weight"], index="gender",
aggfunc=['mean','max','min'])
print(df_pivot)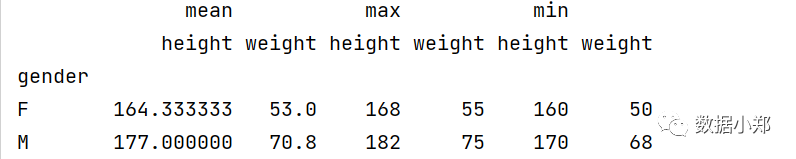
案例二:使用自定义函数的透视表
使用以下代码来创建一个透视表,显示每个性别的体重的平均值、身高的方差、未成年的计数:
import pandas as pd
import numpy as np
df = pd.DataFrame({
"name": ["Alice", "Bob", "Charlie", "David", "Eve", "Frank", "Grace", "Harry"],
"gender": ["F", "M", "M", "M", "F", "M", "F", "M"],
"age": [16, 30, 12, 32, 27, 29, 15, 31],
"height": [165, 175, 180, 170, 160, 182, 168, 178],
"weight": [55, 70, 75, 68, 50, 72, 54, 69]
})
def count_cld(col:pd.core.frame.Series):
# col 是 Series ,每一组的数据在一起
n = 0
for i in col:
if i < 18:
n=n+1
return n
df_pivot = pd.pivot_table(df, values=["height","weight","age"], index="gender",
aggfunc={ "weight": np.mean, "height":np.std,"age":count_cld})
print(df_pivot)
以上就是python pandas最常用透视表实现应用案例的详细内容,更多关于python pandas透视表的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要介绍了使用wxpython实现的一个简单图片浏览器实例,根据自己的特殊需求而写,需要的朋友可以参考下2014-07-07
这篇文章主要介绍了使用wxpython实现的一个简单图片浏览器实例,根据自己的特殊需求而写,需要的朋友可以参考下2014-07-07 对于exe可执行文件,相信大家都不陌生,下面这篇文章主要给大家介绍了关于如何使python变为可执行文件的相关资料,文中通过图文介绍的非常详细,需要的朋友可以参考下2023-02-02
对于exe可执行文件,相信大家都不陌生,下面这篇文章主要给大家介绍了关于如何使python变为可执行文件的相关资料,文中通过图文介绍的非常详细,需要的朋友可以参考下2023-02-02
Python 中PyQt5 点击主窗口弹出另一个窗口的实现方法
这篇文章主要介绍了Python 中PyQt5 点击主窗口弹出另一个窗口的实现方法,本文代码实例图文相结合的形式给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-07-07 今天小编就为大家分享一篇对pycharm 修改程序运行所需内存详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
今天小编就为大家分享一篇对pycharm 修改程序运行所需内存详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
Python ArcPy实现批量计算多时相遥感影像的各项元平均值
这篇文章主要为大家详细介绍了如何基于Python中ArcPy模块,实现对大量长时间序列栅格遥感影像文件的每一个像元进行多时序平均值的求取,感兴趣的可以了解一下2023-04-04
Python使用Spire.XLS for Python轻松实现Excel转PDF的完整指南
在日常办公和数据处理中,我们经常需要将 Excel 文档转换为 PDF 格式,今天我们将介绍如何使用 Spire.XLS for Python 库来实现 Excel 到 PDF 的高效转换,有需要的可以了解下2025-10-10 这篇文章主要为大家详细介绍了如何基于Python实现简单的微信通知和预警功能,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2025-12-12
这篇文章主要为大家详细介绍了如何基于Python实现简单的微信通知和预警功能,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2025-12-12
pytorch 在sequential中使用view来reshape的例子
今天小编就为大家分享一篇pytorch 在sequential中使用view来reshape的例子,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08 这篇文章主要为大家介绍了如何利用Python实现将Excel表格内容批量导出为PDF文件,文中的实现步骤讲解详细,感兴趣的小伙伴可以了解一下2022-04-04
这篇文章主要为大家介绍了如何利用Python实现将Excel表格内容批量导出为PDF文件,文中的实现步骤讲解详细,感兴趣的小伙伴可以了解一下2022-04-04
Django执行python manage.py makemigrations报错的解决方案分享
相信用过很多Django makemigrations的人都会遇到过makemigrations时会发生报错,下面这篇文章主要给大家介绍了关于Django执行python manage.py makemigrations报错的解决方案,需要的朋友可以参考下2022-09-09










最新评论