
浅谈实时计算框架Flink集群搭建与运行机制
一、Flink概述
1.1、基础简介
主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink不仅可以运行在包括YARN、Mesos、Kubernetes在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。

这里要说明两个概念:
- 边界:无边界和有边界数据流,可以理解为数据的聚合策略或者条件;
- 状态:即执行顺序上是否存在依赖关系,即下次执行是否依赖上次结果;
1.2、应用场景
Data Driven

事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞吐和更低的延迟,以反欺诈案例来看,DataDriven把处理的规则模型写到DatastreamAPI中,然后将整个逻辑抽象到Flink引擎,当事件或者数据流入就会触发相应的规则模型,一旦触发规则中的条件后,DataDriven会快速处理并对业务应用进行通知。
Data Analytics

和批量分析相比,由于流式分析省掉了周期性的数据导入和查询过程,因此从事件中获取指标的延迟更低。不仅如此,批量查询必须处理那些由定期导入和输入有界性导致的人工数据边界,而流式查询则无须考虑该问题,Flink为持续流式分析和批量分析都提供了良好的支持,实时处理分析数据,应用较多的场景如实时大屏、实时报表。
Data Pipeline
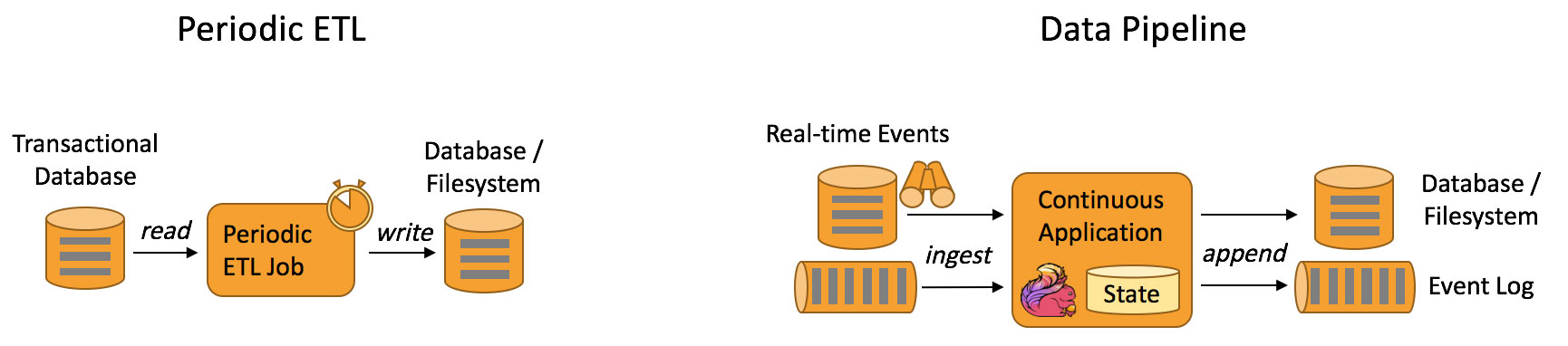
与周期性的ETL作业任务相比,持续数据管道可以明显降低将数据移动到目的端的延迟,例如基于上游的StreamETL进行实时清洗或扩展数据,可以在下游构建实时数仓,确保数据查询的时效性,形成高时效的数据查询链路,这种场景在媒体流的推荐或者搜索引擎中十分常见。
二、环境部署
2.1、安装包管理
[root@hop01 opt]# tar -zxvf flink-1.7.0-bin-hadoop27-scala_2.11.tgz
[root@hop02 opt]# mv flink-1.7.0 flink1.7
2.2、集群配置
管理节点
[root@hop01 opt]# cd /opt/flink1.7/conf
[root@hop01 conf]# vim flink-conf.yaml
jobmanager.rpc.address: hop01
分布节点
[root@hop01 conf]# vim slaves
hop02
hop03
两个配置同步到所有集群节点下面。
2.3、启动与停止
/opt/flink1.7/bin/start-cluster.sh
/opt/flink1.7/bin/stop-cluster.sh
启动日志:
[root@hop01 conf]# /opt/flink1.7/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hop01.
Starting taskexecutor daemon on host hop02.
Starting taskexecutor daemon on host hop03.
2.4、Web界面
访问:http://hop01:8081/

三、开发入门案例
3.1、数据脚本
分发一个数据脚本到各个节点:
/var/flink/test/word.txt
3.2、引入基础依赖
这里基于Java写的基础案例。
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.7.0</version>
</dependency>
</dependencies>
3.3、读取文件数据
这里直接读取文件中的数据,经过程序流程分析出每个单词出现的次数。
public class WordCount {
public static void main(String[] args) throws Exception {
// 读取文件数据
readFile () ;
}
public static void readFile () throws Exception {
// 1、执行环境创建
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
// 2、读取数据文件
String filePath = "/var/flink/test/word.txt" ;
DataSet<String> inputFile = environment.readTextFile(filePath);
// 3、分组并求和
DataSet<Tuple2<String, Integer>> wordDataSet = inputFile.flatMap(new WordFlatMapFunction(
)).groupBy(0).sum(1);
// 4、打印处理结果
wordDataSet.print();
}
// 数据读取个切割方式
static class WordFlatMapFunction implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector){
String[] wordArr = input.split(",");
for (String word : wordArr) {
collector.collect(new Tuple2<>(word, 1));
}
}
}
}

3.4、读取端口数据
在hop01服务上创建一个端口,并模拟一些数据发送到该端口:
[root@hop01 ~]# nc -lk 5566
c++,java
通过Flink程序读取并分析该端口的数据内容:
public class WordCount {
public static void main(String[] args) throws Exception {
// 读取端口数据
readPort ();
}
public static void readPort () throws Exception {
// 1、执行环境创建
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取Socket数据端口
DataStreamSource<String> inputStream = environment.socketTextStream("hop01", 5566);
// 3、数据读取个切割方式
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputStream.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>()
{
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) {
String[] wordArr = input.split(",");
for (String word : wordArr) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0).sum(1);
// 4、打印分析结果
resultDataStream.print();
// 5、环境启动
environment.execute();
}
}
四、运行机制

4.1、FlinkClient
客户端用来准备和发送数据流到JobManager节点,之后根据具体需求,客户端可以直接断开连接,或者维持连接状态等待任务处理结果。
4.2、JobManager
在Flink集群中,会启动一个JobManger节点和至少一个TaskManager节点,JobManager收到客户端提交的任务后,JobManager会把任务协调下发到具体的TaskManager节点去执行,TaskManager节点将心跳和处理信息发送给JobManager。
4.3、TaskManager
任务槽(slot)是TaskManager中最小的资源调度单位,在启动的时候就设置好了槽位数,每个槽位能启动一个Task,接收JobManager节点部署的任务,并进行具体的分析处理。
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
以上就是浅谈实时计算框架Flink集群搭建与运行机制的详细内容,更多关于实时计算框架 Flink集群搭建与运行机制的资料请关注脚本之家其它相关文章!
相关文章
 Ubuntu 16.04发布了,带来了很多新特性,同样也依然带着很多不习惯的东西,所以装完系统后还要进行一系列的优化。本篇文章主要介绍了安装Ubuntu 16.04后要做的事,有兴趣的可以了解一下。2016-12-12
Ubuntu 16.04发布了,带来了很多新特性,同样也依然带着很多不习惯的东西,所以装完系统后还要进行一系列的优化。本篇文章主要介绍了安装Ubuntu 16.04后要做的事,有兴趣的可以了解一下。2016-12-12 文章介绍了操作系统中进程的状态,包括运行状态、阻塞状态和挂起状态,并详细解释了Linux下进程的具体状态及其管理,此外,文章还讨论了进程的优先级、查看和修改进程优先级的方法,以及并发相关的概念和函数的返回值2025-02-02
文章介绍了操作系统中进程的状态,包括运行状态、阻塞状态和挂起状态,并详细解释了Linux下进程的具体状态及其管理,此外,文章还讨论了进程的优先级、查看和修改进程优先级的方法,以及并发相关的概念和函数的返回值2025-02-02 这篇文章主要介绍了在服务器上启用HTTP公钥固定扩展的教程,示例包括对Apache和NGINX以及Lighttpd服务器的演示,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了在服务器上启用HTTP公钥固定扩展的教程,示例包括对Apache和NGINX以及Lighttpd服务器的演示,需要的朋友可以参考下2015-06-06 在本篇文章中我们给大家分享了Linux初始化系统盘后重新挂载数据盘的解决方法,有需要的朋友们可以参考下。2018-09-09
在本篇文章中我们给大家分享了Linux初始化系统盘后重新挂载数据盘的解决方法,有需要的朋友们可以参考下。2018-09-09 这篇文章主要介绍了关于linux中ssh超时自动登出时间的设置方法,以避免总是被强行退出。需要的朋友可以参考借鉴,下面来一起看看吧。2017-02-02
这篇文章主要介绍了关于linux中ssh超时自动登出时间的设置方法,以避免总是被强行退出。需要的朋友可以参考借鉴,下面来一起看看吧。2017-02-02 这篇文章主要介绍了Linux bzip2 命令的使用,帮助大家更好的理解和使用Linux系统,感兴趣的朋友可以了解下2020-08-08
这篇文章主要介绍了Linux bzip2 命令的使用,帮助大家更好的理解和使用Linux系统,感兴趣的朋友可以了解下2020-08-08 这篇文章主要介绍了linux引导系统的方法,总结分析了Linux引导系统相关原理、操作命令与注意事项,需要的朋友可以参考下2020-03-03
这篇文章主要介绍了linux引导系统的方法,总结分析了Linux引导系统相关原理、操作命令与注意事项,需要的朋友可以参考下2020-03-03
Nginx 0.7.x + PHP 5.2.6(FastCGI)+ MySQL 5.1 在128M小内存VPS服务器上的
VPS(全称Virtual Private Server)是利用最新虚拟化技术在一台物理服务器上创建多个相互隔离的虚拟私有主机。它们以最大化的效率共享硬件、软件许可证以及管理资源。2008-12-12 下面小编就为大家带来一篇RHEL 7中防火墙的配置和使用方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-12-12
下面小编就为大家带来一篇RHEL 7中防火墙的配置和使用方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-12-12 这篇文章主要介绍了从Centos7升级到Centos8的教程,在升级之前需要配置备份,本文通过图文并茂的形式给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友参考下吧2019-11-11
这篇文章主要介绍了从Centos7升级到Centos8的教程,在升级之前需要配置备份,本文通过图文并茂的形式给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友参考下吧2019-11-11










最新评论